大数据与商业智能时代的安全盾牌:构建可信赖的机器学习系统
摘要
随着大数据、商业智能(BI)和商业分析(BA)成为企业核心竞争力,其底层依赖的机器学习(ML)系统也日益成为网络攻击的新焦点。本文旨在系统性地剖析机器学习在数据、模型和应用全生命周期中面临的网络安全、信息安全与数据安全风险,重点分析数据投毒、对抗性攻击等新型威胁。同时,文章将深入探讨差分隐私、联邦学习和同态加密等前沿隐私保护技术,并最终提出一个集技术、流程与治理于一体的综合安全框架,为企业构建安全、可靠、可信赖的智能分析系统提供战略指引。
1. 引言:智能时代的“双刃剑”
1.1. 大数据与商业分析的价值重塑
在数字化转型的浪潮中,企业决策正经历一场深刻的变革,从传统的“经验驱动”迅速转向“数据驱动”。商业智能(BI)和商业分析(BA)不再是简单的报表工具,而是企业发掘洞见、优化运营、预测未来的核心引擎。在这场变革的核心,机器学习(ML)扮演着无可替代的角色,它能从海量数据中自动学习模式,为预测分析、客户分群、风险评估等关键业务提供强大的技术支撑。
1.2. 新的攻击面:当智能系统遭遇安全威胁
然而,这种深度融合也带来了一柄“双刃剑”。随着机器学习系统渗透到业务的方方面面,它也开辟了新的攻击面。传统的网络安全防御体系专注于保护网络边界和端点,但对潜藏在数据和算法内部的威胁却显得力不从心。数据(智能系统的“血液”)和模型(智能系统的“大脑”)本身已成为高价值的攻击目标。本文旨在深入探讨并回答以下核心问题:我们应如何保护智能系统的核心资产,确保其在复杂多变的网络环境中稳健、可靠地运行?
2. 核心威胁:机器学习系统的主要安全风险与攻击向量
机器学习系统的安全威胁贯穿其整个生命周期,从数据收集到模型推理,每个环节都可能成为攻击者的突破口。
2.1. 训练阶段的威胁:污染数据源(数据完整性攻击)
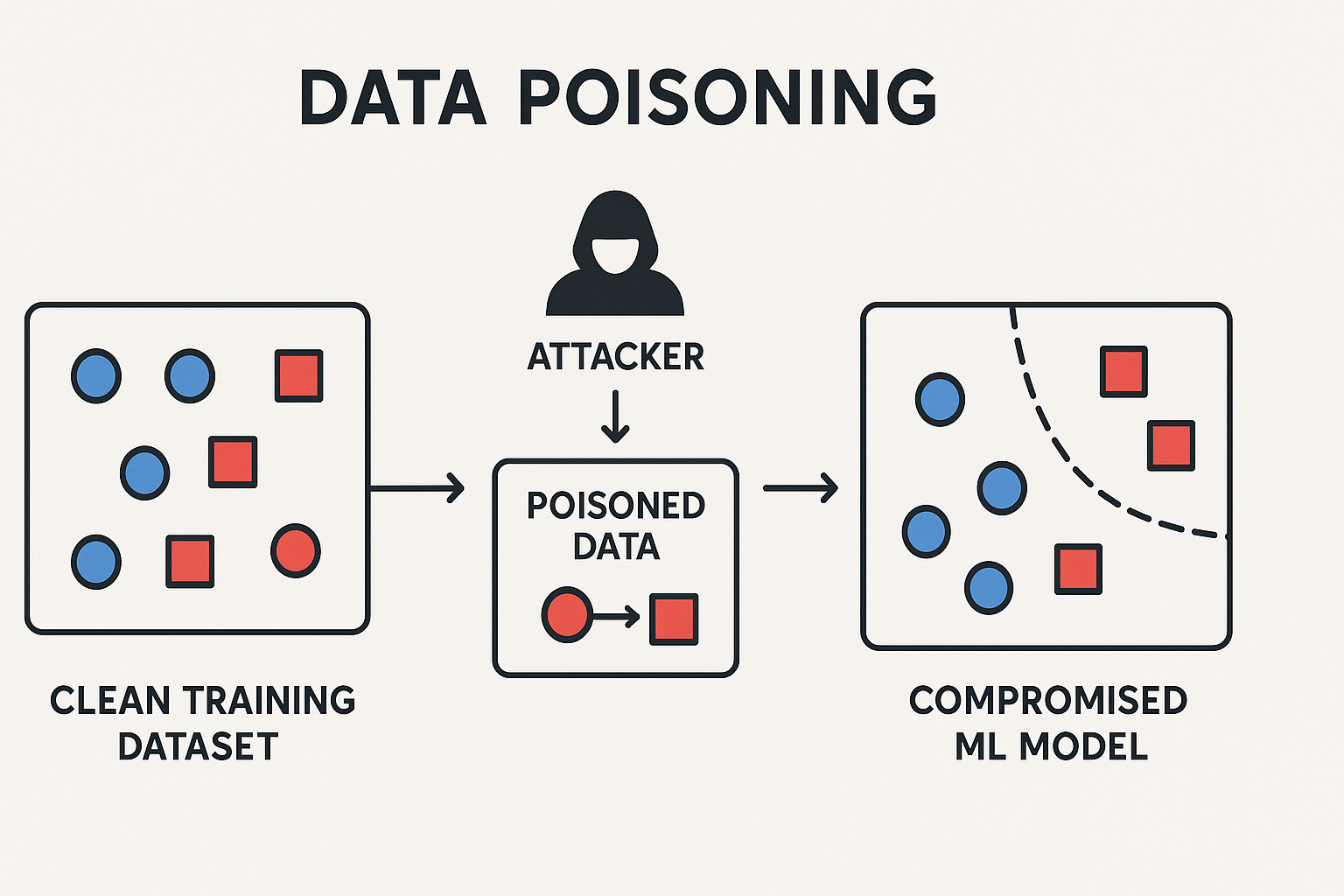
2.1.1. 数据投毒攻击 (Data Poisoning Attacks)
