摘要
犯罪相关事件(CRE)的自动化识别与分析,特别是在网络安全和执法领域,已成为信息时代应对犯罪活动的关键技术环节。本文系统性地阐述了CRE识别的理论基础、核心技术方法、多样化的实际应用场景、当前的研究进展以及未来的发展趋势。自然语言处理(NLP)技术在从海量文本数据中准确提取CRE方面扮演着核心角色,但也同时面临着诸如深层语义理解、隐晦表达识别以及多语言环境下(尤其是低资源语言)信息处理的诸多挑战。通过对现有研究和实践的梳理,本文希望为相关领域的研究人员和实践者提供一个全面而深入的参考框架,以推动该领域的进一步发展。
引言
在信息技术飞速发展的今天,数字信息的产生和传播呈现爆炸式增长。这些信息,特别是来源于互联网、社交媒体等平台的半结构化和非结构化文本数据,往往蕴藏着大量与各类犯罪活动相关的线索和证据。准确、高效地从这些海量数据中识别、提取并分析“犯罪相关事件”(Crime-Related Events, CRE),对于提升犯罪预防能力、增强执法效能以及维护社会与网络安全具有日益凸显的重要性与紧迫性[1, 2]。
CRE 通常被定义为通过自然语言处理(NLP)和文本分析技术,从文本数据中自动识别、提取和分析的与犯罪活动相关的特定信息片段。值得强调的是,CRE 的界定并不仅仅是关键词的简单匹配,而是需要深度结合法律要素,例如明确犯罪主体(perpetrator)、犯罪客体(victim/object)以及客观行为(action/event),并致力于从原始文本中抽取出结构化的事实[1]。这种结构化事实常以三元组(如“主体→谓词→客体”)或其他预定义模式来表示,例如“张三(主体)→盗窃(谓词)→钱包(客体)”。这种对法律相关性和信息可用性的高度关注,构成了CRE识别与分析的技术目标和实践基础。
从更深层次来看,CRE识别的本质是一项知识发现与转化的过程。它始于海量的、通常是非结构化的文本数据,通过一系列复杂的NLP技术处理,最终目标是提取出能够被机器理解、易于进一步分析和利用的“结构化事实”。这些结构化事实本身就是一种知识的凝练表达。因此,CRE识别远不止于文本层面的模式匹配,它更是一座桥梁,将原始的、非结构化的数据转化为具有明确语义、可支持决策的知识[1]。
这种从数据到知识的转化,也反映了情报工作中一个重要的趋势——即从关注零散的“数据点”或“潜在信号”向发掘高质量“情报”的转变[1, 6]。传统的文本分析方法可能仅仅停留在发现某些“潜在犯罪信号”的层面,例如识别出一些敏感词汇。然而,现代CRE分析技术则更加强调提取那些包含了明确法律要素的“犯罪事实”[1]。相较于模糊的“信号”,“事实”因其更高的确定性和可操作性,更接近于“情报”的核心概念。这种转变意味着对信息分析的质量和应用深度提出了更高的要求,其最终目的是为了更直接、更有效地支持执法机构的预防策略制定和具体行动部署[6]。
本文将围绕CRE识别与分析这一核心议题,从理论基础、关键技术与实践方法、跨语言处理的挑战与进展、实际应用价值、前沿研究动态以及未来发展趋势等多个维度展开全面而深入的探讨。旨在为相关领域的研究人员、技术开发者以及一线从业人员提供一份内容翔实、逻辑清晰的参考,以期共同推动该领域的理论创新与技术进步。
第一章:犯罪相关事件(CRE)识别与分析的理论基础
犯罪相关事件(CRE)的识别与分析高度依赖于计算机对人类自然语言的理解和处理能力。本章将探讨支撑这一领域发展的核心理论,并剖析传统信息处理方法所面临的局限性。
1.1 自然语言处理(NLP)的核心作用与基础概念
在当今信息爆炸的时代,海量的数字文本数据(来源于互联网、社交媒体、新闻报道、内部记录等)蕴藏着识别和分析犯罪活动的关键线索[1, 6]。自然语言处理(NLP)是实现从这些非结构化或半结构化文本中自动、高效地识别、提取和分析CRE的基石技术。NLP赋予计算机理解、解释和生成人类语言的能力,其核心目标在于跨越人类语言与机器理解之间的鸿沟。
在CRE识别任务中,NLP技术流程通常包括多个关键环节:
- 文本预处理: 这是处理的起点,包括分词(将文本切分成独立的词或词组)、词性标注(确定每个词的词类,如名词、动词、形容词)、命名实体识别(NER,识别文本中具有特定意义的实体,如人名、地名、组织机构名、时间、工具等)。这些步骤旨在从原始文本中识别出最基本的语言单元及其属性。
- 句法分析: 确定句子中词语之间的语法关系和句子整体结构,例如主谓宾关系、修饰关系、依存关系等。这有助于理解事件的参与者和动作之间的结构联系。
- 语义理解: 这是NLP最核心也是最具挑战性的部分,旨在理解文本的真正含义。在CRE识别中,语义理解包括:
- 词义消歧: 确定一个多义词在特定上下文中的准确含义。
- 指代消解: 确定代词(如“他”、“她”、“它”、“他们”)或名词短语所指代的对象。
- 语义关系判断: 理解实体(如人、物)与动作之间的深层关系(如谁做了什么、作用于谁或什么)。
- 事件论元抽取: 识别并确定与特定事件(如“盗窃”)相关的参与者(Agent, Object)和属性(时间、地点、工具)在文本中的具体表达[1]。
 图 1.1:基于自然语言处理的犯罪相关事件识别工作流程图。该图展示了文本预处理、特征提取、识别与分析等关键步骤。
图 1.1:基于自然语言处理的犯罪相关事件识别工作流程图。该图展示了文本预处理、特征提取、识别与分析等关键步骤。
有效执行这些复杂的NLP任务,是准确识别和抽取CRE各个构成要素并理解其内在逻辑的前提。没有NLP对语言细致入微的解析,将难以从海量、复杂的文本中抽取出有价值的犯罪相关信息。
1.2 逻辑-语言模型(Logic-Linguistic Models)
为了更精确地从文本中提取符合法律要素的结构化犯罪事实,研究者们提出了逻辑-语言模型。这类模型的核心思想是基于预定义的语法规则和语义模式来识别和抽取信息,而非仅仅依赖关键词的出现频率。它们强调理解词语在句子结构中的作用以及它们之间的逻辑关系,致力于从原始文本中抽取出能够被机器理解、易于进一步分析和利用的“结构化事实”[1]。
这种模型是对传统“关键词袋”(bag-of-words)等浅层文本表示方法的超越。传统方法往往忽略词序和句法结构,仅简单统计关键词频率,难以应对自然语言的复杂性和表达的多样性。逻辑-语言模型通过引入“语法和语义规则”进行“事实提取”,更加关注句子内部的结构信息以及词汇单元之间的逻辑关联[1]。
逻辑-语言模型的关键特点:
- 规则驱动: 依赖由语言学家或领域专家构建的形式化规则或模板。
- 结构感知: 能够识别和利用文本的句法结构信息。
- 语义约束: 结合语义信息(如词义、语义角色)来提高抽取的准确性。
- 目标明确: 旨在提取具有特定结构(如三元组:主体→谓词→客体)的事实信息。
优势:
逻辑-语言模型能够有效解决同一犯罪事实因语言表达的多样性(例如主动语态与被动语态的转换、“他/她/它”等代词的具体指代对象)而难以被准确捕捉的问题。这对于提升CRE识别的准确率和召回率,尤其是在处理句式复杂、信息隐含的文本时,起到了关键性的作用[1]。它使得CRE识别技术从简单的模式匹配,向着对语言结构和语义逻辑的更深层次理解迈进。
1.3 传统CRE信息处理方法的局限性分析
尽管CRE识别与分析的需求日益迫切,但传统的、基于浅层文本分析的信息处理方法在应对这一复杂任务时,暴露了诸多局限性:
- 过度依赖显性威胁词汇: 许多传统方法,如基于关键词列表的匹配或简单的基于词典的情感分析,高度依赖文本中是否出现明确的、预先定义的威胁性词汇或短语。然而,犯罪分子在交流时可能采用间接术语、俚语、隐喻,或者其表达方式受到特定文化背景的影响,这些都使得依赖显性词汇的方法难以有效识别潜在的犯罪相关信息[1]。
- 缺乏深层语义理解能力: 这些传统方法通常停留在文本的表层特征,缺乏对文本背后深层语义的理解能力。它们难以准确把握犯罪的真实意图、事件的完整上下文联系,以及不同信息片段之间的逻辑链条。例如,一句看似平常的话,在特定语境下可能暗示着某种犯罪预谋,这是简单词汇匹配无法洞察的。
- 结构化事实提取困难: 从非结构化或半结构化的文本中高效、准确地提取出结构化的犯罪事实(例如,明确犯罪主体是谁、实施了什么行为、侵害了哪个客体、事件发生的时间和地点分别是什么等核心要素)对传统方法而言是一个巨大挑战[1]。缺乏结构化的信息,使得后续的分析、关联和决策支持变得非常困难,信息利用价值大打折扣。
