《AI新纪元的数据安全基石:深度解析数据赋能与保护架构(DEPA)》
引言:人工智能时代的数据困境
人工智能(AI),特别是大语言模型(LLM)的崛起,正以前所未有的速度重塑世界。然而,这场技术革命的根基——数据,也正成为其发展的“阿喀琉斯之踵”。我们正面临一个严峻的悖论:AI的进步渴求海量数据,而个人隐私、商业机密和国家安全则要求对数据进行严格保护。这一矛盾催生了新的数据困境:
- 数据垄断与孤岛效应: 海量高质量数据被少数科技巨头掌控,形成“数据护城河”,阻碍了创新和公平竞争。同时,大量有价值的数据因隐私和安全顾虑被“冻结”在各个组织内部,形成数据孤岛,无法发挥其潜在价值。
- 隐私泄露风险加剧: LLM的训练数据可能包含大量个人身份信息(PII)。模型强大的记忆和生成能力,使其可能在不经意间泄露训练数据中的敏感内容,例如在对话中复现医疗记录或个人邮件。三星员工使用ChatGPT导致公司机密泄露的事件,正是这一风险的现实写照。
- 训练数据偏见与歧视: 训练数据的不平衡或带有偏见,会直接导致AI模型产生歧视性或不公平的输出,在信贷审批、招聘、司法等关键领域造成严重的社会问题。
- 合规性与治理难题: 全球数据保护法规(如GDPR、CCPA)对数据处理提出了“目的限制”、“数据最小化”和“被遗忘权”等严格要求。然而,LLM的“黑箱”特性、数据需求的无限性以及技术上彻底“遗忘”的困难,使其在满足合规性方面面临巨大挑战。
- 新型攻击向量: 针对AI模型的攻击日益复杂,包括通过注入恶意数据来“投毒”模型的数据投毒攻击,以及通过精心设计的提示词绕过安全护栏的越狱攻击,这些都对数据和模型的安全性构成了新的威胁。
如何才能打破“数据不动价值不生,数据一动安全难保”的僵局?这不仅是技术挑战,更是关乎信任、法律与社会协作的系统性工程。正是在这一背景下,**数据赋能与保护架构(Data Empowerment and Protection Architecture, DEPA)**应运而生,为构建可信AI生态提供了一套创新的技术法律框架。
DEPA框架深度解析:理论与实践的优化
DEPA并非单一技术,而是一个综合性的技术法律解决方案,其核心目标是在保障数据主权和隐私的前提下,安全、合规地释放数据价值。它通过整合多种前沿的隐私增强技术(Privacy-Enhancing Technologies, PETs),构建了一个去中心化、以用户为中心的数据共享生态。
DEPA的基石是ADEPTS原则,确保整个架构的稳健与可信:
- Auditable (可审计)
- Dynamic (动态)
- Enforceable (可执行)
- Purpose-Limited (目的限制)
- Tamper-proof (防篡改)
- Secure (安全)
为实现这些原则,DEPA依赖于三大核心技术支柱:
1. 机密计算 (Confidential Computing)
核心问题: 如何保护“使用中”的数据? 传统加密技术能保护传输中和存储中的数据,但一旦数据被加载到内存中进行计算,就会以明文形式暴露,极易受到来自操作系统、虚拟机管理器甚至云服务提供商的攻击。
机密计算通过创建基于硬件的**可信执行环境(Trusted Execution Environment, TEE)**来解决这一难题。TEE(如Intel SGX, AMD SEV)是CPU内的一个安全隔离区,能确保在其中运行的代码和处理的数据对外部环境(包括云平台管理员)完全保密和完整。
DEPA将这一理念具体化为机密清洁室(Confidential Clean Rooms, CCRs)。CCRs是一个临时的、硬件保护的计算环境,专为特定的数据处理任务(如模型训练)而创建。数据提供者将加密数据送入CCR,在其中解密、处理和分析,但原始数据绝不会离开这个安全环境。任务完成后,CCR即被销毁。AWS Nitro Enclaves和Google Confidential Spaces等主流云服务,已为CCRs的实现提供了成熟的技术支持。