- 定义: 数据投毒是一种在模型训练阶段发起的攻击。攻击者通过向原始训练数据集中注入少量精心构造的恶意样本来污染数据源,从而操纵或破坏模型的学习过程。
- 目标:
- 可用性攻击: 降低模型的整体性能和准确率,使其在所有任务上都表现不佳。
- 完整性攻击(后门攻击): 在模型中植入隐蔽的“后门”。这种模型在处理正常数据时表现完全正常,但一旦遇到包含特定“触发器”(trigger)的输入,就会产生攻击者预设的恶意输出。这种攻击隐蔽性极强,危害巨大。
- 影响: 导致错误的商业预测、有偏见的信贷审批、失效的欺诈检测系统,甚至在安全攸关领域造成灾难性后果。
2.1.2. 防御策略
- 数据验证与清洗: 在数据进入训练流程前,通过异常值检测、数据分布分析等方法识别并剔除可疑的恶意样本。
- 数据溯源与完整性验证: 建立数据来源追踪机制,确保训练数据的可信度。利用哈希或数字签名验证数据在存储和传输过程中的完整性。
- 鲁棒训练: 采用对异常数据不敏感的训练算法,或对影响较大的训练样本进行权重衰减。
2.2. 推理阶段的威胁:欺骗已训练模型(模型规避攻击)
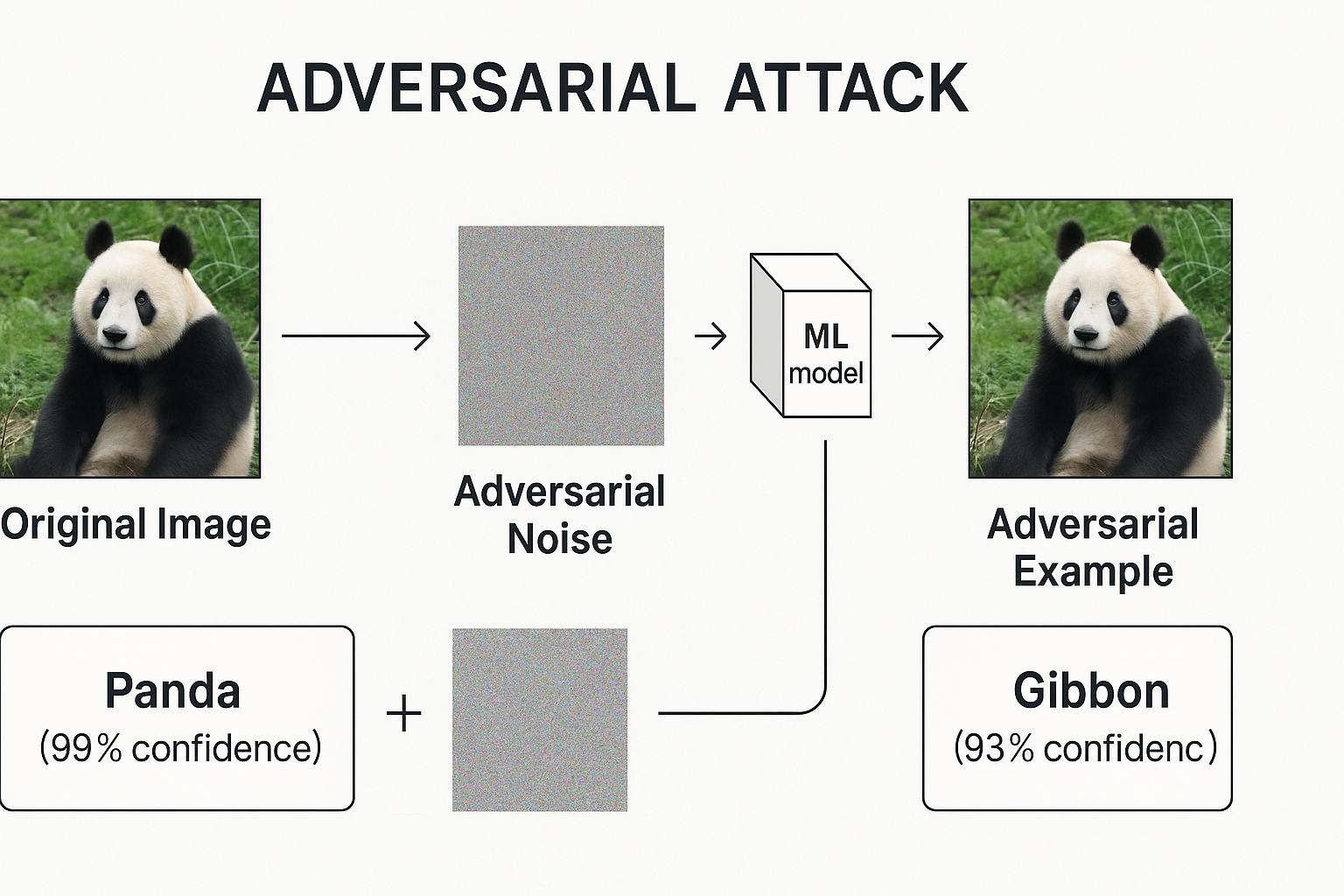
2.2.1. 对抗性攻击 (Adversarial Attacks)
- 定义: 对抗性攻击发生在模型部署后的推理阶段。攻击者通过对正常的输入样本添加人眼难以察觉的微小扰动(即“对抗性噪声”),生成“对抗性样本”,从而诱导训练有素的模型做出错误的预测。
- 示例:
- 图像识别: 对一张熊猫的图片添加微弱的噪声,人类视觉几乎无法分辨差异,但领先的图像识别模型却可能以高置信度将其错误分类为长臂猿。
- 恶意软件检测: 在恶意代码中插入无害指令,从而绕过基于机器学习的病毒检测引擎。
- 影响: 这种攻击能轻易绕过安全检测系统,对自动驾驶、医疗诊断、人脸识别认证等高风险应用构成致命威胁。
2.2.2. 防御策略
- 对抗性训练 (Adversarial Training): 这是目前最有效的防御方法之一。通过在训练数据中持续加入对抗性样本及其正确标签,让模型在训练阶段就“学会”如何抵御此类攻击,从而提升其鲁棒性。