- 多语言处理的严重挑战: 犯罪活动具有跨国界、跨语言的特点。然而,大多数NLP工具和资源在高资源语言(如英语)中较为成熟,而在许多低资源语言(如文档中提及的哈萨克语)中则严重匮乏。缺乏成熟的NLP基础工具(如分词器、词性标注器、句法分析器)和大规模高质量的标注语料库,使得在这些语言环境下开展CRE的识别与分析工作举步维艰[1, 2]。低资源语言面临的技术能力缺失,可能导致使用这些语言的社群在犯罪预防和打击方面处于信息不对称的不利地位[1]。
1.4 从“信号”到“情报”:CRE定义演进的逻辑
传统的信息处理方法往往满足于识别一些**“潜在犯罪信号”**,例如发现文本中出现了某些敏感词汇。这类“信号”的情报价值相对较低,且不确定性较高,需要大量的人工后续甄别和分析[1, 6]。
现代CRE分析技术则更加强调**“结合法律要素(如犯罪主体、客体、客观行为)来定义犯罪信息”,并致力于提取“结构化事实(如三元组:主体→谓词→客体)”**[1]。这种经过结构化处理、并且蕴含了明确法律要素的信息,其情报价值远非模糊的“信号”所能比拟。因为结构化事实更接近于直接可用的证据或高可信度的线索,能够为执法部门的决策和行动提供更为坚实和精准的支持[6]。
这一转变反映了情报工作中从关注零散的“数据点”向发掘高质量**“情报”**的趋势。CRE识别远不止于文本层面的模式匹配,它更是一座桥梁,将原始的、非结构化的数据转化为具有明确语义、可支持决策的知识[1]。
第二章:CRE识别与分析的关键技术与实践方法
在坚实的理论基础之上,CRE的识别与分析依赖于一系列关键技术和实践方法。这些技术旨在从不同层面解析文本,提取与犯罪相关的核心信息,并将非结构化数据转化为可供进一步分析和应用的高价值结构化情报[1]。
2.1 基于语义基准的识别方法
基于语义基准的识别方法是CRE信息提取的重要途径之一[1]。这类方法通常依赖于预先构建的、包含语义标注的犯罪相关文本语料库,并结合形态标记(如词性、词形变化)和专门的语义词典(例如,包含各类犯罪术语、黑话、隐语的词典)来进行。这种方法的核心在于利用语义信息来判断文本片段是否与犯罪相关以及关联的紧密程度。文档中提及了三种具体的语义处理技术[1]:
- 手动属性分配: 指由领域专家或经过培训的标注人员根据预定义的标准,对文本中的词汇、短语或句子手动赋予其在犯罪事件中的语义角色或属性(如施事者、受害者、作案工具、时间、地点等)。尽管这种方法耗时耗力、成本较高,但它在构建高质量的黄金标准标注数据、训练和验证自动化识别模型方面具有不可替代的作用。高质量的标注数据是后续所有数据驱动方法的基础,也是评估规则驱动方法性能的基准[1]。
- 频率词典分析: 这种技术通过统计特定词汇或短语在已知犯罪相关文本(正样本)和非犯罪相关文本(负样本)中出现的频率差异,来识别那些更倾向于指示犯罪事件的词汇。然而,这种方法容易受到词汇歧义和表达多样性的影响,其准确性有一定局限性,属于较浅层的语义分析[1]。
- 潜在语义分析 (LSA): LSA是一种更为先进的统计和机器学习方法。它旨在通过分析大量文本数据中词汇的共现模式,来发现词汇之间潜在的、深层次的语义关联,即使这些词汇在表面上没有直接共同出现[1]。在CRE识别中,LSA可以帮助识别与已知犯罪概念相关的语义标记,即便它们没有在预定义的犯罪术语词典中明确列出。通过构建词汇的向量空间表示,LSA能够计算词汇、句子乃至文档之间的语义相似度,从而增强文本分类(判断文本是否与犯罪相关)和事件关联性分析(判断不同信息片段是否指向同一犯罪事件)的能力,这在一定程度上超越了简单的基于词频的统计,能够捕捉到一些隐含的语义联系[1]。
2.2 触发词检测技术及其多语言应用
触发词(Trigger Word)通常是指那些能够强烈指示某种特定类型事件发生的词汇或短语[1]。在CRE识别领域,触发词检测是一项关键的初步筛选技术。例如,“爆炸”、“枪击”、“盗窃”、“逮捕”等词很可能触发对相应犯罪事件的识别[1]。
为了实现有效的触发词检测,构建高质量、广覆盖的多语言同义词词典至关重要。文档中提及了Salas等人(2020年)构建的一个此类词典,该词典不仅包含了约600个核心犯罪相关词汇,还扩展了约2500个在英语、哈萨克语、乌克兰语和俄语中的多语言同义词,覆盖了包括人身伤害(INJURE)、逮捕(ARREST)、交通事故(TRAFFIC ACCIDENT)在内的7个主要犯罪主题类别[1]。
触发词检测的作用:
- 快速定位: 使得系统能够通过识别文本中的这些触发词及其变体,快速定位可能包含CRE的文本片段[1]。
- 初步分类: 基于检测到的触发词,对事件类型进行初步分类[1]。
- 引导后续分析: 触发词是引导后续更深层次事件要素提取和结构分析的“路标”[1]。
构建和维护这样的多语言触发词典是支持跨语言CRE识别的基础工作之一。
2.3 逻辑语言方程(LLEs)在事件模式定义与信息抽取中的应用
仅仅识别出触发词并不足以完整理解一个犯罪事件。一个完整的CRE需要识别出事件的参与者、属性以及它们之间的关系[1]。逻辑语言方程(Logical Language Equations, LLEs)的引入,旨在更精确地定义特定事件子类型的内在模式,并描述事件中各个参与者角色(例如,犯罪行为的发起者Agent、受作用对象Object)与文本中特定语法特征(如词性、语态、句法依存关系)和语义特征(如词义、语义角色)之间的复杂对应关系[1]。
LLEs 可以被看作是一系列形式化的规则或模板。它们规定了构成一个特定犯罪事件(如“抢劫”)所必需的元素组合及其在语言表达上的特征。例如,一个针对“抢劫”事件的LLE可能会定义:需要一个表示“暴力夺取”的动词(作为触发词),一个表示“人”的名词作为施事者(Agent),一个表示“财物”的名词作为受事者(Object),以及可能的地点状语等。LLE会进一步指定这些词语在句子中可能出现的句法位置或它们之间的句法依存关系[1]。
通过匹配这些LLEs,系统不仅能够确认事件的发生,还能准确地抽取出事件的关键参与者和属性信息。因此,LLEs 在实现从简单的触发词识别到对完整事件结构和语义的理解方面,扮演了重要的桥梁角色,显著提升了事件信息抽取的精度和完整性[1]。它们结合了语言学家的先验知识,能够处理复杂的句式和语言现象,是规则驱动方法在CRE识别中的核心体现。
2.4 CRE的分类体系与结构化表示
为了对识别出的CRE进行系统化的管理和分析,建立一套清晰的分类体系和统一的结构化表示方法至关重要[1]。文档中详细定义了一个包含三大类、七个子类的CRE分类体系,并规定了每个事件的典型结构元素[1]。这种标准化分类是实现规模化、自动化CRE监控、犯罪趋势分析和风险预警等高级应用的前提[1]。
CRE分类体系:
- CRIME 事件 (犯罪类事件): 指直接描述犯罪行为的事件[1]。
- INJURE (人身伤害): 例如谋杀、抢劫中的暴力行为、殴打等[1]。
- OFFENSE (违法行为): 例如盗窃、欺诈、贩毒、走私等违反法律的非暴力或财产性行为[1]。
- TRANSFER 事件 (转移类事件): 指描述与犯罪相关的物品、人员或资金转移的事件[1]。
- MOVEMENT (物品转移): 特指与犯罪相关的物品(如毒品、武器、赃物)的非法转移[1]。
- TRAFFIC ACCIDENT (交通事故): 特指涉及违法或犯罪(如酒驾、逃逸、用于犯罪目的)的交通事故[1]。
- POLICE 事件 (警方行动类事件): 指描述警方针对犯罪或嫌疑人采取的行动[1]。
- ARREST (逮捕): 警方对犯罪嫌疑人的拘捕行动[1]。
- TRIAL (审判): 对犯罪嫌疑人进行的法庭审理过程[1]。
- PD (警方行动): 除逮捕和审判外的其他警方常规行动或调查(如盘查、搜查、布控)[1]。
 图 2.1:主要犯罪相关事件类别及其子类型信息图。该图概括了CRE的三大类和七个子类型,提供了一个清晰的分类框架。
图 2.1:主要犯罪相关事件类别及其子类型信息图。该图概括了CRE的三大类和七个子类型,提供了一个清晰的分类框架。
CRE结构化表示:
每个CRE事件通常都具有一个典型的结构,包含核心的参与者(Participants)和重要的属性(Attributes)。通过前面提到的技术(如LLEs),可以将文本中对应的语言片段抽取出来,并映射到这些结构元素上[1]。
