Vibe Hacking:当LLM与Kali Linux相遇,重塑网络安全渗透测试的未来
1. 引言:网络安全的新篇章——迎接“氛围攻击”时代
1.1. 当前网络安全顾问面临的困境
在当今数字化的世界中,网络安全顾问与渗透测试专家正面临前所未有的压力。挑战主要源于三个方面:
- 人才短缺与技能鸿沟:能够执行复杂渗透测试的高级安全专家供不应求,其培养周期长、成本高昂,导致许多组织难以获得高质量的安全评估服务。
- 效率瓶颈:传统的渗透测试是一个劳动密集型过程,高度依赖人工操作。从信息收集、漏洞扫描到利用和报告撰写,每个环节都涉及繁琐的工具操作和重复性劳动,严重制约了测试的效率和规模。
- 动态威胁环境:攻击者的技术、战术和程序(TTPs)正以惊人的速度演进。防御方往往疲于奔命,难以跟上攻击手法日新月异的节奏,传统的手动测试方法显得愈发迟缓。
1.2. “Vibe Hacking”概念的提出
为了应对这些挑战,我们需要一种全新的范式。灵感来源于新兴的“Vibe Coding”(氛围编程)理念,它倡导将编程从“语法的工艺”转向“语意的创作”。开发者只需通过自然语言描述其高级意图,AI便能自动生成所需代码。
我们将这一理念借鉴到网络安全领域,正式提出 “Vibe Hacking”(氛围攻击) 的概念。
核心定义:Vibe Hacking是一种以自然语言为核心交互方式的渗透测试新范式。安全专家通过描述高层次的攻击目标与策略(The Vibe),由一个集成了大型语言模型(LLM)的智能体自主进行任务规划、工具调用、动态调整,并最终生成结构化报告。
其核心价值在于,将渗透测试专家从繁琐的命令行和工具配置中解放出来,使其能够专注于更高层次的战略规划、威胁建模与决策分析。这不仅是一次效率的飞跃,更是一场智能化的革命。
2. 核心概念解析:构建“Vibe Hacking”的四大基石
“Vibe Hacking”的实现并非空中楼阁,它建立在多项成熟技术的交叉融合之上。
2.1. 大型语言模型(LLM):智能决策的“大脑”
LLM凭借其强大的代码生成、自然语言理解和推理能力,成为Vibe Hacking智能体的“大脑”。在网络安全领域,LLM能够:
- 学习海量安全知识:通过对CVE漏洞库、Exploit-DB、安全报告和攻防技术的学习,LLM能模拟经验丰富的安全专家,用于漏洞发现、威胁情报分析和Payload生成。
- 赋能自动化任务:从编写扫描脚本到自动化生成专业的渗透测试报告,LLM为端到端的自动化流程提供了核心驱动力。
2.2. Vibe Coding:自然语言驱动的模式借鉴
“Vibe Coding”的技术理念是Vibe Hacking的直接灵感来源。其核心模式是将用户的自然语言“意图”转化为机器可执行的具体操作。
- 技术理念:用户表达高级目标,AI负责实现。开发者从代码的“执行者”转变为“协调者”。
- 渗透测试领域的转化:在Vibe Hacking中,这一模式被完美复刻。安全专家的高层次指令,如“对目标Web服务
example.com进行SQL注入和XSS漏洞测试,并尝试获取服务器访问权限”,将被AI智能体无缝转化为具体的工具调用序列和攻击步骤。
2.3. Kali Linux与MITRE ATT&CK框架:战略与战术的链接
