RegData语义保护体系深度解析:金融AI时代的数据安全范式革命
引言:金融服务业的数据安全困境与新范式
金融服务业(FSI)正加速迈向由人工智能(AI)驱动的“智能企业”时代。然而,这一转型伴随着前所未有的数据安全挑战。从数据泄露、模型入侵到日益严苛的全球监管法规(如GDPR、FINMA),传统的数据脱敏和加密技术在平衡数据安全与数据效用方面日益捉襟见肘。静态、一刀切的保护方式往往会破坏数据内在的语义关系,导致其在AI模型训练和高级分析中价值锐减。
在这一背景下,《Architectures for the Intelligent AI-Ready Enterprise》一书中提出的RegData语义保护体系应运而生。它不再将数据视为无差别的比特流,而是通过理解数据本身及其上下文的“意义”,实现一种动态、精准且保留业务价值的全新数据保护范式。本文旨在深入剖析该体系的核心理念、技术基础与实践价值,并对其潜在挑战与局限性进行批判性分析。
核心概念解析:语义数据保护的五大支柱
RegData语义保护体系建立在五个紧密关联的核心原则之上,共同构成了从“数据”到“信息”的保护升级。
1. 语义理解 (Semantic Understanding)
利用自然语言处理(NLP)和机器学习(ML)模型,系统能够超越数据类型和结构,深刻理解非结构化和半结构化数据(如客户邮件、合同文本、通话记录)的真实含义。它识别的不是“字符串”,而是“人名”、“地址”、“交易意图”等语义实体。
2. 上下文感知 (Context-Awareness)
保护策略不再是静态规则,而是根据数据所处的具体业务场景和查询上下文动态调整。例如,一个电话号码在客户支持工单中可能被视为高敏感信息,但在内部通讯录查询中则为常规信息。上下文感知能力确保了保护的灵活性与精确性。
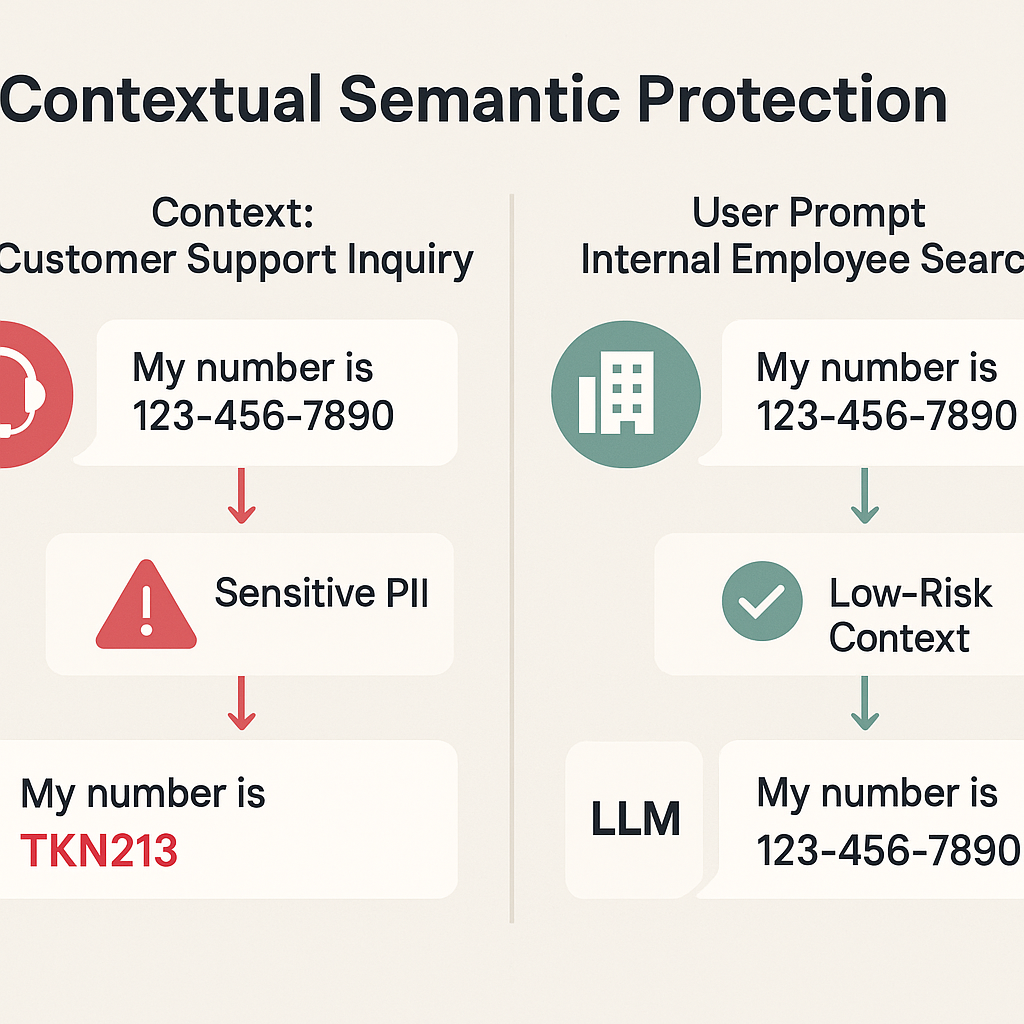
