大模型驱动安全左移:在BRD与PRD阶段构建原生作业安全
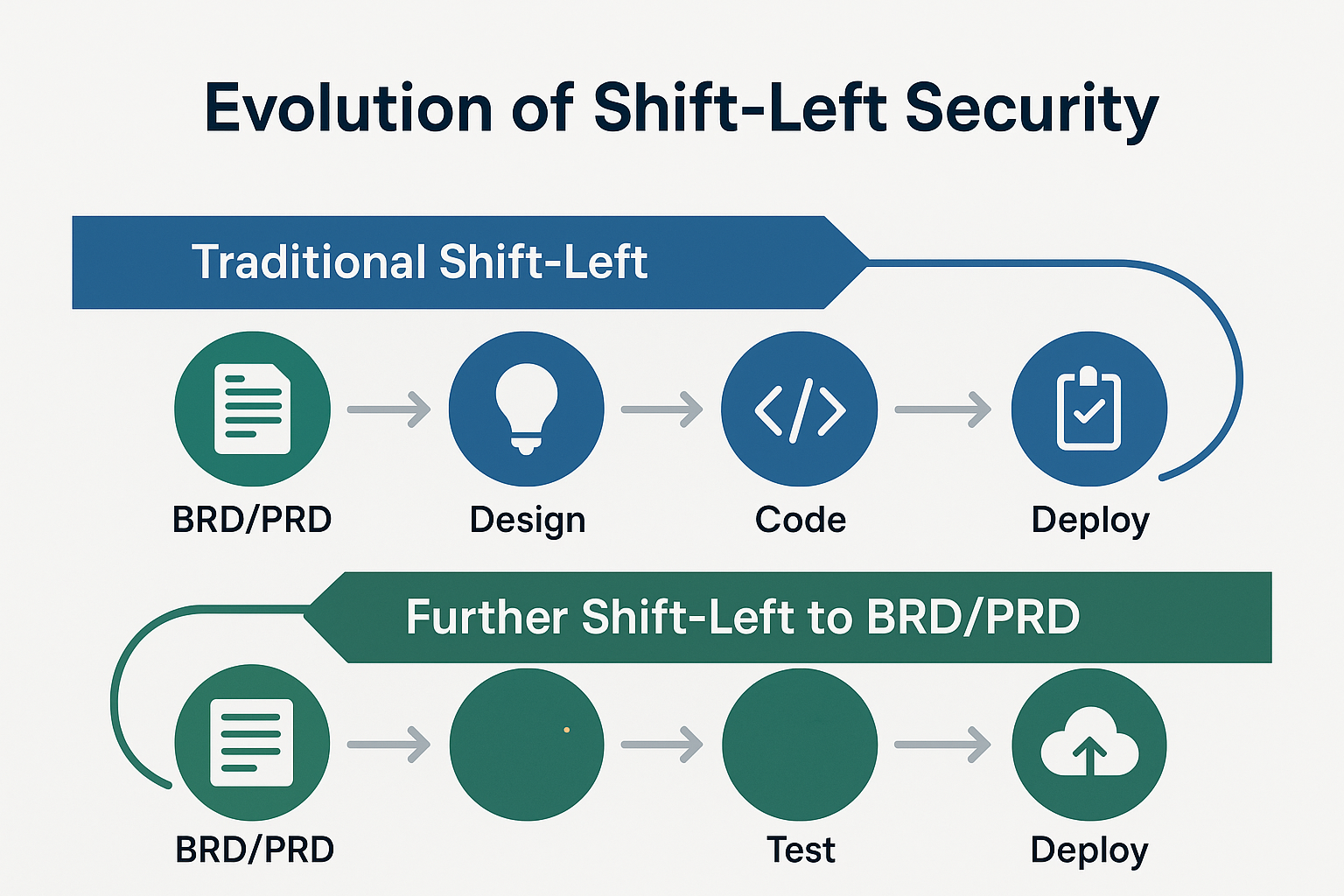
1. 引言:超越传统的“安全左移”
1.1 传统DevSecOps中“安全左移”的现状与局限
"安全左移"(Shift Left Security)是DevSecOps的核心理念,它提倡将安全测试和考量从软件开发生命周期(SDLC)的后期(如部署阶段)提前到早期阶段。
然而,传统的“安全左移”实践通常将安全活动前置到编码与持续集成/持续交付(CI/CD)环节。尽管这已是巨大进步,但仍存在显著局限:
- 为时已晚:当安全团队介入时,产品的核心架构、业务逻辑和数据流已经基本定型。此时发现的设计层面的安全缺陷,修复起来如同给高速行驶的列车更换引擎,技术难度和成本极高。
- 成本高昂:据研究,在设计阶段修复一个安全缺陷的成本,仅为在生产环境中修复成本的几十分之一甚至百分之一。传统左移错过了成本效益最高的干预窗口。
- 被动修复,治标不治本:该阶段的安全活动(如SAST/DAST)主要关注代码层面的具体漏洞,而对源于业务逻辑或产品设计本身的系统性风险(如越权访问、业务欺诈风险)则力不从心。
1.2 “进一步左移”:构建原生安全的必要性
真正的原生安全(Native Security)要求我们将安全思维**“进一步左移”**,前置到一切的源头——商业需求文档(BRD)和产品需求文档(PRD)阶段。这是一种范式转变,从“在开发中构建安全”演进为“在设计中内建安全”(Security by Design)。
核心价值:
- 源头预防:在业务构思和产品设计之初,就系统性地识别、评估并规避安全风险,如同为建筑绘制蓝图时就考虑防火与结构安全。
- 成本效益最大化:以最低的沟通和修改成本消除设计层面的安全隐患,避免后期昂贵的架构重构和代码重写。
- 构建安全韧性:让安全不再是附加(add-on)功能,而是产品与生俱来的DNA,从而构建一个更具韧性的业务体系。
1.3 核心议题:大模型(LLM)作为变革的驱动力
过去,在需求阶段进行全面、深入的安全评估之所以困难,是因为它高度依赖资深安全专家的手动分析,耗时耗力且难以规模化。如今,大型语言模型(LLM)的出现为我们提供了历史性的机遇。
凭借其卓越的自然语言理解(NLU)、上下文推理和知识整合能力,LLM能够自动化、规模化地“阅读”和“理解”BRD/PRD文档。本文旨在系统性地阐述如何构建一个由大模型驱动的自动化评估框架,将安全分析能力赋能给产品和业务团队,从而在需求源头实现真正的原生安全。