如果LLM是“大脑”,那么Kali Linux和MITRE ATT&CK框架就是连接战略与行动的“武器库”和“战术手册”。
- Kali Linux工具箱:作为业界公认的渗透测试发行版,Kali Linux集成了数百种专业的安全工具(如Nmap, Metasploit, Burp Suite),构成了Veb Hacking的底层“武器库”。
- MITRE ATT&CK框架:这是一个全球公认的、基于真实世界观察的对手战术、技术和通用知识库。它为网络攻击行为提供了标准化的语言。
- 二者的关键链接:至关重要的是,Kali Linux已将其工具菜单结构与MITRE ATT&CK框架的战术阶段对齐。这意味着,AI智能体可以根据ATT&CK框架规划出的攻击阶段(如“初始访问”、“执行”、“持久化”),直接在Kali Linux中定位并调用相应的工具。这为从抽象战略到具体战术执行的自动化提供了可能。
3. “Vibe Hacking”的整合架构:从语言到行动的转化器
3.1. 核心架构设计
Vibe Hacking的实现依赖于一个分层式的智能代理架构,它如同一个精密的“转化器”,将安全专家的自然语言指令转化为精确的渗透测试行动。
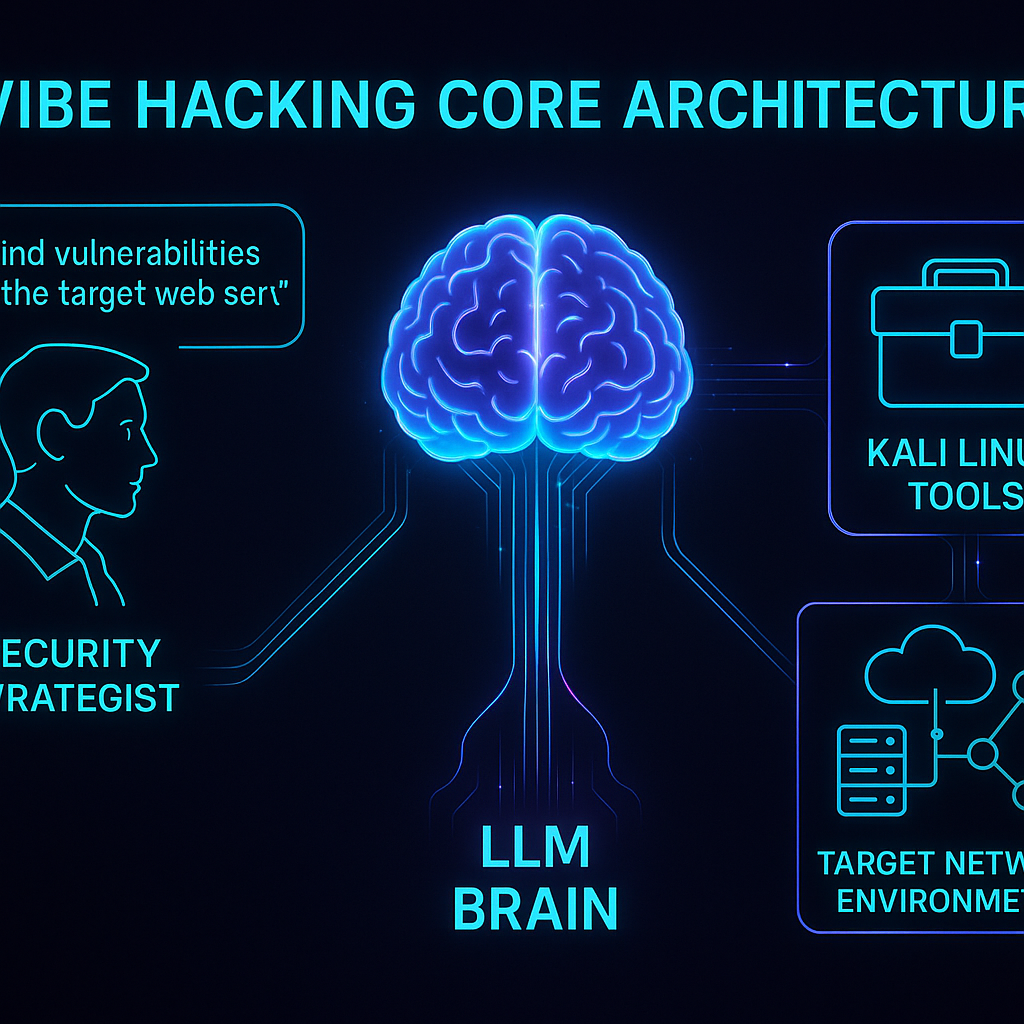
上图直观地展示了Vibe Hacking的核心架构。安全战略家通过自然语言下达指令,LLM大脑作为核心中枢进行解析和规划,并指挥底层的Kali Linux工具集对目标网络环境执行操作。
其具体架构可分为以下几个层次:
| 层次 | 模块/组件 | 主要功能 |
|---|---|---|
| 用户交互层 | 自然语言接口 (NLI) | 接收用户以自然语言输入的高层次渗透测试目标和指令,并以自然语言形式反馈结果。 |
| LLM核心/大脑层 | 1. 任务规划模块 2. 推理与决策模块 3. 知识增强模块 (RAG) | - 任务规划:将自然语言目标分解为基于MITRE ATT&CK框架的结构化任务树。 - 推理决策:实时分析工具反馈,动态调整攻击策略,例如在遇到WAF时生成绕过Payload。 - 知识增强:通过检索增强生成(RAG)技术,结合外部实时安全知识库(如CVEs、Exploit-DB),减少“幻觉”,提高决策的准确性。 |
| 工具编排与执行层 | 1. 工具封装接口 (API) 2. 命令生成与执行模块 | - 工具封装:为Kali Linux等工具集提供标准化的调用接口,屏蔽底层工具的复杂性。 - 命令生成与执行:将规划好的任务步骤翻译成具体工具的命令(如 nmap, metasploit),并在隔离环境(如Docker容器)中安全执行,防止对宿主机造成意外损害。 |
3.2. 架构工作原理
整个架构形成一个智能化的闭环反馈系统:
- 输入:用户通过自然语言接口输入高级指令。
- 规划:LLM核心层理解用户意图,将其分解为一系列基于ATT&CK框架的子任务。
- 执行:工具编排层将任务转化为具体命令,并调用相应的Kali Linux工具。
- 分析:执行结果返回至LLM核心层。
- 迭代:LLM分析结果,根据实时情况(如发现新端口、攻击被拦截等)动态调整后续计划,形成一个持续迭代、自我优化的闭环。
4. 工作流程详解:一次完整的“Vibe Hacking”渗透测试之旅