English Summary: Contextual Semantic Protection This principle means that data protection is not static but dynamically adapts based on the situation. The system understands the context of a data request. For example, a phone number in a "Customer Support Inquiry" is identified as sensitive Personally Identifiable Information (PII) and is tokenized (e.g., replaced with "TKN213"). However, the same phone number in an "Internal Employee Search" is considered low-risk and remains unchanged, allowing it to be processed by a Large Language Model (LLM) or application without modification. This ensures that security is applied precisely where needed without unnecessarily disrupting business operations.
3. 格式保留 (Format Preservation)
在对敏感数据进行替换(令牌化)时,保持其原始的数据格式、长度和字符类型。例如,一个16位的信用卡号被替换后,仍然是一个16位的数字字符串。这极大地降低了对现有数据库架构和应用程序的改造需求,确保了业务连续性。
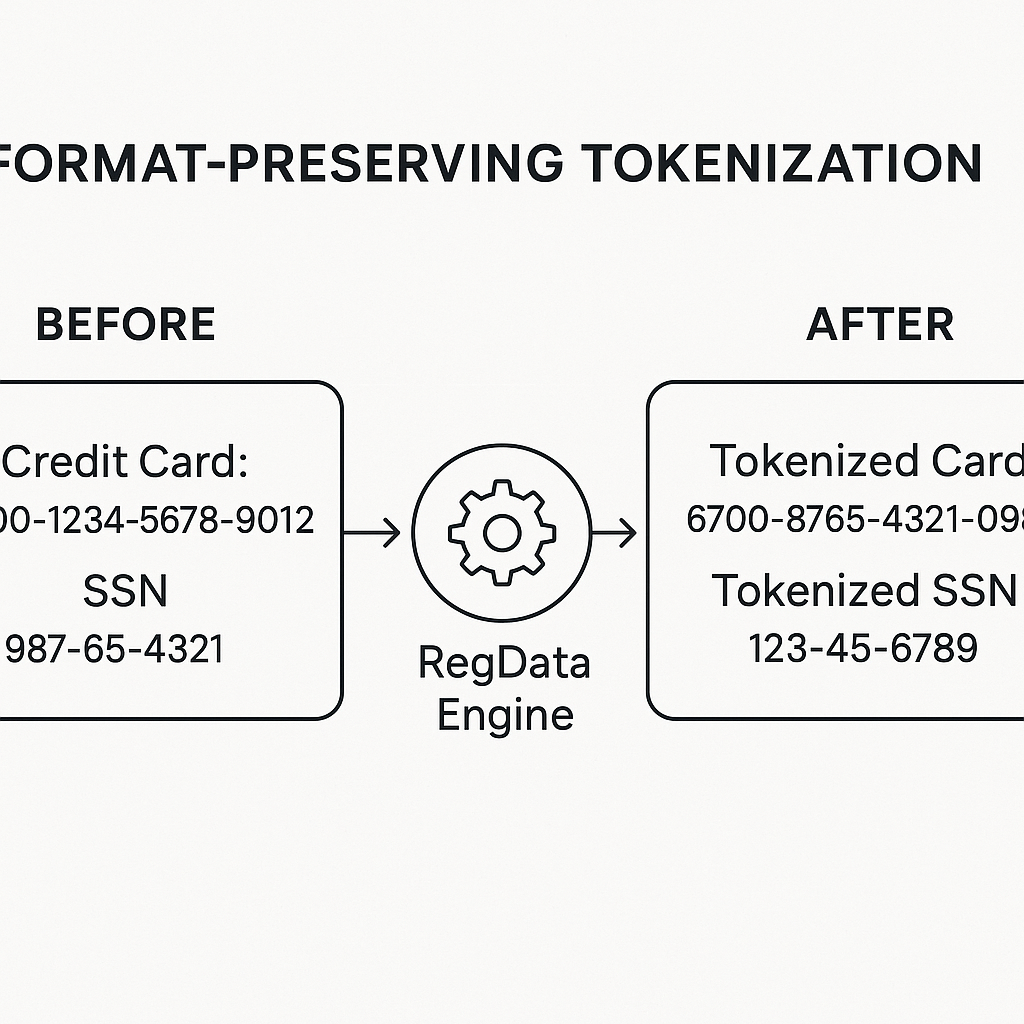