- 参与者 (Participants):
- Agent (发起者/施事者): 事件的执行者或主动方,如罪犯、警察机关[1]。
- Object (受作用对象/客体): 事件影响的目标或承受方,如受害者、被盗物品、嫌疑人[1]。
- 属性 (Attributes):
- TIME-ARG (时间参数): 事件发生的时间信息,如具体日期、时间点、时间段[1]。
- PLACE-ARG (地点参数): 事件发生的地点信息,如具体地址、区域、场所[1]。
- INST-ARG (工具参数): 事件过程中使用的工具或手段,如凶器、作案车辆、网络钓鱼链接[1]。
下表清晰地展示了CRE的类型、子类型及其典型的结构元素:
| 大类(Category) | 子类型 (Sub-type) | 中文释义 (Chinese Meaning) | 典型参与者 (Typical Participants) | 典型属性 (Typical Attributes) |
|---|---|---|---|---|
| CRIME | INJURE | 人身伤害 | Agent, Object | TIME-ARG, PLACE-ARG, INST-ARG |
| CRIME | OFFENSE | 违法行为 | Agent, Object | TIME-ARG, PLACE-ARG, INST-ARG |
| TRANSFER | MOVEMENT | 物品转移 | Agent, Object | TIME-ARG, PLACE-ARG |
| TRANSFER | TRAFFIC ACCIDENT | 交通事故 | Agent, Object | TIME-ARG, PLACE-ARG |
| POLICE | ARREST | 逮捕 | Agent (Police), Object (Suspect) | TIME-ARG, PLACE-ARG |
| POLICE | TRIAL | 审判 | Agent (Court), Object (Defendant) | TIME-ARG, PLACE-ARG |
| POLICE | PD | 警方行动 | Agent (Police) | TIME-ARG, PLACE-ARG |
表 2.1:CRE类型、子类型及其典型结构元素[1]
通过这套分类体系和结构化表示,从文本中提取出的零散信息被组织成标准化的事件记录,极大地提高了信息的可比性、可检索性和可利用性,为后续的自动化分析和情报研判奠定了坚实基础[1]。
2.5 分层语言系统建模与混合方法论
为了有效应对自然语言的复杂性和CRE识别任务的多样性,研究者们在方法论层面也进行了积极探索,其中分层语言系统建模和混合方法是重要的方向。
- 分层语言系统建模: 这种方法论将自然语言视为一个由多个相互关联的层次(如词法层、句法层、语义层、语用层)构成的复杂系统[1]。在进行CRE分析时,它主张综合运用不同层次的语言学知识和分析技术。例如,在词法层面进行准确的分词和词性标注,在句法层面分析句子结构和依存关系,在语义层面理解词义和事件角色,在语用层面考虑上下文和说话人的意图(尽管语用层在自动化处理中极具挑战)。通过这种多层次、全方位的建模分析,期望能够更全面、更深入地捕捉和提取文本中与犯罪相关的各类事实信息,减少单层分析可能带来的偏差或遗漏[1]。
- 混合方法(Hybrid Approach): 鉴于纯粹的规则驱动方法(如基于LLEs)和纯粹的数据驱动方法(如基于机器学习模型)各有优劣,混合方法应运而生[1]。它主张有机地融合这两种技术的优势,以期在模型的准确性、泛化能力和可解释性之间取得更好的平衡[1]。
- 规则驱动技术: 通常具有较高的准确性和较好的可解释性,因为其决策过程基于明确定义的规则。它们在处理特定、已知的语言现象和事件模式时表现优异[1]。
- 数据驱动技术: 通常具有更强的泛化能力,能够从大规模数据中学习到更复杂、更隐蔽的模式,对于处理未曾预料到的新表达方式更为灵活,但有时缺乏可解释性,且依赖大量标注数据[1, 2]。
CRE识别任务本身具有高度的复杂性:它既需要法律语境下的高度精确性,又需要应对网络语言千变万化的表达方式所要求的泛化能力。因此,“混合方法”的采用,通过利用规则的先验知识指导模型的学习方向,同时借助数据驱动方法从大规模语料中学习细致的统计规律,被认为是当前解决此类复杂NLP问题的有效且务实的策略[1]。它能够取长补短,在保证一定准确性的前提下,提升模型对新情况的适应能力和鲁棒性。
第三章:跨语言CRE识别与分析:进展与挑战
随着全球化和网络化的深入发展,犯罪活动日益呈现跨国界、跨语言的特征。这使得对多种语言文本中犯罪相关事件(CRE)的有效识别与分析,对于国际执法合作和全球安全治理具有至关重要的意义[4]。本章将重点探讨跨语言CRE识别,特别是针对低资源语言处理的进展与挑战[1, 2]。
3.1 平行语料库方法的核心思想与构建实践
在跨语言CRE分析中,尤其是当目标语言是NLP资源相对匮乏的“低资源语言”时,平行语料库(Parallel Corpus)扮演着核心的赋能角色[1]。平行语料库是指包含了源语言文本及其对应的目标语言翻译文本的语料集合。例如,原始文档中提及的研究构建了哈萨克-俄语犯罪文本平行语料库,其中俄语作为NLP资源相对丰富的高资源语言(源语言),而哈萨克语作为低资源语言(目标语言)[1]。
平行语料库方法的核心思想在于利用高资源语言上已有的NLP工具、标注数据或训练好的模型,通过语料库中对齐的句子对,将相关的知识(如事件类型、角色标注信息)迁移到低资源语言上[1]。这一过程通常依赖于句子对齐技术(Sentence Alignment),即自动识别平行语料中意义相同或相近的源语言句子和目标语言句子,并将它们配对[1]。一旦句子对齐完成,就可以将在源语言句子中识别出的CRE信息(例如,通过在俄语上训练的CRE提取模型得到的结果)映射或投影到其对应的目标语言句子上,从而为目标语言生成“伪标注”数据或直接进行事件识别。这种方法可以看作是一种有效的知识迁移(Knowledge Transfer)或模型自举(Bootstrapping)策略[1]。
 图 3.1:基于平行语料库的犯罪相关事件跨语言知识迁移过程图。该图描绘了如何利用高资源语言的工具和数据,通过平行语料库将知识迁移到低资源语言进行CRE识别。
图 3.1:基于平行语料库的犯罪相关事件跨语言知识迁移过程图。该图描绘了如何利用高资源语言的工具和数据,通过平行语料库将知识迁移到低资源语言进行CRE识别。
对于低资源语言而言,从零开始构建大规模高质量的标注数据往往成本高昂且周期漫长,这构成了其NLP技术发展的“冷启动”难题[1]。平行语料库方法的运用,通过巧妙地“借用”高资源语言的已有成果,极大地降低了在低资源语言上启动CRE识别任务的技术门槛和资源需求[1]。它是实现“填补低资源语言NLP工具空白”的核心手段之一,为在这些语言上开展CRE分析工作提供了切实可行的路径。
3.2 针对特定语言(如哈萨克语黏着语)的处理技术
在利用平行语料库进行跨语言CRE分析时,对目标语言(尤其是结构特性显著的语言)进行深入的语言学处理是必不可少的环节[1]。文档中特别强调了在处理如哈萨克语这类黏着语(Agglutinative Language)时,对高质量的词性标注(POS tagging)和形态分析(Morphological Analysis)工具的依赖性[1]。
黏着语的特点是词汇通常由一个词根和多个附加的词缀(表示语法功能,如格、数、时态等)构成,词形变化非常丰富[1]。准确的形态分析能够将复杂的词形分解为词根和各个词缀,揭示其内部结构和语法意义[1]。而准确的词性标注则能确定每个词在句子中的词类(如名词、动词、形容词等)[1]。这些基础的NLP分析结果,对于后续的句法分析、语义角色标注乃至准确的CRE元素(如参与者、属性)识别和对齐都是至关重要的。如果不能很好地处理目标语言的这些底层语言特性,那么从源语言迁移过来的知识就可能因为语言结构的差异而无法准确“落地”。因此,为低资源语言(尤其是具有复杂形态变化的语言)开发和优化这类基础NLP工具,本身就是一项充满挑战但又意义重大的工作[1]。这些基础工具的成熟度直接影响着后续跨语言知识迁移的有效性。
3.3 基于平行语料库的跨语言CRE提取实验分析与评估