为了更清晰地理解Vibe Hacking的运作模式,让我们跟随一个典型的渗透测试任务,走完它的五步工作流程。
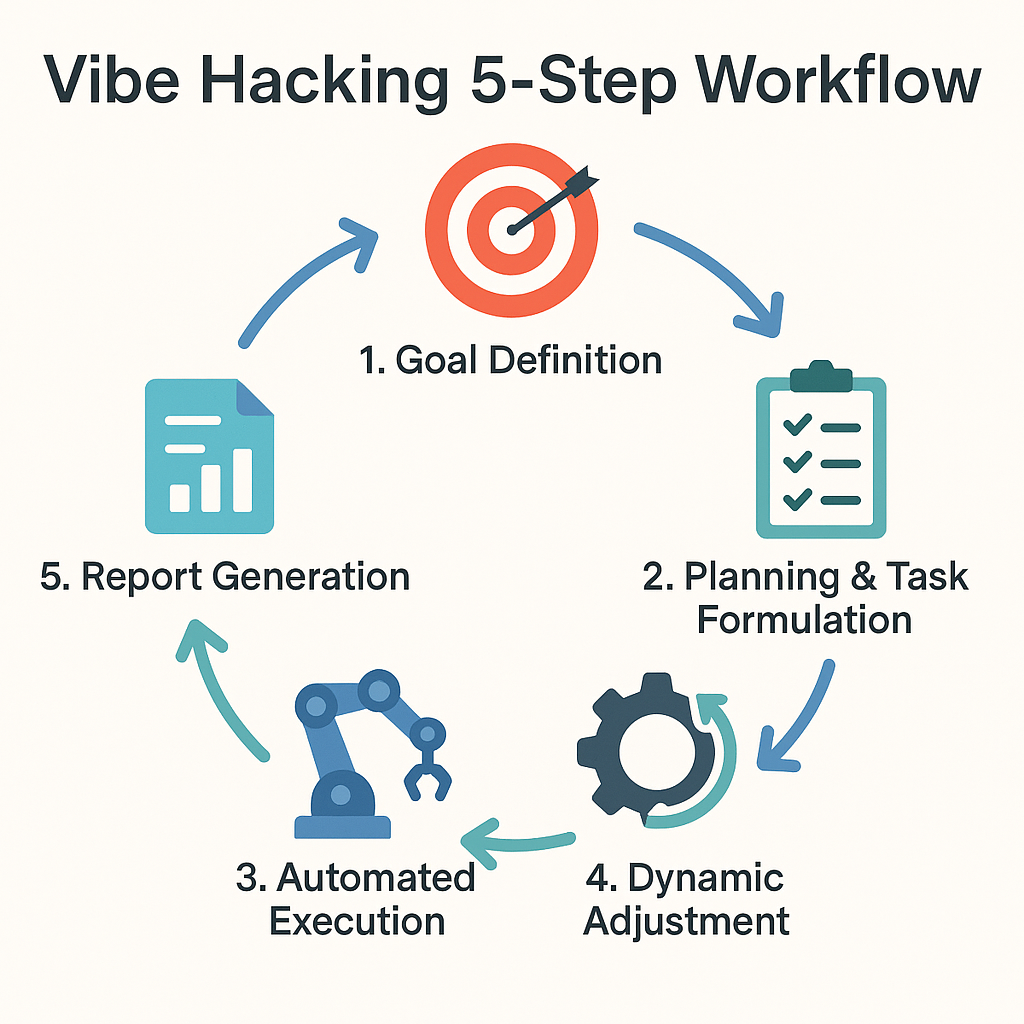
如上图所示,Vibe Hacking工作流是一个从目标定义到报告生成的完整循环,其中动态调整是确保其智能性的关键。
4.1. 第一步:目标定义与意图输入 (Goal Definition)
安全顾问向系统输入一个高层次的自然语言指令。
“评估
example.com的Web应用安全性,重点关注OWASP Top 10漏洞,并尝试获取服务器的Shell访问权限。”
4.2. 第二步:自动化规划与任务制定 (Planning & Task Formulation)
LLM智能体接收指令后,基于其内置的ATT&CK知识和渗透测试方法论,生成一份结构化的初步攻击计划:
- 侦察 (Reconnaissance):执行端口扫描、子域名枚举、识别目标Web服务器的技术栈(如Apache, PHP, MySQL)。
- 资源开发 (Resource Development) & 初始访问 (Initial Access):针对识别出的技术栈,扫描常见的Web应用漏洞,特别是SQL注入(SQLi)、跨站脚本(XSS)和远程代码执行(RCE)。
- 执行 (Execution) & 权限提升 (Privilege Escalation):若发现可利用的漏洞,则尝试利用该漏洞获取初始Shell,并进一步寻找提权路径。
4.3. 第三步:指令执行与工具调用 (Automated Execution)
架构的执行层将规划好的任务转化为精确的命令行指令,并调用Kali Linux工具箱中的工具:
- 执行侦察任务:bash
nmap -sV -p- example.com - 扫描SQL注入漏洞:bash
sqlmap -u "http://example.com/login" --batch --level=5 --risk=3 - 如果发现可利用漏洞,启动Metasploit进行利用:bash
msfconsole -x "use exploit/multi/http/apache_php_rce; set RHOSTS example.com; run"
4.4. 第四步:过程验证与动态调整 (Dynamic Adjustment)
这是Vibe Hacking区别于传统自动化脚本的核心。LLM持续分析工具的输出,并根据反馈动态调整策略:
- 场景A:新发现
nmap的输出显示一个不常见的端口8080正在运行Apache Tomcat服务。- LLM立即调整计划,增加针对Tomcat的已知漏洞扫描任务。
- 场景B:攻击成功
sqlmap报告成功发现一个SQL注入点,并能够执行操作系统命令。- LLM将后续任务的重心转向利用此注入点获取反向Shell,而不是继续扫描其他漏洞。
- 场景C:遭遇防御
- 对Web应用的攻击被WAF(Web应用防火墙)拦截。
- LLM识别出拦截日志,并尝试调用其知识库中关于WAF绕过的技术,生成混淆的Payload再次尝试攻击。
4.5. 第五步:结果分析与报告生成 (Report Generation)
渗透测试任务结束后,LLM整合整个过程中的所有发现、成功的攻击路径、收集的证据(如截图、日志)以及失败的尝试。最终,它会自动生成一份结构化、包含技术细节、风险评级和具体修复建议的专业渗透测试报告,将数小时甚至数天的人工撰写工作缩短至几分钟。