2. 理论基础与理念融合
我们的框架并非凭空创造,而是建立在业界成熟的安全理论之上,并创造性地融合了隐私保护领域的先进理念。
2.1 设计即安全(Security by Design, SbD):原生安全的指导思想
“设计即安全”是构建原生安全的基石。它要求我们将安全作为系统设计的内在属性,而非事后补救。这一思想具体化为五大支柱,确保了作业安全在设计阶段就得到全面考虑。
- 实体认证 (Entity Authentication):确保所有参与作业的实体(用户、服务、设备)都经过严格的身份验证。
- 行为校验 (Behavior Validation):对实体的操作行为进行合法性校验,防止越权和滥用。
- 数据保密与完整性 (Data Confidentiality & Integrity):在数据传输和存储的全生命周期中保护其不被窃取或篡改。
- 安全运营数据的记录与采集 (Operational Data Logging):这是实现可追溯性和事后审计的基础。它要求系统设计必须明确记录下所有关键操作的“谁(Who)、什么时间(When)、从哪里(Where)、做了什么(What)、结果如何(How)”等核心要素。这些日志不仅是应对安全事件、进行数字取证的关键依据,更是通过大数据分析进行主动威胁发现和异常行为检测的宝贵数据源。在LLM评估框架中,Agent会检查PRD是否对关键功能的日志记录级别、内容和格式提出了明确要求。
- 作业过程元数据的采集与处理 (Process Metadata Collection):元数据是操作的上下文信息,它超越了基础的操作日志。例如,一次API调用不仅要记录其请求和响应,还应采集其关联的业务流程ID、来源IP的信誉分、用户设备指纹、调用链路信息等。这些丰富的上下文元数据对于高级威胁分析至关重要,能够帮助安全系统区分是正常的业务操作还是精心伪装的攻击行为。我们的LLM Agent会评估产品设计是否考虑了这些高价值元数据的采集机制,以支持更深层次的风险控制和智能决策。

2.2 威胁建模(Threat Modeling):在需求阶段的早期应用
威胁建模是系统性识别风险的有效工具。传统上,它应用于技术架构层面,但其思维框架完全可以应用于分析非技术性的需求文档。我们将借鉴经典方法论,并将其转化为LLM可理解的分析维度:
- STRIDE模型:
- 欺骗 (Spoofing):用户身份认证机制是否健全?