原始文档中报告了基于平行语料库方法在俄语(源语言)和哈萨克语(目标语言)上进行CRE提取的实验结果,这些结果为我们提供了评估该方法有效性的具体数据[1]:
- 在**俄语(源语言)**上,利用EPB(Event Pattern Based)方法进行完整CRE(包括事件类型和所有核心角色)提取的性能表现良好,精确度(Precision)达到了 73%,召回率(Recall)达到了 94.8%[1]。这表明在资源相对丰富的源语言上,CRE提取技术已经能够达到较高的水平,为知识迁移奠定了基础。
- 在哈萨克语(目标语言)上,通过平行语料库将俄语的事件类型和角色信息迁移过来后,完整CRE提取的精确度为 55.76%,召回率 为 72.4%[1]。
- 为了确保标注数据和模型评估的可靠性,研究者还进行了专家评估标注结果的一致性检验,采用的指标是科恩Kappa系数(Cohen's Kappa)。结果显示,专家之间的一致性达到了 88.2% 至 92.8% 的较高水平[1]。这验证了标注标准的清晰性和数据的可靠性。
对俄语和哈萨克语实验结果的对比分析,清晰地揭示了当前跨语言迁移学习技术在CRE识别领域的潜力及其面临的局限。哈萨克语作为目标语言,其性能相较于源语言俄语有所下降(例如,精确度从73%降至约55.8%)[1]。这种性能上的差距在一定程度上是预料之中的,它可能源于多种因素的叠加影响:首先,跨语言迁移过程中不可避免地会存在信息损失;其次,俄语和哈萨克语在语言结构、表达习惯等方面存在差异,可能导致从源语言学习到的模式不能完全适用于目标语言;再次,目标语言(哈萨克语)的NLP基础工具(如形态分析器、POS标注器)的成熟度和性能可能不如源语言(俄语);最后,平行语料库的质量和对齐的准确性也会直接影响迁移效果[1]。
尽管存在性能差距,但哈萨克语上取得的实验结果(精确度超过55%,召回率超过72%)仍然有力地证明了基于平行语料库的跨语言CRE提取方法的可行性和重要价值[1]。正如文档所强调的,这“首次实现哈萨克语的CRE提取”,本身就是一项重要的技术突破[1]。这些结果同时也为未来的研究指明了方向,即需要通过改进迁移学习算法、增强目标语言的NLP基础工具、提升平行语料质量等多种手段,来进一步缩小源语言与目标语言之间的性能差距。
此外,高达 88.2%-92.8% 的专家评估一致性(Cohen's Kappa 值)是这项研究中一个不容忽视的亮点[1]。在CRE识别这类需要深度语义理解且直接服务于执法等敏感领域的任务中,对标注数据的准确性和一致性有着极高的要求。Cohen's Kappa 系数是衡量不同标注者之间判断一致性程度的常用统计指标。如此高的一致性水平,表明研究中所使用的标注标准清晰明确,标注人员的理解和执行高度统一。这不仅确保了训练数据和测试数据的质量,也使得基于这些数据得出的模型性能评估结果更加可信、更具说服力。这对于任何依赖人工标注的机器学习研究(尤其是在新兴的、定义尚在完善的领域),都是衡量其研究质量和结论可靠性的重要基石[1]。
3.4 当前跨语言处理面临的挑战
尽管基于平行语料库的方法取得了一定的成功,但跨语言CRE识别与分析领域仍面临诸多挑战:
- 数据稀疏性问题: 对于绝大多数低资源语言而言,高质量、大规模的平行语料仍然非常匮乏。即使能够构建一些,其覆盖的领域和主题也可能有限,这直接制约了模型的学习能力和泛化性能[1, 2]。
- 语言结构巨大差异: 不同语系(如印欧语系与阿尔泰语系)的语言之间在词法、句法、语序等方面可能存在巨大差异。这种结构上的鸿沟给基于对齐的知识迁移带来了极大困难,简单的词汇或短语对齐可能不足以捕捉深层的语义等价性[1]。
- 流水线处理中的错误传播与放大效应: 在基于流水线(pipeline)的跨语言处理流程中,源语言端的错误(如错误的事件识别、不准确的角色标注)或平行语料对齐阶段的错误,很容易被传播并放大到目标语言端,导致目标语言模型性能的显著下降[1]。
- 文化背景与表达习惯差异的影响: 犯罪相关的表达方式往往带有浓厚的地域文化色彩和特定的社会语用习惯(如黑话、俚语)。这些隐性的文化因素很难通过简单的文本对齐来捕捉和迁移[1]。
- 评估的复杂性: 在低资源语言上,缺乏可靠的人工标注数据作为黄金标准,使得模型性能的准确评估变得复杂。
3.5 跨语言CRE识别的解决思路与研究方向
针对上述挑战,未来的研究可以从以下几个方面探索解决思路:
- 持续扩充与优化平行/可比语料库: 投入更多资源建设更大规模、更高质量、覆盖更多领域和语种(尤其是极低资源语言)的平行语料库和可比语料库(Comparable Corpora,指主题相似但非直接翻译的文本)。探索更高效的语料库自动构建和对齐技术,如利用无监督或半监督的句子对齐算法,结合众包等方式[1]。
- 研究更鲁棒的跨语言表征学习: 利用深度学习技术(如跨语言词嵌入、多语言预训练模型如mBERT、XLM-R等)学习语言无关或语言相近的共享语义表示空间,使得不同语言的文本能够在同一语义空间中进行比较和对齐,从而提升知识迁移的鲁棒性,减少对显式对齐的依赖[1, 2]。
- 探索无监督与半监督学习方法: 在目标语言标注数据极度稀缺的情况下,积极探索无监督的跨语言迁移方法(如基于无监督机器翻译生成伪平行数据)或仅依赖少量目标语言标注数据的半监督学习方法,以减轻对大规模平行语料的依赖,提高在数据极度稀缺场景下的可用性[1, 2]。
- 结合多模态与多源信息进行跨语言分析: 对于某些特定类型的犯罪事件(如网络诈骗、恐怖宣传),除了文本信息外,还可能伴随图像、视频等多模态信息。研究如何融合这些多模态信息进行跨语言CRE分析,可能会提供新的视角和线索[1, 2]。同时,整合来自不同来源(如新闻报道、社交媒体、暗网论坛)的信息,进行交叉验证和互补,也有助于提升识别的准确性,尤其是在单源或单模态信息不完整时[2]。
- 提升底层NLP工具的质量: 对于形态复杂或句法独特的低资源语言,持续研发和优化其分词、词性标注、形态分析、句法分析等基础NLP工具,这是实现准确跨语言迁移的前提[1]。
第四章:CRE识别与分析的前沿研究方向与技术进展
犯罪相关事件(CRE)的识别与分析作为一个快速发展的领域,正受益于人工智能、大数据和相关计算技术的最新突破[2, 3]。本章将重点探讨CRE识别与分析领域的前沿研究方向和近年来(特别是2022年至今)的技术进展[2, 3, 4, 5]。
4.1 深度学习技术在CRE识别中的深化应用
深度学习技术,特别是近年来基于Transformer架构的模型,极大地推动了NLP领域的进步,也为CRE识别带来了新的机遇[2, 3]。
- Transformer架构及其衍生模型: BERT、GPT系列、RoBERTa、XLM-R等多语言预训练模型通过在海量文本数据上进行无监督预训练,学习到了丰富的语言知识和深层语义表示[2, 3]。这些模型在捕捉长距离依赖、理解复杂句法结构和多义词消歧方面表现出色,能够更有效地提取CRE的触发词、论元和它们之间的关系[2, 3]。将这些预训练模型应用于CRE识别任务,通常只需要在少量标注数据上进行微调(Fine-tuning),即可取得显著优于传统机器学习方法的性能[2, 3]。
- 端到端事件抽取模型: 传统的事件抽取常常采用流水线方法,将任务分解为触发词识别、论元识别和论元角色分类等子任务。这种方法容易导致错误在不同阶段传播[1]。近年来,研究者们探索构建端到端的事件抽取模型,利用联合学习框架同时完成触发词识别、论元识别及角色分类[2]。例如,基于Sequence-to-Sequence、Graph Convolutional Networks (GCN) 或Pointer Network等架构的模型,能够一次性从文本中抽取并结构化完整的事件信息,简化流程,并可能提升整体性能[2, 3]。
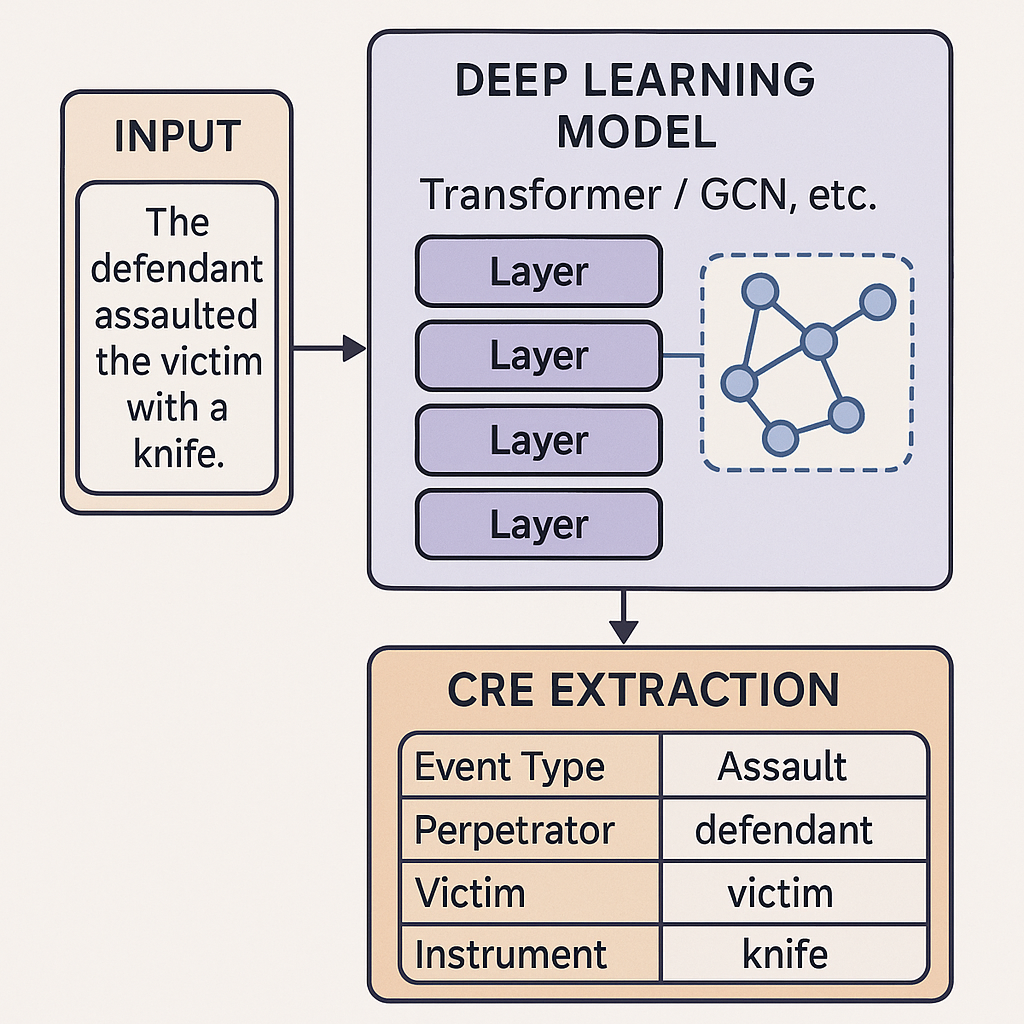 图 4.1:基于深度学习的犯罪相关事件抽取架构图。该图展示了利用深度学习模型从原始文本中直接抽取结构化CRE信息的端到端或联合学习架构示意。
图 4.1:基于深度学习的犯罪相关事件抽取架构图。该图展示了利用深度学习模型从原始文本中直接抽取结构化CRE信息的端到端或联合学习架构示意。
4.2 特定算法模型的研究与实践
除了通用的深度学习架构,一些特定算法模型在处理与CRE相关的复杂场景中也展现出潜力[2, 3]:
- 图神经网络(GNNs): GNNs在处理具有图结构的数据方面具有天然优势。在犯罪分析领域,犯罪网络、社交媒体关系、金融交易网络等都可以表示为图。GNNs可以用于分析这些图结构中的行为异常,识别隐藏的犯罪团伙、资金流动路径或异常传播模式[2, 3]。一些2024年的研究展示了GNNs在社交行为、金融欺诈、交通轨迹预测等“行为异常”检测中的应用,这与发现犯罪线索有相似之处[2, 3]。
- 扩散模型(如MMaDA)等多模态大模型: 犯罪活动日益复杂,常常涉及文本、图像、视频等多种模态信息[2, 3]。例如,网络诈骗可能包含诈骗文本、虚假宣传图片。多模态大模型(如2025年发布的MMaDA)能够同时处理和理解不同类型的数据,实现跨模态的协同分析和联合推理[2, 3]。这种能力对于整合来自不同渠道(如文本聊天记录、监控视频、社交媒体图片)的线索至关重要,有助于构建更全面的事件视图,应对网络犯罪日益复杂的表现形式[2, 3]。
- 因果推断(Causal Inference): 虽然多数AI模型擅长发现关联性,但缺乏对因果关系的理解[2, 3]。在犯罪分析中,理解事件之间的因果链条(如某个事件是否导致了后续事件、某个因素是否导致了犯罪行为)对于预测、归因和制定干预策略至关重要。因果推断方法旨在识别和量化不同事件或因素之间的因果关系,提高模型的可解释性,并为决策提供更坚实的理论依据[2, 3]。一些2024年的探索性研究将因果推断应用于分析事件间的复杂影响,未来有望应用于理解犯罪事件的发生机制和影响路径[2, 3]。
- 资源高效与隐私保护算法: 在处理敏感的犯罪相关数据时,数据隐私和安全性是核心问题[2, 3, 5]。联邦学习(Federated Learning, FL)允许在不共享原始数据的情况下,在多个参与方(如不同执法机构、金融机构)之间协同训练模型,有效保护了数据隐私[2, 3]。一些2024年的研究提出了更高效的联邦学习框架[2, 3]。此外,资源高效的算法(如模型压缩、边缘计算模型)也对于在计算资源受限的环境下进行实时CRE分析具有重要意义[2]。这些技术进步对于在分布式、敏感数据环境下安全、高效地开展CRE分析至关重要。
4.3 犯罪模式的动态识别与实时分析能力构建
犯罪手法并非一成不变,尤其是网络犯罪,其演化速度非常快[7]。同时,随着数据产生速度的加快,对CRE分析的实时性要求也越来越高[2]。
- 应对犯罪手法的快速演化: 系统需要具备动态学习和适应新出现的犯罪模式、黑话或隐晦表达的能力,而非仅仅依赖于预先定义的规则或在旧数据上训练的模型[1, 7]。这需要持续的模型更新、在线学习或迁移学习等技术。
- 实时处理高通量数据流: 犯罪线索可能隐藏在高通量的网络文本流(如社交媒体、论坛)中。构建能够实时处理和分析这些流式数据的系统,及时发现潜在的犯罪信号,是实现早期预警和快速响应的关键[2]。这需要高效的数据处理架构和低延迟的推理模型。
- 结合时序分析、异常检测、趋势预测: 将CRE识别结果与时序分析技术结合,分析犯罪事件发生的时间模式和演变趋势;利用异常检测算法识别与已知模式不符的异常事件或行为;通过趋势预测模型预测未来可能的犯罪高发区域、类型或时间点[2, 7]。这些能力的构建有助于从海量孤立事件中洞察犯罪的整体态势和发展规律[7]。
4.4 多模态信息融合的CRE分析
如前所述,现代犯罪活动往往涉及多种模态的信息[2, 3]。
- 融合文本、图像、视频、音频等多模态信息: 例如,网络诈骗信息可能包括欺诈性文字和虚假广告图片;恐怖主义宣传可能包含煽动性文本和极端主义视频;洗钱活动可能通过文本交流、虚假文件(图像)和异常交易模式(结构化数据)共同体现。对这些多模态信息的综合分析,能够提供比单一模态更全面、更准确的犯罪画像[2, 3]。
- 多模态协同分析和联合推理的技术挑战与研究方向: 如何有效地表示和对齐不同模态的数据?如何进行跨模态的特征学习和信息融合?如何实现基于多模态信息的联合推理?这些是当前多模态CRE分析面临的主要技术挑战[2, 3]。研究方向包括开发多模态深度学习模型(如前述的MMaDA)、跨模态注意力机制、多模态知识图谱等[2, 3]。
- 应对网络犯罪日益复杂的表现形式: 网络犯罪分子善于利用多种媒介和手段[2, 7]。多模态融合分析能力是应对这些复杂表现形式、提升网络犯罪检测和调查效率的必然要求。
第五章:CRE识别与分析的主要应用领域
犯罪相关事件(CRE)识别与分析技术凭借其将海量非结构化文本转化为结构化情报的能力,已经在多个关键领域展现出显著的实际应用价值和广阔的应用前景[1, 2, 4]。这些应用不仅提升了传统工作的效率,也为应对新型挑战提供了有力的技术支撑[2, 4, 6, 7]。
5.1 网络安全与执法领域
网络安全与执法是CRE识别与分析技术应用最为核心和直接的领域,也是其最初发展的驱动力之一[1, 2, 6]。
- 犯罪预防与线索发现: 该技术能够帮助执法机构和安全部门自动化处理和分析来自互联网(如新闻网站、论坛、博客)、社交媒体平台、乃至暗网等渠道的海量文本数据[1, 2, 6]。从中及时发现潜在的犯罪信号、预谋线索(如恐怖袭击预警、群体性事件策划)、非法物品交易信息、招募信息等[1, 6]。例如,通过识别煽动暴力、传播极端思想、组织非法集会、网络钓鱼、勒索软件攻击等内容的文本,可以实现对潜在风险的早期预警,为采取主动预防措施争取宝贵时间[2, 6, 7]。
- 提升调查效率与精度: 传统的案件侦查往往需要投入大量人力进行繁琐的文本信息筛选和阅读[1]。CRE识别技术通过自动化提取结构化的犯罪事件要素(如时间、地点、人物、行为、工具、涉及金额等),能够极大地减轻调查人员的人工负担,使他们能够将精力更聚焦于关键信息的核实、关联分析和决策研判,从而显著提升案件调查的效率和准确度[1, 2, 6]。
- 网络犯罪调查支持: 在针对网络诈骗、黑客攻击、数据泄露等网络犯罪的调查中,CRE识别技术可以作为重要的信息输入源[2, 3, 4]。例如,它可以辅助分析从查获设备中提取的聊天记录、电子邮件、日志文件等数字证据,快速定位与犯罪活动相关的对话、交易记录或操作行为[2, 4]。这与开源情报(OSINT)搜集、记录与邮件分析等调查方法论高度契合,CRE技术为这些方法提供了强大的自动化工具[2, 4]。
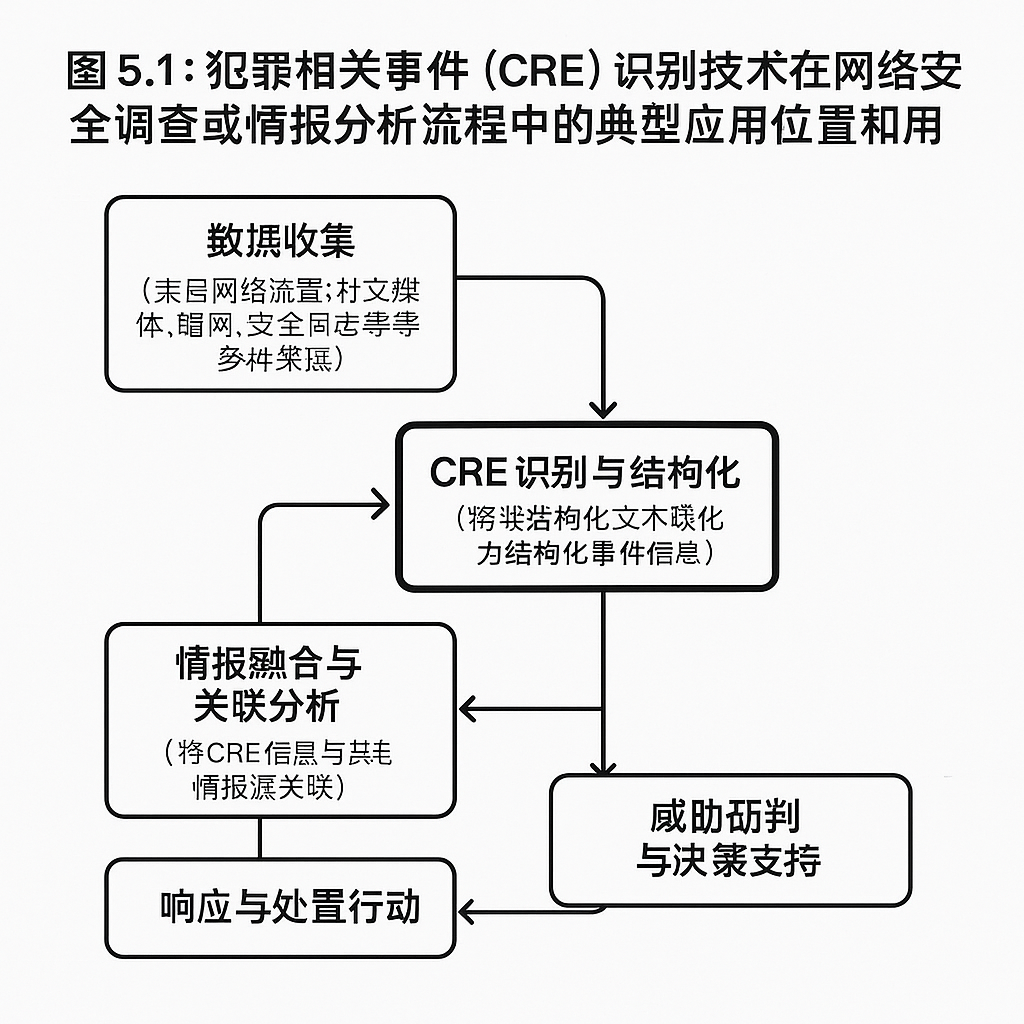 图 5.1:犯罪相关事件识别技术在网络安全调查与情报分析中应用流程图。该图展示了CRE识别如何整合到网络安全调查和情报分析流程中,从信息源到分析结果。 案例分析:通过对特定网络论坛中用户发帖内容的CRE识别,自动化提取涉及“非法药品交易”的事件,包括卖方(Agent)、药品名称(Object)、交易地点(PLACE-ARG)、联系方式等信息,快速生成结构化线索列表,辅助警方进行定向侦查和打击[1, 2, 6]。
图 5.1:犯罪相关事件识别技术在网络安全调查与情报分析中应用流程图。该图展示了CRE识别如何整合到网络安全调查和情报分析流程中,从信息源到分析结果。 案例分析:通过对特定网络论坛中用户发帖内容的CRE识别,自动化提取涉及“非法药品交易”的事件,包括卖方(Agent)、药品名称(Object)、交易地点(PLACE-ARG)、联系方式等信息,快速生成结构化线索列表,辅助警方进行定向侦查和打击[1, 2, 6]。
 图 5.2:犯罪相关事件识别与分析流程示意图。该图以图标形式展示了从犯罪事件到识别、特征提取和分析的周期。
图 5.2:犯罪相关事件识别与分析流程示意图。该图以图标形式展示了从犯罪事件到识别、特征提取和分析的周期。
5.2 金融领域
金融领域是CRE识别与分析技术的另一个重要应用方向,尤其是在反洗钱(AML)、反欺诈(Anti-Fraud)和合规审查方面[2, 3, 4, 5]。
- 资金流动追踪与洗钱调查: 洗钱活动通常涉及复杂的资金流动和隐藏的交易网络[3, 5]。CRE识别技术可以应用于分析各种金融文档(如银行交易记录、汇款单据、公司注册文件)、新闻报道和公开信息,从中提取涉及资金转移(TRANSFER事件)的CRE,如“A向B转账100万元”、“C公司收到来自D的款项”[1, 3, 5]。结合其他分析方法(如链路分析),可以帮助识别异常资金流动路径、发现隐藏的资产链条和可疑实体[1, 3, 5, 6]。Egmont Group等金融情报机构在反洗钱报告中强调了信息收集与关联分析的重要性,CRE识别技术为这一过程提供了自动化支持[3, 5]。Fincen(金融犯罪执法网络)项目也依赖类似的数据分析能力[4, 5]。