5. Vibe Hacking实践指南:连接LLM与Kali Linux
本节旨在提供一套将大型语言模型(LLM)的强大能力与Kali Linux中的渗透测试工具集成的实践方法。我们将探讨两种核心方案:本地化部署以保障数据隐私,以及云端API集成以利用最前沿的模型能力。
5.1. 方案一:本地化LLM部署与控制
此方案将LLM完全部署在您的本地计算机上,确保所有交互和数据(包括敏感的目标信息)都不会离开您的控制范围。这对于处理机密渗透测试项目至关重要。
5.1.1. 环境搭建:安装与配置Ollama
Ollama 是一个用户友好的工具,它极大地简化了在本地运行Llama、Mistral、Llama3等开源LLM的过程。它封装了Llama.cpp等底层库,提供简洁的CLI和REST API。
安装步骤:
- 下载并安装Ollama 访问 Ollama官网,根据您的操作系统(Linux, macOS, Windows)下载并执行安装程序。Linux用户通常可以使用以下命令:sh
curl -fsSL https://ollama.com/install.sh | sh - 拉取模型 选择一个适合代码和命令生成的模型。
llama3或codellama是不错的选择。sh# 拉取最新的Llama 3 8B指令模型 ollama pull llama3 # 或者拉取专门为代码优化的Code Llama模型 ollama pull codellama - 运行并验证 在终端直接与模型交互,以确认安装成功。shOllama服务会在后台自动启动,并监听
ollama run llama3http://localhost:11434。
5.1.2. 交互脚本:通过Python与本地LLM通信
我们可以编写一个Python脚本,通过Ollama提供的REST API发送自然语言指令,并接收LLM生成的Shell命令。
Python代码示例 (local_pentest_agent.py)
import requests
import json
import subprocess
OLLAMA_API_URL = "http://localhost:11434/api/generate"
MODEL_NAME = "llama3" # 确保你已经拉取了这个模型
def generate_command(instruction: str) -> str:
"""
将自然语言指令发送给本地LLM,并返回生成的Shell命令。
"""
# 精心设计的系统提示,引导LLM专注于生成命令
system_prompt = (
"You are an expert penetration tester's assistant operating on Kali Linux. "
"Your sole purpose is to convert natural language instructions into a single, "
"executable shell command. Do not provide any explanation, comments, or "