- 篡改 (Tampering):关键数据的传输和存储过程是否设计了防篡改措施?
- 抵赖 (Repudiation):是否有充分的日志和审计设计来确保操作不可否认?
- 信息泄露 (Information Disclosure):数据分类和访问控制设计是否严谨?
- 拒绝服务 (Denial of Service):核心功能是否存在被滥用导致服务不可用的风险?
- 权限提升 (Elevation of Privilege):不同权限角色的用户之间是否存在逻辑上的越权路径?
2.3 借鉴隐私保护理念:从PbD到SbD的演进
隐私保护领域经过多年发展,形成了一套成熟的“事前预防”体系。我们创造性地将其理念和流程应用于通用安全领域:
- PIA → SIA:将“隐私影响评估”(Privacy Impact Assessment, PIA)的系统化流程,转化为“安全影响评估”(Security Impact Assessment, SIA)。在每个新功能或产品规划之初,就评估其对现有安全体系的潜在冲击。
- PbD → SbD:将“基于隐私的设计”(Privacy by Design, PbD)所倡导的主动性、预防性、全生命周期保护的理念,深化为“基于安全的设计”(Security by Design, SbD),确保安全考量贯穿产品始终。
3. 核心框架:大模型驱动的BRD/PRD安全评估三步法
我们提出一个由LLM驱动的三步法框架,旨在将BRD/PRD文档自动转化为可执行的安全需求和设计指南。
3.1 第一步:建立评估基线(Ground Truth)
为了让大模型能够进行专业、准确的评估,必须为其提供一个高质量的“评估基线”或知识库。这相当于为LLM装备了一位资深安全专家的“大脑”。
- 安全规则库:基于OWASP Top 10、NIST等行业标准,结合企业内部的安全策略和红线,形成结构化的安全设计规则。