- 异常交易模式识别与金融欺诈防范: CRE识别技术可以从交易描述、客户交流记录、内部操作日志等文本数据中提取可能指示欺诈行为的CRE,如“伪造合同”、“虚假陈述”、“未经授权的操作”[1, 2, 3]。这些结构化事件可以与交易数据结合,帮助识别异常交易模式,如涉及特定描述词汇的交易、与已知欺诈CRE关联账户的交易[2, 3]。例如,一些模型(如AlphaEvolve等类似的行为异常检测模型,虽然可能不完全基于文本)通过分析高维行为数据(包括文本描述),辅助识别和归因新型金融诈骗行为[2, 3]。
- RPA在金融/租赁运营中的应用: 虽然RPA(机器人流程自动化)本身不是文本CRE识别技术,但与文本分析(包括CRE识别)结合后,可以在金融和租赁运营中发挥作用[4]。例如,利用CRE识别从合同文本中提取关键条款、风险点(如逾期、违约等CRE),RPA可以自动化执行后续的风险评估、预警通知或将信息录入风险管理系统,提升合同分析、风险评估、反欺诈预警的效率和准确性[4]。 案例分析:利用CRE识别技术从大量银行交易附言、客户邮件和新闻报道中提取涉及“资金转移(MOVEMENT)”和“违法行为(OFFENSE)”(如虚假贸易、地下钱庄)的CRE,构建涉案实体(公司、个人)和资金流的初步关系图谱,辅助侦破大型跨国洗钱网络[3, 5]。
5.3 执法和社会治理
CRE识别技术不仅服务于具体的案件侦办,也在宏观层面的执法策略和社会治理中发挥作用[2, 4, 6, 7]。
- 综合情报应用与打击有组织犯罪: 通过对来自不同来源、不同语言(得益于跨语言CRE识别能力)的文本信息进行CRE识别和整合,可以构建更全面的综合情报视图[1, 2, 6]。例如,识别涉及“人身伤害(INJURE)”、“违法行为(OFFENSE)”和“警方行动(POLICE)”等各类CRE,并关联事件中的人物、地点、工具,可以帮助发现跨境或本地有组织犯罪团伙的活动网络、成员结构、作案手法和地理分布[1, 6]。英国国家情报模型(NIM)强调多层次、多机构的情报整合,CRE识别技术为实现这种整合提供了底层的数据结构化能力[6]。
- 多机构联动与信息共享机制: 标准化的CRE分类和结构化表示(如表2.1所示)有助于促进不同执法机构、情报部门甚至国际组织之间在犯罪信息方面的互操作性和共享[1, 6, 8]。通过共享结构化的CRE数据,可以打破信息孤岛,实现跨区域、跨部门的协同分析和联合行动[6, 8]。
- 社会治理: 基于城域感知系统整合的各类文本数据(如社区论坛、热线投诉记录、网络舆情),利用CRE识别技术可以及时发现潜在的社会不稳定因素、犯罪苗头或风险事件[2, 7]。例如,识别涉及“寻衅滋事”、“非法聚集”等CRE,结合地理位置信息,可以实现事件级风险的提前预警,为社区管理和精准治理提供决策支持[2, 7]。也可用于针对特定犯罪倾向群体(如仇恨犯罪)的定向分析和监管[6, 7]。 案例分析:在一个城市治理平台中,对采集的社交媒体数据进行CRE识别,发现某区域内针对特定群体的“人身伤害(INJURE)”和“违法行为(OFFENSE)”事件的CRE有显著增加趋势,系统自动生成风险预警,并推送给相关社区民警和治理部门,协助采取干预措施[2, 7]。
 图 5.3:犯罪相关事件(CRE)识别与分析核心要素。该图强调了文本信息、CRE识别分析、分析结果以及分析人员之间的相互作用。
图 5.3:犯罪相关事件(CRE)识别与分析核心要素。该图强调了文本信息、CRE识别分析、分析结果以及分析人员之间的相互作用。
 图 5.4:犯罪相关事件识别与分析流程要素。该图以循环流程展示了实体、关系、时间和犯罪等在CRE识别与分析中的关键作用。
图 5.4:犯罪相关事件识别与分析流程要素。该图以循环流程展示了实体、关系、时间和犯罪等在CRE识别与分析中的关键作用。
5.4 企业安全运营与风险管理
企业同样面临内部舞弊、外部网络攻击等多重安全风险。CRE识别技术在企业安全运营和风险管理中也有重要应用[2, 4]。
- 异常业务操作检测与内部威胁识别: 企业内部产生大量的文本数据,如员工邮件、内部通讯记录、业务系统操作日志、代码提交记录等。通过对这些数据进行CRE识别(广义上,识别与企业安全策略相悖或指示潜在风险的行为),可以发现异常业务操作,如敏感数据的非正常访问或传输、员工间的可疑交流(如讨论泄密、舞弊)、未经授权的系统配置更改等。这有助于识别潜在的内部威胁、员工违规或账号盗用行为[2, 4]。
- 增强安全态势感知: 将从内部数据中识别出的CRE(内部异常事件)与外部威胁情报(从公开网络采集、经CRE识别和结构化的外部威胁信息)相结合,可以帮助企业构建更全面的安全态势感知图景。例如,发现外部情报中的“针对某软件漏洞的攻击(OFFENSE)”CRE,同时内部日志出现“针对使用该软件的服务器的异常访问(广义CRE)”,则可以快速判断企业正面临特定威胁,并启动应急响应[2, 4]。
- 网络犯罪风险量化与评估: 将CRE识别结果作为风险量化模型的输入因子[2, 4]。例如,统计特定时期内企业内部或外部环境中与“数据泄露(OFFENSE)”、“勒索软件(OFFENSE)”等CRE相关的事件发生频率、影响范围等信息,结合企业资产价值和业务连续性要求,利用模拟分析(如蒙特卡洛模拟)对特定网络犯罪风险的潜在损失进行量化评估。这为企业制定网络安全投资优先级、购买保险或实施其他风险管理策略提供了数据支持[2, 4]。 案例分析:对企业内部员工通讯记录进行CRE识别,发现涉及“窃取客户数据(OFFENSE)”或“内部系统漏洞利用(OFFENSE)”的讨论CRE,及时定位涉事人员并进行调查,防范内部数据泄露风险[2, 4]。
 图 5.5:CRE识别与分析概念图。该图抽象地展示了犯罪事件、识别过程、提取的特征以及分析结果之间的关系。
图 5.5:CRE识别与分析概念图。该图抽象地展示了犯罪事件、识别过程、提取的特征以及分析结果之间的关系。
 图 5.6:犯罪相关事件检测与分析流程图。该图展示了从识别到分类、分析和关联的完整流程。
图 5.6:犯罪相关事件检测与分析流程图。该图展示了从识别到分类、分析和关联的完整流程。
5.5 其他潜在应用领域(简述)
除了上述主要领域,CRE识别与分析技术在其他领域也具有潜在的应用价值:
- 医疗健康: 识别文本数据(如医疗记录、保险理赔申请、处方信息)中涉及处方欺诈、医疗保险诈骗、非法药物交易等CRE,辅助合规审查和风险控制[2, 3, 5]。
- 交通与城市规划: 从交通报告、社交媒体讨论、新闻报道中识别涉及交通事故、非法载客、交通管制冲突等CRE,结合地理信息,用于分析交通流量模式、预测事件扩散趋势,为城市交通管理和规划提供支持[2, 3]。
- 智慧办公/楼宇安全: 分析智能楼宇系统日志、安保巡逻报告文本(结合视频/图像分析),识别异常行为(如闯入、非法滞留等),虽然部分可能依赖非文本模态,但文本描述和报告的CRE识别可以作为重要辅助信息,提升安保巡逻效率和异常行为识别能力[2, 4]。
综上所述,CRE识别与分析技术以其强大的非结构化文本处理和结构化情报提取能力,正在渗透并赋能各个与犯罪、安全和风险相关的领域,推动跨界智能化、自动化和决策科学化[2, 4]。尤其在犯罪事件识别与分析、运营提升和异常预警等场景有广泛落地[2, 4]。未来发展需关注智能系统集成、人员技能升级与安全合规共进,建议持续跟踪各类权威研究和行业最佳实践[4]。
 表 5.1:现代与传统犯罪事件识别方法对比图。此表格直观对比了现代CRE分析方法在语义理解、事件结构、覆盖范围和多语言支持等方面相对于传统方法的优势。
表 5.1:现代与传统犯罪事件识别方法对比图。此表格直观对比了现代CRE分析方法在语义理解、事件结构、覆盖范围和多语言支持等方面相对于传统方法的优势。
此表格直观地展示了现代CRE分析方法相对于传统方法在多个核心能力上的革新与进步,突出了其在语义理解深度、事件结构完整性、事件类型覆盖广度以及特别是多语言支持方面的显著优势[1]。这为理解现代CRE技术的核心价值及其在克服传统方法局限性方面所取得的成就提供了集中的论证支持。