"any text other than the command itself. If you cannot generate a command, "
"output 'ERROR: CANNOT COMPUTE'."
)
full_prompt = f"{system_prompt}\n\nInstruction: '{instruction}'\n\nCommand:"
try:
response = requests.post(
OLLAMA_API_URL,
json={
"model": MODEL_NAME,
"prompt": full_prompt,
"stream": False # 我们需要一次性获得完整响应
},
timeout=60 # 设置超时
)
response.raise_for_status()
# 解析响应,提取生成的命令
# Ollama的响应是一系列JSON对象,我们需要最后一个
full_response_text = response.text
# Ollama v0.1.32+ 返回单个JSON对象
try:
data = json.loads(full_response_text)
command = data.get("response", "").strip()
except json.JSONDecodeError:
return "ERROR: FAILED TO PARSE LLM RESPONSE"
if "ERROR:" in command or not command:
return "ERROR: LLM FAILED TO GENERATE COMMAND"
return command
except requests.exceptions.RequestException as e:
return f"ERROR: API request failed: {e}"
def main():
"""
主函数,接收用户输入并执行命令。
"""
print("Vibe Hacking - Local Agent Activated. Type 'exit' to quit.")
while True:
user_instruction = input(">> ")
if user_instruction.lower() == 'exit':
break
print(f"[*] Translating instruction: '{user_instruction}'")
generated_command = generate_command(user_instruction)
if generated_command.startswith("ERROR:"):
print(f"[!] {generated_command}")
continue
print(f"[+] Suggested command: \033[93m{generated_command}\033[0m")
# --- 安全关卡:人工审核 ---
confirm = input("[?] Execute this command? (y/N): ")
if confirm.lower() == 'y':
print(f"[*] Executing...")