- 威胁模型知识库:将STRIDE等威胁建模方法论转化为具体的、可供LLM检查的风险点(Checkpoints)。
- 历史漏洞与案例库:整理内外部典型的安全事件、设计缺陷案例,作为“反面教材”,让LLM学习“什么样的设计会导致问题”。
- 合规性要求库:整合GDPR、CCPA、中国《个人信息保护法》等法律法规中与产品设计和数据处理相关的条款。
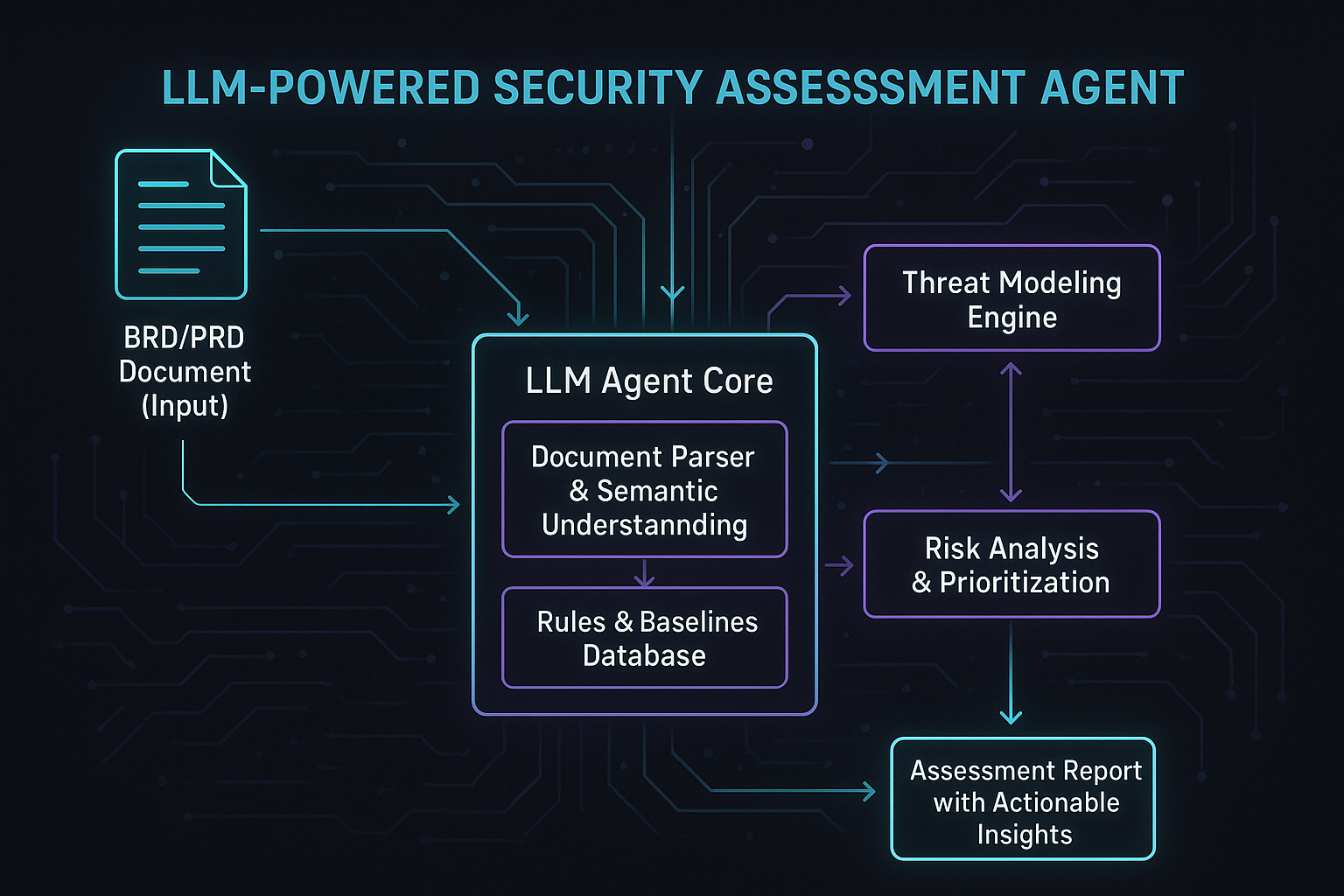
3.2 第二步:构建大模型驱动的评估Agent
这是框架的核心执行引擎,一个专门用于安全评估的智能体(Agent)。它通常基于检索增强生成(RAG)架构构建。
文档解析与理解:Agent首先接收BRD/PRD文档(可支持Markdown、Word、Confluence页面链接等多种格式),利用LLM强大的NLU能力,解析文档中的核心要素,如:
- 业务目标与流程
- 功能模块与用户故事
- 用户角色与权限定义
- 数据实体与数据流
风险识别与推理:结合第一步建立的评估基线,Agent对解析出的内容进行多维度分析,识别潜在风险。例如:
- “用户仅凭手机号即可重置密码” -> 匹配到“身份认证薄弱”规则 -> 识别为设计缺陷。
- “新推出的优惠券功能,用户可无限领取” -> 匹配到“业务逻辑滥用”案例 -> 识别为业务逻辑风险。
- “收集用户精确地理位置用于推荐” -> 匹配到“数据最小化”合规要求 -> 识别为合规性风险。
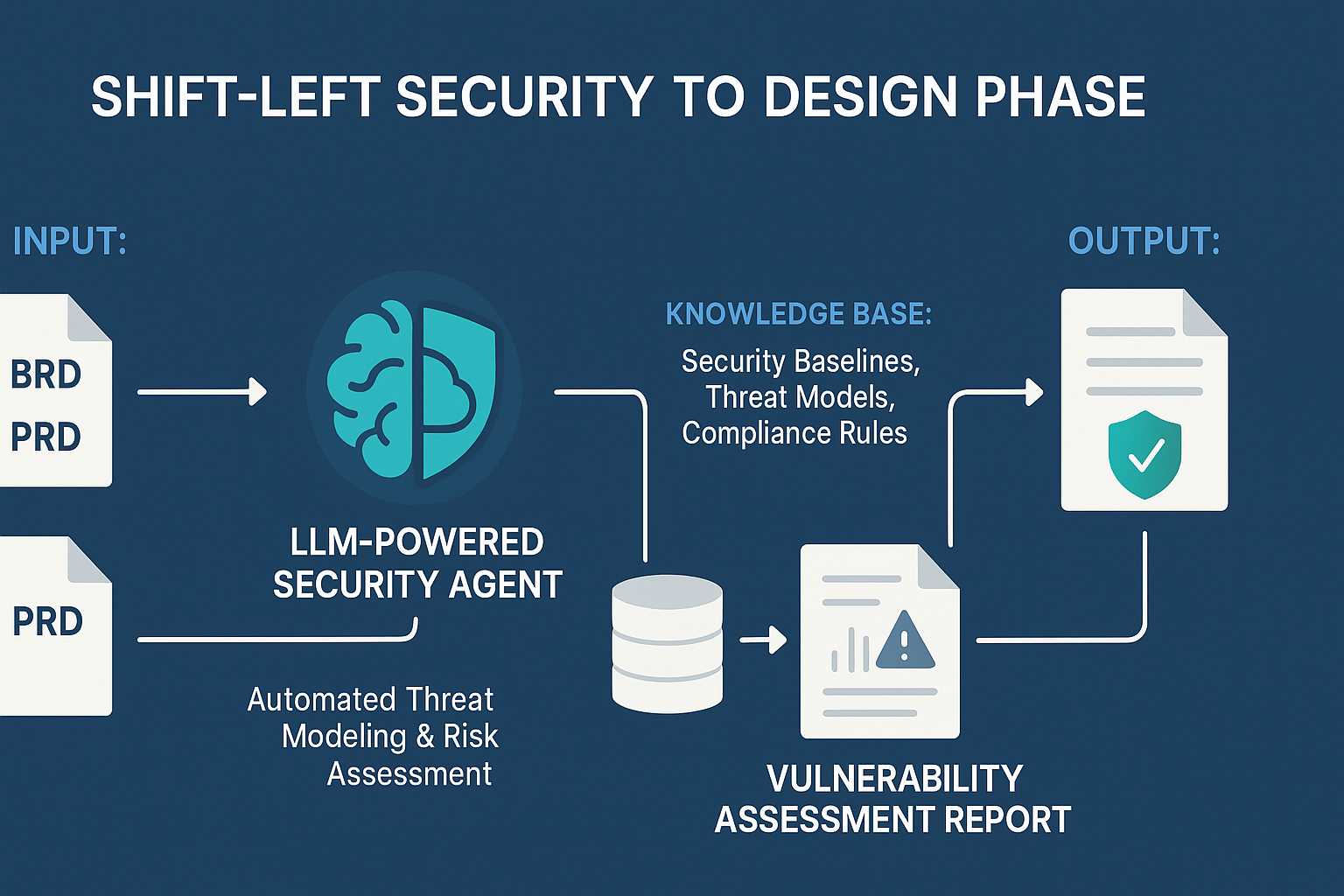
- 生成结构化评估报告:Agent将分析结果整理成一份清晰、可操作的结构化报告,而非泛泛而谈的建议。
| 报告要素 | 描述 | 示例 |
|---|---|---|
| 风险摘要 | 总体安全风险评级和关键问题概览。 | 高风险:2个,中风险:4个,低风险:1个 |