English Summary: Format-Preserving Tokenization Format-Preserving Tokenization is a process where sensitive data is replaced with a non-sensitive substitute, or "token." The key feature, as handled by the RegData Engine, is that the token maintains the same format (e.g., length, character type, structure) as the original data. For instance, a 16-digit credit card number is replaced by another 16-digit number, and a Social Security Number (SSN) is replaced by a token with the same
XXX-XX-XXXXstructure. This allows tokenized data to be used in existing applications and databases without requiring changes to their schema or logic.
4. 确定性令牌化 (Deterministic Tokenization)
对于相同的原始敏感值,在相同的“语义分区”内始终生成同一个令牌。这使得受保护的数据依然可以进行连接(Join)、聚合(Aggregation)等分析操作,保留了数据的参照完整性和分析效用,解决了传统随机脱敏导致数据关系断裂的问题。
5. 语义分区 (Semantic Partitioning)
创建逻辑隔离的“数据域”,在不同分区内,相同的原始值会被映射为不同的令牌。例如,“客户A”在美国分区和欧洲分区的令牌是不同的。这遵循了数据主权和分区隔离原则,有效防止了跨区域、跨业务的数据关联风险。
系统架构与技术基础
系统架构 (System Architecture)
RegData体系并非空中楼阁,其背后是坚实的学术理论和前沿的技术栈支撑。
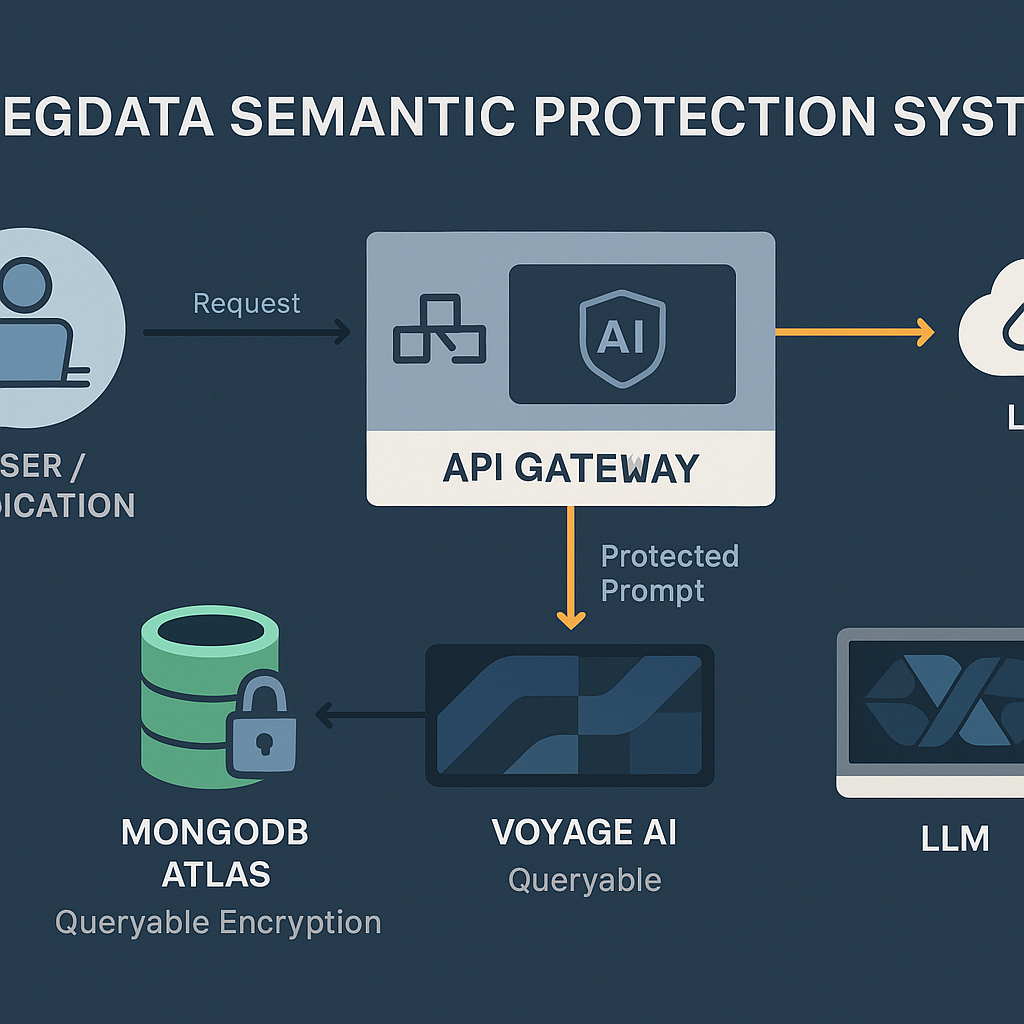
English Summary: System Architecture The RegData system architecture operates as an intelligent data protection layer. A user or application sends a request, which first passes through an API Gateway. This gateway uses AI to inspect the request content. The prompt is then sent to a semantic query service like Voyage AI to analyze its meaning and identify sensitive information. Based on this analysis, a "Protected Prompt" is generated, with sensitive data either redacted or tokenized. This protected prompt can then be safely sent to a Large Language Model (LLM) for processing. All underlying sensitive data is stored securely in a database like MongoDB Atlas, which uses queryable encryption to allow analysis without exposing the raw data.