try:
# 在shell中执行命令并捕获输出
result = subprocess.run(
generated_command,
shell=True,
check=True,
capture_output=True,
text=True
)
print("\n--- Command Output ---")
print(result.stdout)
if result.stderr:
print("\n--- Command Error ---")
print(result.stderr)
print("----------------------\n")
except subprocess.CalledProcessError as e:
print(f"[!] Command execution failed: {e}")
print(e.stderr)
except Exception as e:
print(f"[!] An unexpected error occurred: {e}")
else:
print("[*] Execution aborted by user.")
if __name__ == "__main__":
main()执行演示:
python local_pentest_agent.pyVibe Hacking - Local Agent Activated. Type 'exit' to quit.
>> 扫描192.168.1.1的所有TCP端口
[*] Translating instruction: '扫描192.168.1.1的所有TCP端口'
[+] Suggested command: nmap -p- 192.168.1.1
[?] Execute this command? (y/N): y
[*] Executing...
--- Command Output ---
Starting Nmap 7.92 ( https://nmap.org ) at 2025-09-26 06:37 UTC
Nmap scan report for 192.168.1.1
Host is up (0.0012s latency).
Not shown: 65532 closed tcp ports (reset)
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
443/tcp open https
Nmap done: 1 IP address (1 host up) scanned in 3.45 seconds
----------------------5.1.3. 优劣势分析
| 优势 (Pros) | 局限 (Cons) |
|---|---|
| 数据隐私与安全:所有数据均在本地处理,无泄露风险。 | 模型能力有限:本地模型的推理能力通常弱于顶级的商业模型。 |
| 离线运行:无需互联网连接,可在隔离网络中工作。 | 硬件要求高:运行大型模型需要强大的CPU、大量RAM,最好有NVIDIA GPU。 |
| 无API成本:除了硬件和电力成本,无额外费用。 | 配置复杂:相比直接调用API,本地部署需要更多的技术配置和维护。 |
| 高度可定制:可以微调模型以适应特定的渗透测试任务。 | 速度较慢:在消费级硬件上,命令生成速度可能比商业API慢。 |
5.2. 方案二:商业LLM API集成
此方案利用OpenAI、Google Gemini或Anthropic Claude等顶级商业模型,它们通常拥有更强的逻辑推理和代码生成能力,但需要将数据发送到云端。
5.2.1. 环境搭建:获取并配置API密钥
- 注册账户并获取API密钥:
- OpenAI: 前往 platform.openai.com
- Google AI: 前往 makersuite.google.com 获取Gemini的API密钥。
- Anthropic: 前往 anthropic.com 申请Claude的API访问权限。
- 安全地存储API密钥:
- 强烈建议使用环境变量来存储密钥,而不是硬编码在代码中。
shexport OPENAI_API_KEY='your-openai-api-key' export GOOGLE_API_KEY='your-gemini-api-key' export ANTHROPIC_API_KEY='your-anthropic-api-key'- 为了方便,可以将以上命令添加到您的
~/.bashrc或~/.zshrc文件中。
5.2.2. 交互脚本:构建安全的API封装器
以下Python代码展示了如何创建一个通用的封装器来与不同的商业API交互,并将结果安全地传递给执行器。
Python代码示例 (cloud_pentest_agent.py)
import os
import openai
import google.generativeai as genai
import anthropic
import subprocess
# 从环境变量加载API密钥
try:
openai.api_key = os.environ["OPENAI_API_KEY"]
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
anthropic_client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
except KeyError as e:
print(f"Error: Environment variable {e} not set. Please set your API keys.")
exit(1)
def generate_command_cloud(provider: str, instruction: str) -> str:
"""
使用指定的云服务商LLM生成Shell命令。
"""
system_prompt = (
"You are an expert penetration tester's assistant on Kali Linux. "
"Your task is to convert a natural language instruction into a single, "
"executable shell command. Return ONLY the command, with no explanations."