2. 差分隐私 (Differential Privacy)
核心问题: 如何在不暴露个体信息的前提下,进行聚合数据分析? 即使在CCRs这样的安全环境中,分析结果(如训练好的AI模型)本身也可能泄露个体信息。例如,模型可能“记住”了训练集中的某个罕见病例。
**差分隐私(DP)**为此提供了一个严谨的数学定义和解决方案。其核心思想是在查询结果或模型参数中添加经过精确计算的“噪声”,使得任何单个个体的数据是否存在于数据集中,对最终输出结果的影响微乎其微。这样,攻击者即使拥有除目标个体外的所有背景知识,也无法推断出该个体的信息。
- 隐私预算 (ε, δ): 差分隐私的保护强度由**epsilon (ε)和delta (δ)**两个参数来量化。
ε值越小,隐私保护级别越高,但添加的噪声越多,数据可用性相应降低。ε代表了单次查询所能泄露信息的上限,构成了可量化的“隐私成本”。 - 实现方法: 在AI模型训练中,常用的方法是差分隐私随机梯度下降(DP-SGD)。它在每次梯度更新时对梯度进行裁剪并添加高斯噪声,从而保证训练出的模型满足差分隐私要求。
- 现实应用: 美国人口普查局已采用差分隐私技术来发布统计数据;苹果、谷歌等公司也利用本地差分隐私收集用户行为数据以改善服务,同时保护用户隐私。
3. 数字合同 (Digital Contracts)
核心问题: 如何确保数据共享遵循所有参与方的意愿,并实现透明、可追溯的管理? 传统的纸质合同或静态的“同意”条款,难以在复杂的、动态的数据共享场景中有效执行和审计。
DEPA引入了数字合同,这是一种机器可读、可自动执行的数据共享协议。它以结构化格式(如JSON)精确定义了数据共享的各项条款,包括:
- 参与方: 数据提供者、数据消费者。
- 数据使用目的: 明确规定数据只能用于特定目的(Purpose Limitation)。
- 允许的操作: 如模型训练、统计分析等。
- 隐私约束: 例如,必须采用差分隐私,并规定总的隐私预算
ε和δ的上限。 - 有效期: 合同的生效和终止时间。
这种方式将数据治理规则从法律文本转化为可执行代码,由架构自动强制执行,确保了数据共享的透明性、可审计性和不可抵赖性。
数字合同示例 (JSON):
{
"contractId": "contract-12345-xyz",
"dataConsumer": "AMX_Startup_Inc",
"dataProviders": ["Hospital_A", "Clinic_B"],
"purpose": "Training a diabetic retinopathy detection model.",
"allowedOperations": ["DP-SGD_Training"],
"privacyConstraints": {
"type": "DifferentialPrivacy",
"epsilon": 1.5,
"delta": 1e-5
},
"validity": {
"from": "2025-10-01T00:00:00Z",
"to": "2026-03-31T23:59:59Z"
},
"attestationRequired": true
}DEPA核心架构与生态系统
DEPA的魅力不仅在于其技术支柱,更在于它构建了一个多方参与、权责明确的协作生态系统。下图清晰地展示了DEPA的架构和数据流转路径。
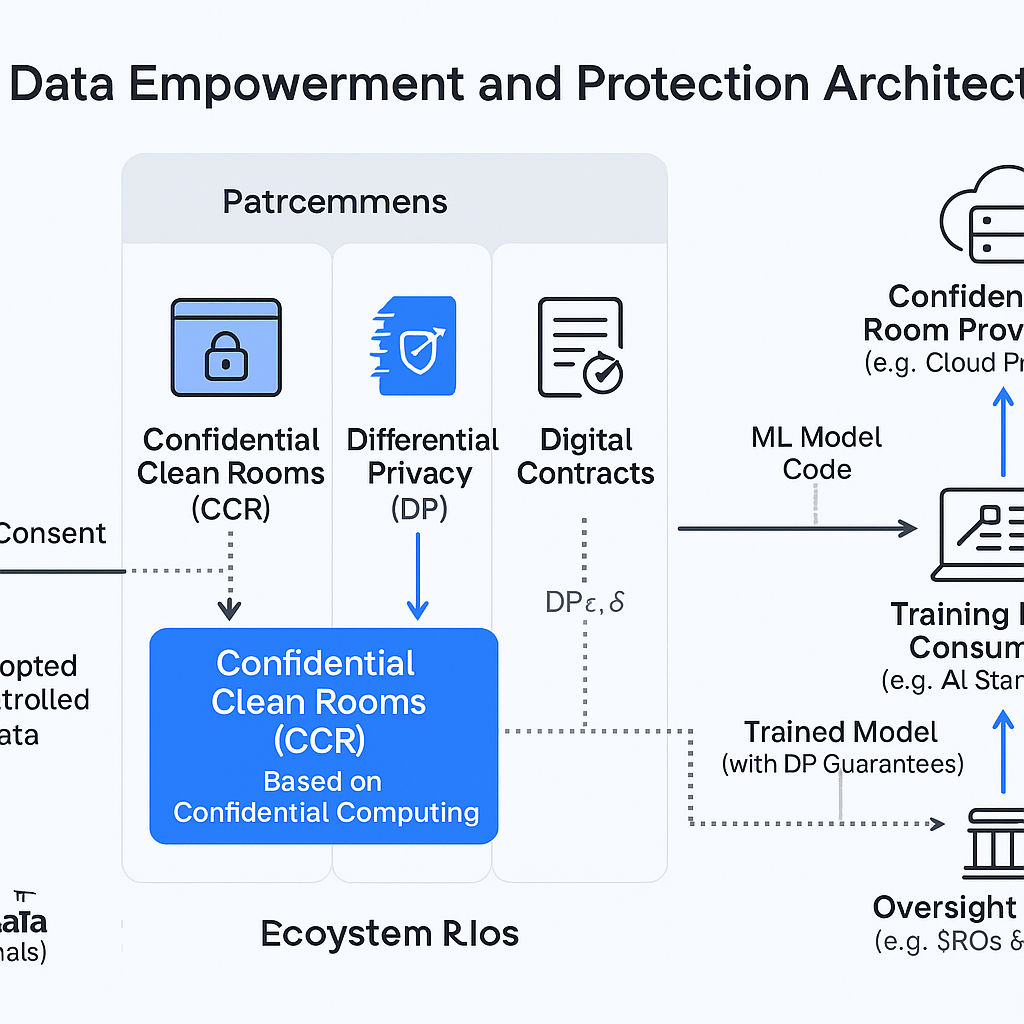
生态系统中的核心角色:
- 数据主体 (Data Principals): 数据的最终所有者,即个人用户。他们通过“同意管理器”(Consent Manager)对自己的数据行使控制权,授权或拒绝数据共享请求。
- 数据提供者 (Trusted Data Providers, TDPs): 合法持有数据的机构,如银行、医院、电信公司等。他们根据数据主体的同意和数字合同的约定,向CCRs提供加密数据。