第六章:CRE识别与分析的挑战与机遇
犯罪相关事件(CRE)的识别与分析,虽然在理论研究和技术实践中取得了显著进展,但在实际应用中仍然面临多方面的挑战。与此同时,技术和市场的发展也带来了前所未有的机遇[2, 4, 6]。
6.1 当前面临的技术挑战
尽管自然语言处理和相关技术快速发展,CRE识别任务的固有复杂性及其应用环境的特殊性带来了诸多技术难题:
- 对深层语义、隐晦表达的理解难度: 犯罪分子出于隐蔽目的,常常使用俚语、黑话、暗语、隐喻或间接委婉的表达方式进行交流[1]。这使得系统难以捕捉其真实意图和潜在犯罪事实,仅依赖表层词汇匹配的方法效率低下[1]。准确理解上下文、推理隐含语义是巨大的挑战。
- 低资源语言处理的持续难题: 全球范围内犯罪活动涉及多种语言,但大量语言属于“低资源语言”,缺乏充足的标注数据、成熟的NLP工具和大规模语料库[1, 2]。尽管平行语料库和迁移学习提供了可行路径,但数据稀疏性、语言结构巨大差异、错误传播等问题仍需持续攻关[1]。
- 处理文本噪声和对抗性语言: 互联网文本数据通常包含大量噪声(错别字、语法错误、非标准表达)。此外,犯罪分子可能故意采用混淆性语言或技术手段来规避自动化监测,这对模型的鲁棒性和抗干扰能力提出了高要求[1]。
- 多模态信息融合的复杂性: 现代犯罪活动日益多模态化,需要融合文本、图像、视频、音频等多种信息源[2, 3]。如何有效对齐、表示和协同分析来自不同模态的数据,实现跨模态的联合推理,技术上仍需突破[2, 3]。
- 模型的鲁棒性与泛化能力: 真实世界的犯罪数据分布复杂多样,且不断变化[1, 2, 7]。如何构建在不同领域、不同语言、面对不同犯罪手法时都能保持稳定高性能的模型,即提升模型的泛化能力和鲁棒性,是一项持续的挑战[2]。
- 系统集成与实时处理的高要求: 在实际执法或安全运营环境中,需要处理海量实时或近实时数据流[2]。将复杂的NLP和机器学习模型高效集成到现有系统中,并保证处理速度和响应延迟满足实时性要求,对系统架构和计算资源是巨大挑战[2, 4]。
- 数据就绪度与算法落地之间的鸿沟: 前沿算法模型往往需要大量高质量的标注数据进行训练,但现实中获取、标注、维护这些数据成本高昂[2]。同时,实验室环境下表现优秀的模型在实际复杂、噪声多的真实数据上可能性能下降[2]。如何弥合“数据就绪度”不足与“算法落地”之间的鸿沟,是技术转化为实际效能的关键[2]。
6.2 伦理、法律与社会挑战
CRE识别与分析涉及敏感的个人信息和潜在的法律程序,必须审慎处理伦理、法律和社会层面的挑战:
- 数据安全与隐私保护: 收集、存储和分析大量涉及个人通信、行为模式的数据,带来了严重的数据库泄露和滥用风险[1, 2, 5, 6]。必须严格遵守相关的法律法规(如数据保护法、网络安全法、FOIA、隐私法、GDPR等),确保数据采集、处理和存储的合法性、安全性和透明度[1, 2, 5, 6]。
- 法律和伦理考量: 如何界定合法的数据采集范围?何时需要用户同意?AI模型基于数据预测的“高风险人员/区域”是否会产生歧视?CRE识别结果作为潜在证据在法庭上的可采性、如何保证证据链的完整性和模型的决策过程可追溯?这些都需要明确的法律框架和伦理指导[1, 2, 5, 6]。例如,从法医DNA分析中借鉴的样本收集、同意等原则,需要泛化到文本和数字证据的收集场景[5]。
- 算法公平性与避免歧视性判断: 训练数据中可能存在的偏见可能导致模型对特定人群、地域或表达方式产生歧视性判断,影响执法的公正性[2]。必须研究和应用技术手段(如偏见检测与缓解技术)来确保算法的公平性[2]。
- 跨国界数据共享的法律障碍: 犯罪活动的跨国界性要求国际执法机构之间进行信息共享,但不同国家和地区在数据主权、隐私保护和信息披露方面的法律差异,构成了跨境CRE信息共享的法律障碍[4, 6, 8]。
- 平衡公共安全需求与个人权利保护: 这是CRE识别技术应用中永恒的平衡难题[1, 2, 5, 6]。如何在最大限度利用信息技术打击犯罪、维护公共安全的同时,充分保障公民的合法权益、避免权力滥用,是技术发展和政策制定必须共同面对的问题[1, 2, 5, 6]。
6.3 市场与实践层面的挑战
将CRE识别与分析技术从研究推向大规模实际应用,还需要克服市场和实践层面的障碍:
- 初期投资成本较高: 构建高质量的多语言语料库、开发和部署复杂的AI模型、建立支持实时分析的基础设施,都需要大量的资金投入[1, 2, 4]。
- 系统集成与部署难度: 将新的AI系统无缝集成到现有陈旧或分散的执法、安全或金融系统中,通常面临技术兼容性、数据格式不一致、流程再造等复杂问题[2, 4]。
- 跨专业人才的短缺与协同: CRE识别与分析是一个典型的跨学科领域,需要懂NLP和机器学习的AI专家、熟悉犯罪学和情报分析的领域专家、以及了解法律和伦理规范的法务专家紧密协作[1, 2]。这类综合性人才的短缺和不同背景专家之间的有效沟通与协同是实践中的挑战[2]。
- 市场周期波动对技术采纳的影响: 尽管专家预测AI和技术将助力相关行业回暖,但宏观经济环境、政策资金投入等因素的市场周期波动,可能会影响机构对新技术(包括CRE识别)的投资意愿和采纳速度[1, 2]。
6.4 发展机遇
挑战伴随机遇,技术、数据和应用需求的协同发展为CRE识别与分析领域带来了巨大的发展潜力[2, 6, 7]:
- AI与大数据技术带来的革新动力: 深度学习、图神经网络、多模态大模型等前沿AI技术的快速发展,为突破传统NLP方法的局限、提升CRE识别的精度和智能化水平提供了强大动力[2, 3, 4]。海量多源数据的可用性也为数据驱动的模型训练提供了基础[2]。
- 感知-识别-处置一体化流程的自动化潜力: CRE识别是实现从数据感知、事件识别、情报研判到处置行动的完整智能流程中的关键一环[2, 7]。技术的进步使得构建高度自动化的智能分析和决策支持系统成为可能,显著提升效率[2, 7]。
- 跨系统、跨部门数据协同的业务突破口: 标准化的CRE分类和结构化表示为打破信息孤岛、实现不同机构间的数据互联互通提供了基础[1, 6, 8]。通过技术手段促进数据协同和信息共享,能够形成更强大的情报网络,应对复杂犯罪[6, 8]。
- 技术平台化带来的智能风险管控: 将CRE识别等核心能力封装为模块化、灵活可配置的平台服务,可以降低技术门槛,使得更多机构能够快速应用智能技术进行风险管控和安全运营[4]。
- 助力社会治理、“一体化安全管理”等高价值场景落地: 国家对社会治理现代化、“平安城市”、“一体化安全”的投入,为CRE分析技术提供了广阔的应用场景和政策支持[2, 7]。
- 新兴犯罪形态对CRE分析技术的巨大需求: 网络犯罪、金融犯罪、恐怖主义等新型犯罪形态日益复杂,传统手段难以应对[2, 4, 7]。这催生了对更智能、更高效的CRE分析技术的迫切需求[2, 4, 7]。
- 低资源语言支持带来的全球市场潜力: 弥合语言障碍、将CRE分析能力推广到低资源语言国家和地区,不仅具有重要的社会意义,也蕴藏着巨大的全球市场潜力[1, 2]。
第七章:CRE识别与分析的未来发展趋势
展望未来,犯罪相关事件(CRE)识别与分析领域将朝着更智能化、更全面、更高效、更负责任的方向演进[2, 6, 7]。以下是几个关键的发展趋势:
7.1 AI与大数据技术的融合深化
AI和大数据将更紧密地融合,驱动CRE分析向更高级阶段迈进[2, 7]:
- 实现感知-识别-处置一体化: 未来系统将能够从海量多源数据中自动感知异常信号,通过CRE识别技术提取结构化事件,并结合智能分析和决策模型,辅助甚至自动化部分处置流程[2, 7]。这需要构建端到端、高集成度的智能平台[2]。
- 自动化分析平台与工具: 基于云原生、微服务架构的自动化CRE分析平台将成为主流,提供数据接入、预处理、CRE识别、结构化、存储、可视化、分析、预警等全流程服务,降低用户使用门槛[2, 4]。
- 智能化算法预测案件趋势: 利用大数据分析和机器学习模型,从历史和实时CRE数据中学习模式,预测未来可能的犯罪类型、高发区域和时间点,为警力部署和资源分配提供更科学的依据[2, 7]。
7.2 犯罪知识图谱(Crime Knowledge Graph)的构建与智能化应用
将识别出的结构化CRE信息与其他犯罪相关实体(如人物、组织、地点、工具、资金账户)及其关系连接起来,构建大规模、动态更新的犯罪知识图谱[1, 2]:
- 将结构化CRE信息作为构建KG的基础: CRE识别提供了“谁在何时何地做了什么”的基础事实,这些事实可以作为知识图谱中的事件节点或连接实体节点的边[1]。
- 发现隐藏犯罪团伙、预测高危个体/区域、辅助案件串并: 通过对知识图谱进行图分析、社区发现、路径推理等,可以发现传统方法难以揭示的隐藏犯罪网络、识别具有潜在风险的个体或区域、自动关联看似孤立的案件[1, 2]。
- 实现从“事件感知”到“网络洞察”: 知识图谱提供了对犯罪生态系统更高维度的理解,使分析从对单一事件的关注,转向对整个犯罪网络结构、运作模式和相互影响的洞察[1, 2]。
7.3 多模态与跨源信息融合分析
打破文本信息孤岛,整合更丰富的信息维度[2, 3]:
- 突破单一文本模态限制,融合图像、视频、音频等: 开发能够联合处理和理解文本、图像(如聊天截图中的图片、伪造证件扫描件)、视频(如监控录像、犯罪教学视频)、音频(如录音证据)等多种模态信息的多模态模型(如利用多模态大模型),以应对日益复杂的网络犯罪和现实犯罪形式[2, 3]。
- 整合新闻、社交媒体、暗网等不同来源信息进行交叉验证: 结合来自公开网络(新闻、论坛)、社交媒体、即时通讯工具、暗网论坛、甚至内部系统日志等不同来源的信息。通过交叉验证和互补,提高CRE识别的准确性和置信度,获取更全面的情报视图[2, 4]。
7.4 模型可解释性(XAI)与鲁棒性的持续增强
提升AI模型在关键应用领域的信任度和可靠性[2, 3]:
- 提高模型决策过程的透明度: 特别是在执法和司法领域,需要理解模型为何做出某个判断(例如,为何将一段文本识别为犯罪预谋)。未来的研究将更加关注模型的可解释性,开发能够揭示模型判断依据的技术(如注意力机制可视化、特征重要性分析),使其结果更易于人类分析师理解、验证和接受,符合法证要求[2, 3]。
- 增强模型对抗噪声和对抗性攻击的能力: 未来模型需要更强的鲁棒性,能够有效处理非标准语言、排版错误以及犯罪分子为逃避检测而使用的对抗性技术(如故意插入无关词汇、改变表达方式),确保在真实复杂环境下的稳定可靠运行[1]。
7.5 技术与法律、伦理、政策的深度整合
确保技术健康、负责任地发展和应用[1, 2, 5, 6]:
- 确保技术产出符合法庭证据要求: 研究如何使自动化CRE识别系统提取的信息能够无缝接入数字取证流程,满足法律程序对证据的固定、保存和采信要求[1, 2, 5]。
- 在技术应用中充分保护个人隐私和公民权利: 严格遵守隐私保护法律法规,设计和实施差分隐私、联邦学习等技术,最大限度降低个人信息暴露风险[1, 2, 5, 6]。建立健全的监管机制,防止技术被滥用[1, 2, 5, 6]。
- 构建跨学科合作机制: 加强计算机科学家、语言学家、犯罪学家、法学专家、伦理学家、社会学家和政策制定者之间的对话与合作,共同制定技术标准、应用规范和伦理准则[1, 2]。
7.6 泛在智能化与“人机协同”模式
未来的CRE分析系统将更倾向于辅助和增强人类分析师的能力,而非完全取代[2, 7]:
- 智能系统辅助人类分析师: AI系统负责处理海量重复性任务、快速筛选潜在线索、提供初步结构化信息和分析建议[2, 7]。人类分析师则专注于复杂的研判、背景知识整合、策略制定和最终决策,实现优势互补的“人机协同”[2, 7]。
- 灵活、模块化、“即服务”型CRE分析平台: 技术组件将更加模块化,可按需组合和部署,适应不同机构和场景的特定需求[4]。通过云服务等形式提供“即服务”的能力,提高技术可及性[4]。
- 应对跨国犯罪和网络化犯罪,加强情报共享机制与多领域协同: 技术发展将促进标准化CRE信息的快速、安全共享[6, 8]。未来趋势是构建更广泛的跨部门、跨区域甚至跨国界的情报共享平台和协同分析机制,共同应对日益复杂的全球性犯罪挑战[4, 6, 8]。
这些趋势共同指向一个更智能、更高效、更安全、更负责任的未来,CRE识别与分析技术将成为维护社会公正与安全不可或缺的关键力量[2, 6, 7]。
结论
犯罪相关事件(CRE)的识别与分析,作为一项融合了自然语言处理、机器学习、犯罪学和信息科学等多学科知识的前沿技术领域,其核心价值在于能够从海量、异构的文本数据中高效、准确地提取与犯罪活动相关的结构化情报,为执法部门、安全机构以及相关研究领域提供了前所未有的洞察力和行动力[1, 2, 6]。通过对逻辑-语言模型、语义基准识别、触发词检测、逻辑语言方程等关键技术的运用,以及在多语言处理(特别是针对哈萨克语等低资源语言的突破性进展)和完整事件结构提取方面的持续努力,当前CRE分析技术已经取得了显著的成就,并在犯罪预防、案件调查、社会研究、企业安全和风险管理等多个方面展现出巨大的应用潜力[1, 2, 4, 6, 7]。
面对日益复杂化、网络化、智能化和跨国化的新型犯罪形态,以及信息爆炸时代多语言环境下情报获取的严峻挑战,CRE识别与分析技术的重要性愈发凸显[2, 4, 6, 7]。它不仅能够帮助我们更有效地应对传统犯罪问题,更有潜力成为打击网络犯罪、防范恐怖主义、维护国家安全的关键技术支撑[2, 4, 7]。特别是在弥合语言障碍、促进跨国界信息共享和国际执法合作方面,其独特的优势正在逐步显现[4, 6, 8]。
然而,CRE识别与分析领域的发展仍面临诸多挑战,例如对深层语义和隐晦表达的理解能力有待进一步提升,低资源语言的处理技术仍需持续攻关,模型的鲁棒性和可解释性也需要不断加强[1, 2, 3]。展望未来,持续投入基础理论研究,积极推动技术创新(如深度学习的深度融合、动态犯罪模式识别系统的构建、犯罪知识图谱的智能化应用、多模态信息的协同分析等),以及将技术发展与法律框架、伦理规范深度整合,是保持该领域领先地位并有效应对未来新型安全威胁的必要条件[2, 3, 6, 7]。
更进一步,CRE识别与分析技术的发展和应用,不能仅仅局限于技术层面。它必须与法律框架、伦理规范和社会价值紧密结合[1, 2, 5, 6]。如何在利用技术赋能的同时,充分保障公民的合法权益、维护数据的安全与隐私、确保算法的公平与透明,是所有从业者和研究者必须深思和审慎对待的问题[1, 2, 5, 6]。这需要计算机科学家、语言学家、犯罪学家、法学专家、社会学家以及政策制定者之间的跨学科紧密合作与对话,共同致力于推动该领域的健康、可持续和负责任的发展,使其真正成为维护社会公正与安全的有益工具[1, 2]。
参考文献
[1] Criminal Intelligence: Manual for Analysts. United Nations Office on Drugs and Crime, 2011. [2] Carter, David L. Law Enforcement Intelligence Operations. 1990s. (Referenced in OJP report, NCJRS 134434) [3] Financial Analysis Cases 2014–2020. Egmont Group. (Money laundering typologies evolution) [4] Essensys. Flexible CRE Technology. 2022. https://essensys.tech/wp-content/uploads/2022/11/Flexible-CRE-Technology-eBook.pdf [5] BOMA. Leveraging Robotics in CRE: Insights From Four Industry Experts. 2025. https://boma.org/wp-content/uploads/2025/03/Leveraging-Robotics-in-CRE-Insights-From-Four-Industry-Experts-2.pdf [6] UK National Intelligence Model. (Referenced in UNODC Manual, Chapter 3) [7] Carter, David L. Future Trends in Law Enforcement Intelligence. 1991. [8] EPIC & INTERPOL intelligence sharing frameworks.
贡献者
 pansin
pansin