)
try:
if provider == 'openai':
response = openai.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": instruction}
],
temperature=0.0
)
return response.choices[0].message.content.strip()
elif provider == 'gemini':
model = genai.GenerativeModel('gemini-pro')
# Gemini需要更直接的提示
full_prompt = f"{system_prompt}\n\nInstruction: '{instruction}'\n\nCommand:"
response = model.generate_content(full_prompt)
return response.text.strip()
elif provider == 'anthropic':
response = anthropic_client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
system=system_prompt,
messages=[
{"role": "user", "content": instruction}
]
)
return response.content[0].text.strip()
else:
return "ERROR: Unsupported provider."
except Exception as e:
return f"ERROR: API call to {provider} failed: {e}"
# main()函数与本地方案类似,只需将调用 generate_command() 的地方
# 替换为 generate_command_cloud(provider, instruction)。
# 为了简洁,此处不再重复。
# 示例调用
provider_choice = "openai" # 或 'gemini', 'anthropic'
instruction = "查找域名example.com的DNS MX记录"
command = generate_command_cloud(provider_choice, instruction)
print(f"Provider: {provider_choice}\nInstruction: {instruction}\nGenerated Command: {command}")运行结果示例:
Provider: openai
Instruction: 查找域名example.com的DNS MX记录
Generated Command: dig example.com MX5.2.3. 优劣势与注意事项
| 优势 (Pros) | 注意事项 (Cons) |
|---|---|
| 模型能力强大:通常能理解更复杂的指令,生成更准确的命令。 | API成本:每次调用都会产生费用,大规模使用成本较高。 |
| 无需本地硬件:对本地计算机的硬件要求极低。 | 数据安全风险:指令和潜在的敏感信息会发送给第三方服务商。 |
| 快速迭代:可以轻松切换和使用最新的模型。 | 速率限制:API调用有频率限制,可能影响自动化测试的速度。 |
| 维护简单:无需担心模型更新、硬件维护等问题。 | 需要网络连接:必须有稳定的互联网连接。 |
5.3. 安全最佳实践
警告: 自动执行由AI生成的命令具有极高风险。一个错误的命令可能导致数据丢失、系统损坏或法律问题。永远不要在没有严格控制和审查的情况下运行此系统。
强制人工审核 (Human-in-the-Loop)
- 绝对不要自动执行LLM返回的任何命令。
- 在执行前,必须将生成的命令清晰地展示给用户,并要求显式确认(如输入'y')。这是防止
rm -rf /等灾难性命令的最后一道防线。
沙箱化执行 (Sandboxing)
- 在隔离的环境中执行所有命令,以限制潜在的破坏。Docker是实现这一点的理想工具。
- 可以创建一个临时的、网络受限的Docker容器来运行每个命令,执行完毕后立即销毁容器。
- 示例策略:
docker run --rm -i kalilinux/kali-rolling /bin/bash -c "YOUR_GENERATED_COMMAND"
输入清洗与命令校验 (Sanitization & Validation)
- 输入清洗:对用户输入的自然语言指令进行过滤,移除可能导致提示注入的特殊字符或指令。
- 命令校验:在请求用户确认之前,对LLM生成的命令进行程序化校验。
- 白名单机制:只允许执行一个预定义的安全命令列表(如
nmap,dig,whois),拒绝其他一切命令。 - 黑名单机制:明确禁止执行危险命令(如
rm,mv,chmod,shutdown)。 - 参数校验:检查命令参数是否包含危险序列,如命令拼接符
&&,||,;或反引号`。
- 白名单机制:只允许执行一个预定义的安全命令列表(如