学术理论基础
- 自然语言处理 (Natural Language Processing, NLP):NLP是实现语义理解的核心。通过命名实体识别(NER)、关系抽取和情感分析等技术,系统能够从海量文本中精准识别和分类敏感信息。
- 隐私保护机器学习 (Privacy-Preserving Machine Learning, PPML):PPML领域的理论,如差分隐私和联邦学习,为如何在保护隐私的同时利用数据提供了理论指导。RegData的理念与PPML的目标一致,即在保证数据安全的前提下,最大化数据效用。
- 语义披露控制 (Semantic Disclosure Control, SeDC):学术界提出的SeDC范式主张从语义层面评估披露风险,而非单纯依赖统计分布。这与RegData通过理解数据“意义”来实施保护的理念不谋而合,为其提供了有力的理论支撑。
关键技术栈
- MongoDB Atlas:作为核心的数据平台,MongoDB的灵活文档模型天然适合存储和处理金融行业中常见的半结构化和非结构化数据。其内置的字段级加密(Field-Level Encryption)和强大的可扩展性,为RegData保护套件(RPS)的部署提供了理想的基础设施。案例显示,RPS正是构建于MongoDB之上,以应对金融机构的数字化转型挑战。
- RegData平台:这是实现语义保护逻辑的核心引擎,负责整合NLP模型、管理令牌化策略、执行语义分区,并与数据存储层(如MongoDB)和应用层进行交互。
- Voyage AI嵌入模型:为了实现高质量的语义理解,系统需要强大的文本嵌入(Embedding)能力。Voyage AI等先进的嵌入模型可以将文本转换为高维向量,从而使机器能够通过计算向量相似度来理解语义相似性,是上下文感知和语义搜索的关键。
价值与意义:为何对金融AI至关重要
RegData体系为金融机构带来了四个层面的核心价值。
主动合规与风险降低:通过对敏感数据的精准、动态识别和保护,该体系帮助金融机构自动满足GDPR等法规对“设计即隐私”(Privacy by Design)的要求。它将合规性从被动审计转变为主动防御,显著降低了数据泄露和违规罚款的风险。
数据效用最大化:与传统脱敏技术相比,格式保留和确定性令牌化保留了数据的结构和分析价值。这意味着业务分析师和AI模型可以在一个“安全的数据副本”上工作,既能洞察业务趋势,又无法触及原始敏感信息,完美解决了安全与效用之间的核心矛盾。
实时保护与弹性:数据保护是实时发生的,能够适应不断变化的业务需求和数据上下文。这种弹性使得金融机构在开发新应用(如生成式AI驱动的信贷审批)时,可以无缝集成数据保护能力,加速创新周期。
增强的可解释性与审计能力:由于保护策略基于清晰的语义规则和上下文,因此每一次数据保护操作都是可解释和可追溯的。这为内部审计和外部监管提供了清晰的证据链,回答了“什么数据被保护、为什么被保护以及如何被保护”的关键问题。
影响与创新:从静态脱敏到动态语义保护的范式转变
RegData体系的出现,标志着数据安全领域的一次重要范式转变。
传统数据安全方案如同修建静态的城墙,而语义保护则像为数据配备了能理解语言、识别身份并动态决策的智能保镖。
| 对比维度 | 传统数据脱敏 | RegData语义保护 |
|---|---|---|
| 保护对象 | 预定义的字段或模式(如XXX-XX-XXXX) | 数据的语义内容(“这是一个社保号码”) |
| 保护方式 | 静态、批处理、规则僵化 | 动态、实时、上下文感知 |
| 数据效用 | 严重损害,分析价值低 | 高度保留,支持复杂分析和AI训练 |
| 应用集成 | 可能需要修改应用和数据库 schema | 兼容性高,对上层应用透明 |
| 核心理念 | 数据混淆 (Data Obfuscation) | 语义保留 (Meaning Preservation) |
这种转变使得数据保护不再是业务发展的障碍,而是成为AI时代企业智能化的一个内生组成部分,为金融机构在激烈竞争中安全地释放数据潜力铺平了道路。
实践与案例:RegData在金融场景的应用
结合搜索到的案例,RegData语义保护体系已在多个金融场景中展现其价值:
核心系统现代化迁移:一家欧洲私人银行在将其客户关系管理(CRM)、核心银行系统迁移至云端时,利用构建在MongoDB Atlas上的RegData保护套- 件(RPS),对客户敏感数据进行匿名化处理。这不仅确保了迁移过程符合FINMA等严格监管,还允许在总部之外的区域安全地进行数据查询和分析。
AI驱动的合规管道:在构建用于提供金融建议的AI系统时,可利用RegData体系对输入数据和模型输出进行实时内容审核。例如,通过向量搜索和语义识别,系统可以自动发现并屏蔽不合规的投资建议或泄露的客户隐私,构建一个端到端的监管合规管道。
安全的生成式AI应用:在开发基于生成式AI的信用卡申请或商业贷款审批应用时,RegData可对用户提交的文档(如身份证明、财报)进行实时语义分析和保护,确保在AI模型处理这些信息之前,所有个人身份信息(PII)都已被安全地令牌化,实现了AI应用的零信任数据处理。