| 风险详情 | 逐条列出风险点、所属类别(如STRIDE分类)、威胁等级。 | 风险点:用户密码重置功能;类别:欺骗(Spoofing) |
| 风险描述 | 详细说明风险的具体表现形式和可能造成的危害。 | 仅通过手机验证码即可重置密码,若短信被劫持,账户将被盗用。 |
| 定位与证据 | 在原始文档中高亮或引用相关段落,方便产品经理快速定位。 | PRD文档,第5.3.2节:“用户输入手机号和验证码,验证通过后即可设置新密码。” |
| 修复建议 | 提供具体、可操作的安全设计或策略建议,而非空洞的原则。 | 建议增加第二重验证,如安全问题、邮箱验证码或原密码验证。 |
3.3 第三步:安全设计的闭环与整合
生成报告不是终点,将洞察转化为行动才是关键。
- 报告分发与协同:评估报告自动通过Jira、飞书等协作工具推送给相关的产品经理、技术负责人和安全工程师。
- 需求修订:产品经理根据报告中的具体建议,直接修订BRD和PRD文档,将安全要求内化为产品需求。
- 生成“安全增强版”文档:修订后的PRD成为一份内嵌了安全设计考量的“黄金标准”文档,指导后续的开发、测试和上线。
- 持续迭代:当需求发生变更或迭代时,自动重新触发评估流程,形成一个动态、持续的安全保障闭环,确保安全贯穿始终。
4. 实施路径与挑战
4.1 技术实施步骤
- 知识库构建:这是最基础也是最重要的工作。投入资源收集并结构化企业内外的安全知识。
- Prompt工程:设计高效、精准的提示词(Prompt),引导LLM进行逻辑严密的文档分析和风险推理。
- Agent开发与集成:开发评估Agent,并与企业内部的文档平台(Confluence、Notion)和项目管理工具(Jira)深度集成,实现自动化流程。
- 试点与优化:选择1-2个典型项目进行试点,收集产品和研发团队的反馈,持续优化模型、Prompt和知识库。
- 推广与赋能:在组织内逐步推广此框架,并对产品、研发团队进行赋能培训,使其掌握“设计即安全”的思维方式。