通过结合以上方案与安全实践,您可以构建一个既强大又可控的自然语言驱动渗透测试助手,显著提升工作效率。
6. 优势、挑战与未来展望:审视双刃剑
Vibe Hacking为网络安全带来了革命性的前景,但同时也伴随着不可忽视的挑战。
6.1. 为网络安全战略顾问带来的核心优势
- 效率革命:将数天的手动测试工作压缩至数小时,极大提升了测试频率和覆盖广度。
- 降低门槛,提升专家价值:使初级分析师也能在AI辅助下执行复杂的测试,同时让高级专家从重复性劳动中解放出来,专注于威胁狩猎、攻击模拟和战略规划等更具创造性的工作。
- 动态适应性:与固定的自动化脚本不同,LLM智能体能根据目标环境的实时反馈动态调整策略,展现出更高的灵活性和成功率。
- 知识整合与传承:LLM相当于一个永不疲倦、知识渊博的专家团队,能够整合全球最新的漏洞信息和攻击技术,并将其应用于实践。
6.2. 面临的挑战与风险
技术挑战:
- “幻觉”问题:LLM可能生成错误的命令或做出不准确的判断,导致测试失败甚至对目标系统造成损害。RAG技术的应用旨在缓解此问题,但无法完全消除。
- 环境理解局限:在需要长时间维持、上下文极其复杂的渗透活动中,LLM可能会丢失关键信息或做出次优决策。
- 可靠性与稳定性:在高度动态或强对抗性的网络环境中,AI模型的表现可能不稳定,需要“人在回路”进行监督。
安全与伦理风险:
- 滥用风险:这把“双刃剑”最锋利的一面是,该技术可能被恶意行为者“武器化”,用于发起大规模、自动化的网络攻击,极大地降低攻击门槛。
- 责任归属:当AI智能体在测试中造成意外损害(如数据破坏或业务中断)时,其法律和伦理责任的界定将成为一个复杂难题。
- 数据隐私:若使用基于云的LLM服务,渗透测试过程中涉及的敏感目标信息和漏洞数据可能存在泄露风险。
6.3. 未来展望
尽管挑战重重,Vibe Hacking的未来发展方向依然清晰且令人振奋。

上图描绘了Vibe Hacking未来生态系统的核心要素,其中心是 人机共生(Human-AI Symbiosis)。未来的发展将围绕以下几个方向展开:
- 人机协同新范式:Vibe Hacking不会完全取代人类专家,而是演变为一种人类与AI智能体协同作战的伙伴关系。人类负责设定战略目标、进行创造性思考和最终决策,AI则作为强大的执行者和分析师。
- 攻防对抗的智能升级:Vibe Hacking的出现必将催生基于LLM的自动化防御系统(AI Blue Team),能够实时分析攻击模式并自动部署防御策略,形成更高维度的智能化攻防博弈。
- 多智能体协作(Multi-Agent Collaboration):未来的系统可能由多个专职AI智能体组成,例如“侦察Agent”、“漏洞利用Agent”、“报告Agent”等,它们协同工作,共同完成更复杂、更大规模的渗透测试任务。
- 与框架的深度集成:系统将与MITRE ATT&CK等框架进行更深度的融合,不仅用于任务规划,更能用于攻击模拟、防御评估和威胁情报关联。
7. 结论:重塑未来网络攻防格局
“Vibe Hacking”不仅仅是一个技术框架或一套工具,它代表着一种深刻的思想范式转移。它预示着一个新时代的到来:未来的网络安全将不再是单纯的人与工具的结合,而是 人类战略智慧 与 机器执行智能 的深度融合。
通过将安全专家的战略意图直接、高效地转化为机器可执行的自动化流程,Vibe Hacking有望从根本上重塑网络攻防的效率、广度和深度。它将引领我们进入一个更加智能、敏捷和高效的安全新纪元,在这个纪元里,人类将与AI并肩作战,共同守护数字世界的边界。
8. 参考文献
- Happe, A., et al. (2023). "LLMs for Penetration Testing: A Systematic Review."
- Deng, S., et al. (2023). "PentestGPT: An LLM-empowered Automatic Penetration Testing Tool."
- Isozaki, I., et al. (2024). "Benchmarking, Analysis, and Improvement of Large Language Models for Penetration Testing."
- Karpathy, A. (2025). On "Vibe Coding". The New Stack.
- Kali.org. "Kali Linux 2025.2 Release (MITRE ATT&CK)".
- MITRE. "MITRE ATT&CK® Framework".
- Research on LLM-driven agents like HackSynth, AutoPT, and Villager.
- Varonis. "What Is an LLM in Cybersecurity?".
- Picus Security. "Top 15 Use Cases of LLMs for Cybersecurity".
- IBM. "What is the MITRE ATT&CK framework?".
贡献者
 pansin
pansin