- 数据消费者 (Training Data Consumers, TDCs): 希望利用数据进行分析或模型训练的机构,如AI初创公司、研究机构等。他们提供算法代码,但无法直接接触原始数据。
- 机密清洁室提供者 (Confidential Room Provider): 提供机密计算基础设施的云服务商(如AWS, Google Cloud)。
- 监督机构 (Oversight): 包括自律组织(SROs)和监管机构,负责审计和监督整个生态系统的合规运作,确保所有参与方遵守规则。
数据流转与交互过程:
- 同意发起: TDC向数据主体发起数据使用请求,并通过数字合同明确用途和条件。
- 授权: 数据主体通过同意管理器审查并授权请求。
- 创建清洁室: 获得授权后,一个临时的CCRs被创建。
- 数据与代码注入: TDP将加密后的数据注入CCRs;TDC将ML模型代码注入CCRs。
- 机密训练: 在CCRs内部,数据被解密并用于模型训练。整个过程受数字合同(如隐私预算限制)和差分隐私算法的约束。
- 输出结果: 训练完成后,一个带有差分隐私保证的已训练模型被输出给TDC。原始数据则随着CCRs的销毁而被彻底清除。
- 审计与监督: 整个过程的日志(不含敏感数据)都可被监督机构审计,以确保合规性。
案例研究:DEPA的价值、优势与创新
核心案例:AMX初创公司的AI医疗诊断
困境: AMX是一家致力于开发AI视网膜病变诊断模型的初创公司。为了提高模型的准确性和泛化能力,他们迫切需要来自多家医院的大量、多样化的患者眼底图像数据。然而,由于GDPR和HIPAA等严格的隐私法规,医院不敢直接共享这些高度敏感的医疗数据。AMX陷入了“无米之炊”的困境,创新受阻。
DEPA解决方案:
- 打破数据孤岛: AMX (TDC) 与多家医院 (TDPs) 签订DEPA数字合同,并获得患者(数据主体)的明确同意。
- 保障数据安全: 医院将加密的眼底图像数据提供给一个为该项目专设的CCRs。AMX提供其模型训练代码。
- 隐私保护训练: 在CCRs内,AMX的模型在海量数据上进行训练,同时应用DP-SGD算法确保最终模型不会泄露任何个体患者的信息。AMX的工程师自始至终无法看到任何一张原始图像。
- 实现商业价值: AMX获得了一个性能卓越且符合隐私法规的AI模型。他们可以自信地将其商业化,为医院提供高效的辅助诊断服务。医院也因参与数据协作而获得了价值回馈,同时提升了自身的诊疗水平。
DEPA的普适性与创新价值:
- 金融服务: 在印度,基于DEPA理念的**账户聚合器(Account Aggregator, AA)**框架,允许用户安全地将自己的多家银行账户信息授权给贷款机构,用于快速信贷审批,极大地推动了普惠金融。
- 公共服务: 政府部门可以在不泄露公民个人隐私的前提下,利用多部门数据进行城市规划、交通优化和公共卫生政策制定。
- 打破“冻结市场”: DEPA通过技术手段建立信任,将因风险而“冻结”的数据资产盘活,创造了全新的数据协作模式和商业机会,尤其为缺乏海量数据资源的中小企业提供了公平的竞争舞台。
技术法律框架的融合与展望
DEPA的设计理念与全球主流的数据保护法规高度兼容。它通过技术手段,将GDPR、CCPA、印度DPDP法案等法规中的核心原则——如知情同意、目的限制、数据最小化和安全保障——内化到系统架构中,实现了“合规设计”(Compliance by Design)。
同时,DEPA可以与**NIST AI风险管理框架(AI RMF)**形成完美互补。NIST AI RMF提供了一个全面的AI风险治理“元框架”,指导组织如何“治理(Govern)、映射(Map)、测量(Measure)、管理(Manage)”AI风险。而DEPA则为其中的关键环节提供了具体的技术实现路径:
- 治理与映射: DEPA的数字合同和同意管理机制,正是实现NIST框架中“治理”和“映射”功能的有力工具,它清晰地界定了数据使用背景和各方权责。
- 测量与管理: DEPA通过差分隐私的隐私预算
ε,为NIST框架中的“测量”提供了可量化的隐私风险度量。机密计算则为“管理”风险提供了强大的技术保障。
展望未来,DEPA有望成为构建**负责任AI(Responsible AI)**生态系统的关键基础设施。随着技术的成熟和生态的完善,它不仅能促进跨机构、跨国界的安全数据协作,还将催生以隐私保护为核心的新型数据服务和商业模式,最终推动AI技术在真正造福人类的同时,其发展路径也更加安全、可信和可持续。
结论
在人工智能的浪潮之巅,我们不能忽视其脚下汹涌的数据安全与隐私暗流。数据赋能与保护架构(DEPA)提供了一条穿越这片复杂水域的清晰航线。它并非乌托邦式的构想,而是由机密计算、差分隐私和数字合同等前沿技术构成的务实解决方案。
DEPA通过其创新的技术法律融合框架,在AI发展的数据需求与个人隐私的保护权利之间取得了精妙的平衡。它将抽象的法律原则转化为可执行的技术代码,用信任的基石打破数据孤岛,为中小型创新企业赋能,为构建一个更加公平、透明和可信的AI新纪元铺平了道路。DEPA不仅仅是一个技术架构,更是我们迈向负责任AI未来的重要承诺。
参考文献
- DEPA World. (n.d.). Data Empowerment and Protection Architecture. Retrieved from depa.world
- Arxiv. (n.d.). Confidential-DP: A practical training framework for privacy-preserving deep learning on sensitive data. Retrieved from arxiv.org
- NIST. (2023). AI Risk Management Framework (AI RMF 1.0). Retrieved from nist.gov
- Confidential Computing Consortium. (n.d.). Technical Analysis of Confidential Computing. Retrieved from confidentialcomputing.io
- European Data Protection Board. (n.d.). Report on Large Language Models and Privacy. Retrieved from europa.eu
- iSPIRT. (n.d.). Re-imagining the Data Landscape with DEPA. Retrieved from ispirt.in
- SFLC.in. (n.d.). DEPA for Health: A Consent-based Health Data Management Framework. Retrieved from sflc.in
- Cloudflare. (n.d.). What is differential privacy? Retrieved from cloudflare.com
- NITI Aayog. (n.d.). India's Data Empowerment and Protection Architecture (DEPA) - A new paradigm for data. Retrieved from niti.gov.in
- ORF Online. (n.d.). A critical look at India's Data Empowerment and Protection Architecture. Retrieved from orfonline.org
贡献者
 pansin
pansin