批判性分析:审视潜在的挑战与局限
尽管RegData语义保护体系前景广阔,但作为一个新兴的技术框架,其实施和应用仍面临诸多挑战和局限性。客观审视这些问题对于做出明智的技术决策至关重要。
1. 实施复杂性与成本
- 技术栈复杂:该体系整合了数据库、NLP模型、嵌入服务和策略引擎,部署和维护这样一个复杂的分布式系统需要较高的技术能力和专业知识。
- 初始投入高:采用MongoDB Atlas、商业化的嵌入模型(如Voyage AI)以及可能的RegData平台许可费用,意味着前期投资成本不菲。此外,配置语义规则和分区策略也需要大量专家投入。
2. 对核心组件的高度依赖
- 模型性能决定一切:语义保护的有效性直接取决于NLP和嵌入模型的质量。如果模型无法准确识别实体或理解上下文,就可能导致敏感数据漏报(False Negatives)或过度保护(False Positives),前者引发安全风险,后者影响业务运行。
- 令牌库的安全风险:与所有基于令牌化的方案一样,“格式保留令牌化”通常依赖一个安全的令牌存储库(Token Vault)。这个存储库本身成为一个高价值的攻击目标,一旦被攻破,所有受保护数据都可能被逆向还原。它将风险从应用数据库转移到了令牌库,构成了单点故障风险。
3. 标准化与通用性挑战
- 缺乏行业标准:目前,无论是“语义数据保护”还是“格式保留加密/令牌化”(FPE/FPT),都缺乏被业界广泛接受的统一标准。不同的厂商可能有专有的实现方式,增加了技术选型和未来迁移的风险。
- 算法的安全性审查:一些专有的令牌化方法可能缺乏密码学界的严格公开审查,其长期安全性存在不确定性。
4. 性能开销
- 实时分析的延迟:对数据进行实时的语义分析、嵌入转换和令牌化操作会引入额外的计算开销。在高吞吐量的交易型场景中,这可能会成为性能瓶颈,导致处理延迟。
- “有库令牌化”的瓶颈:如果采用有库(Vaulted)的令牌化方案,频繁查询令牌库进行数据“去令牌化”会增加网络往返次数,对高性能应用构成挑战。
5. 替代方案的竞争
RegData语义保护并非唯一的解决方案。金融服务业正在探索多种技术路径以应对AI数据安全挑战,这些方案在不同场景下可能更具优势:
| 替代方案 | 核心优势 | 相对RegData的考量 |
|---|---|---|
| 联邦学习 (Federated Learning) | 原始数据不出本地,从源头避免数据集中存储的风险。 | 适用于模型共建场景,但无法解决单个机构内部数据分析的保护问题。通信开销和模型聚合的复杂性较高。 |
| 同态加密 (Homomorphic Encryption) | 允许在密文上直接进行计算,提供理论上最高的安全性。 | 计算开销极大,目前主要处于学术研究和特定场景应用阶段,距离大规模商业化应用尚有距离。 |
| 差分隐私 (Differential Privacy) | 提供可数学证明的隐私保护保证,常用于公开发布的统计数据。 | 引入的噪声会影响数据精度,在个体数据分析和精确模型训练上效用损失较大。 |
| 去中心化AI系统 | 数据在本地处理,降低了中心化服务器的数据泄露风险。 | 适用于边缘计算场景,但增加了设备管理和一致性维护的复杂性。 |
| 人机协同与人工干预 | 在高风险决策中保留人类监督,提高系统的可控性和可靠性。 | 是一种治理策略而非技术方案,可以与RegData等技术互补,但无法替代底层数据保护。 |
结论与展望
RegData语义保护体系无疑代表了AI时代数据安全的前进方向。它通过将“理解”引入数据保护流程,实现了从被动防御到主动治理、从价值破坏到价值保留的深刻转变,为金融服务等高度监管行业在拥抱AI创新和恪守数据安全之间架起了一座关键桥梁。
然而,我们也必须清醒地认识到,该体系并非“银弹”。其高昂的实施成本、对核心模型的高度依赖、潜在的性能瓶颈以及来自联邦学习等其他先进技术的竞争,都是决策者必须审慎评估的因素。
展望未来,该技术方向的成熟将依赖于以下几点:
- 标准的建立:行业需要推动格式保留加密/令牌化和语义保护框架的标准化,以增强互操作性和安全性。
- 技术的普及:随着更高效、更经济的嵌入模型和NLP技术的发展,实施门槛和成本将逐步降低。
- 生态的融合:语义保护能力将更多地作为云原生数据库和数据治理平台的内置功能出现,而非一个独立的、需要复杂集成的系统。
最终,成功的智能AI就绪企业将采用一个多层次、综合性的数据安全策略,而RegData所倡导的语义保护,必将在这个防御体系中扮演至关重要的角色。
参考文献
- MongoDB, Inc. Data Protection and Modernization for Highly Regulated Industries. MongoDB. Accessed September 19, 2025. https://www.mongodb.com/collateral/regdata-protection-suite