4.2 面临的挑战
- 知识库的质量:评估基线的准确性和覆盖度直接决定了评估效果的上限。
- LLM的“幻觉”问题:大模型可能产生误报或漏报,需要引入校验机制。
- 上下文理解深度:对于极其复杂或隐含的业务逻辑,LLM的理解能力仍有待提升。
- 跨部门协作的阻力:这不仅是技术变革,更是工作流程和文化的变革,需要管理层推动,打破部门墙。
- 模型自身的安全性:需警惕OWASP发布的“大语言模型应用十大风险”,如提示词注入、数据泄露等。
5. 人机协同与持续优化
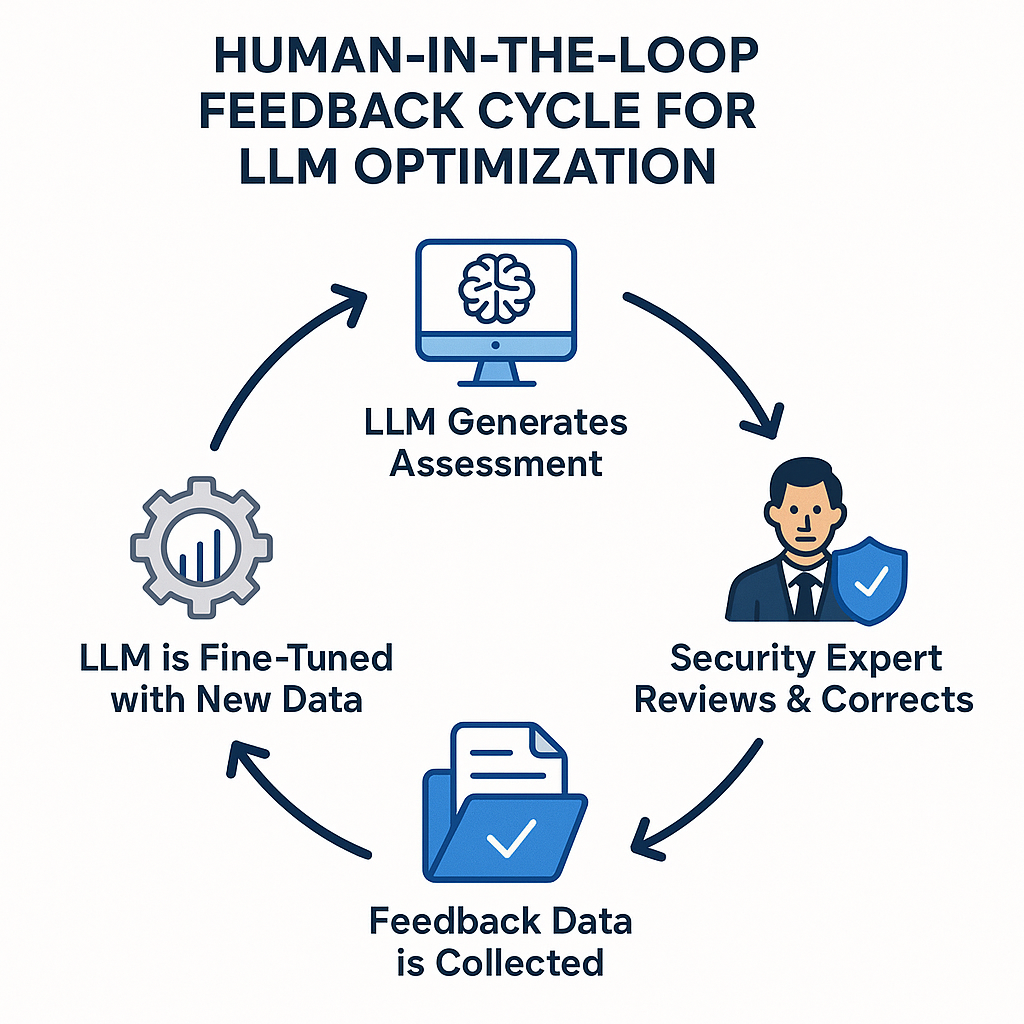
尽管LLM评估框架功能强大,但它并非一个可以一劳永逸的“银弹”。为了应对LLM固有的“幻觉”问题、弥补其对复杂业务上下文理解的不足,并确保评估结果的高质量,我们必须引入“人机协同”(Human-in-the-Loop, HITL)机制,构建一个持续优化的正反馈闭环。
该闭环是确保模型不断进化、越来越贴合企业实际业务场景的关键:
- LLM生成评估 (LLM Generates Assessment):自动化Agent对新的BRD/PRD进行分析,生成初步的安全评估报告。
- 安全专家审核与修正 (Security Expert Reviews & Corrects):资深安全专家对LLM生成的报告进行审核。他们不仅要验证发现的风险点是否准确(标记误报或漏报),更重要的是,他们会凭借深厚的业务理解和安全经验,对评估结果进行补充和修正,增加LLM无法推理出的深层见解。
- 收集反馈数据 (Feedback Data is Collected):系统将专家的修正操作(例如,将某个“低风险”标记为“高风险”并附上理由)结构化地记录下来。这些高质量、经人工验证的数据构成了宝贵的“养料”。