- MongoDB, Inc. Securing Digital Transformation for Financial Services. MongoDB. Accessed September 19, 2025. https://www.mongodb.com/blog/post/securing-digital-transformation-for-financial-services-with-mongodb-and-regdata
- RegData. Kustodyan. RegData. Accessed September 19, 2025. https://regdata.ch/
- Juejin. 数禾科技-基于 Flink 的实时数仓平台实践. Juejin. Accessed September 19, 2025. https://juejin.cn/post/7118206972048834573
- Ubiq Security. Tokenization vs Encryption: Critical Differences & Key Similarities. Ubiq Security. Accessed September 19, 2025. https://www.ubiqsecurity.com/blog/tokenization-vs-encryption-critical-differences-key-similarities/
- Cloud Security Alliance. Data Protection and Privacy. Cloud Security Alliance. Accessed September 19, 2025. https://cloudsecurityalliance.org/research/artifacts/data-protection-and-privacy/
- IBM. What is tokenization? IBM. Accessed September 19, 2025. https://www.ibm.com/topics/tokenization
- Slogix. Privacy-Preserving NLP in Finance. Slogix. Accessed September 19, 2025. https://www.slogix.in/blog/privacy-preserving-nlp-in-finance
- ResearchGate. A Review on Semantic Disclosure Control. ResearchGate. Accessed September 19, 2025. https://www.researchgate.net/publication/329587425_A_Review_on_Semantic_Disclosure_Control
- Secrss.com. 多重挑战下的金融行业AI数据安全破局之道. Secrss.com. Accessed September 19, 2025. https://www.secrss.com/articles/65593
- Altr. What is Format-Preserving Encryption (FPE)? Altr. Accessed September 19, 2025. https://www.altr.com/blog/what-is-format-preserving-encryption-fpe-a-complete-guide
- Fortanix. Tokenization vs. Encryption. Fortanix. Accessed September 19, 2025. https://www.fortanix.com/blog/2021/04/tokenization-vs-encryption
- Haitai China. 我国在保留格式加密(FPE)算法研究方面取得突破. Haitai China. Accessed September 19, 2025. http://www.haitaichina.com/news/1628.html
- Professional Adviser. FCA's increased RegData demands 'adding to adviser burden'. Professional Adviser. Accessed September 19, 2025. https://www.professionaladviser.com/news/4037597/fca-increased-regdata-demands-adding-adviser-burden
贡献者
 pansin
pansin