- 模型微调与优化 (LLM is Fine-Tuned with New Data):积累的反馈数据被用于定期对基础模型进行微调(Fine-tuning)或优化提示工程(Prompt Engineering)。这个过程相当于让LLM“拜师学艺”,不断从人类专家的决策中学习,从而提升其未来评估的准确性和深度。
通过这一持续迭代的循环,LLM评估模型将从一个通用的分析工具,逐步进化为企业专属的、高度定制化的安全专家助手,实现评估质量和效率的螺旋式上升。
6. 结论:开启业务安全的新范式
大模型的出现,首次为在需求源头实现自动化、规模化的深度安全分析提供了可能。这不仅是传统“安全左移”理念的一次质的飞跃,更是通向“原生安全”的现实路径。
通过在BRD和PRD阶段就注入安全DNA,并结合人机协同的持续优化机制,我们能够从根本上消除设计层面的脆弱性,构建出真正“设计即安全”(Security by Design)的产品和服务体系。这不仅能大幅降低安全成本、提升开发效率,更将从本质上增强企业的业务韧性和市场竞争力,开启一个全新的业务安全范式。
7. 参考文献
- [1] OWASP. (2023). OWASP Top 10 for Large Language Model Applications.
- [2] Microsoft. The Security Development Lifecycle (SDL).
- [3] Cavoukian, A. (2009). Privacy by Design: The 7 Foundational Principles.
- [4] National Institute of Standards and Technology (NIST). Cybersecurity Framework.
- [5] Shostack, A. (2014). Threat Modeling: Designing for Security.
贡献者
 pansin
pansin