- 防御性蒸馏 (Defensive Distillation): 训练一个更“平滑”的模型,使其对输入的微小变化不那么敏感,增加生成有效对抗样本的难度。
- 输入预处理: 在数据输入模型前,通过去噪、压缩或特征变换等方法,破坏对抗性扰动的结构。
2.3. 模型资产的威胁:窃取与滥用
2.3.1. 模型窃取攻击 (Model Stealing/Extraction)
- 方式: 在模型即服务(MaaS)的商业模式下,模型通常通过API提供预测。攻击者可以像普通用户一样,通过大量查询API并观察输入输出对,逆向工程出一个功能相似的“替代模型”。
- 影响: 这不仅是知识产权的泄露,更危险的是,攻击者可以在本地离线分析窃取到的模型,寻找其漏洞并发起更复杂的攻击。
2.3.2. 成员推断攻击 (Membership Inference)
- 方式: 攻击者试图判断某个特定的数据记录(例如,某位病人的病历)是否曾被用于训练目标模型。
- 影响: 这是严重的数据隐私泄露。如果攻击成功,意味着即使原始数据没有泄露,攻击者也能通过模型反推出敏感信息,这在医疗、金融等领域是绝对无法接受的。
3. 核心对策:隐私保护深度学习技术
为了在充分挖掘数据价值的同时保护商业机密和个人隐私,学术界和工业界发展了一系列前沿的隐私计算技术。
3.1. 差分隐私 (Differential Privacy): 实现“统计上的匿名”
- 核心思想
在数据集的查询结果中引入经过精确校准的“数学噪声”,使得任何单个数据记录的加入或移除,对最终统计输出结果的影响都微乎其微(在统计上无法区分)。这为个体数据提供了强大的、可量化的隐私保障。
- 应用模式
- 中心化差分隐私 (CDP): 由可信的数据聚合方在发布统计数据或训练模型前统一添加噪声。
- 本地化差分隐私 (LDP): 在用户数据离开本地设备(如手机)前就进行加噪处理,从而使中心服务器无法获取任何用户的原始信息。苹果、谷歌等公司已广泛采用此技术收集用户行为数据。
- 商业价值: 在满足《通用数据保护条例》(GDPR)等严苛法规的前提下,安全地进行用户行为分析和市场趋势研究。
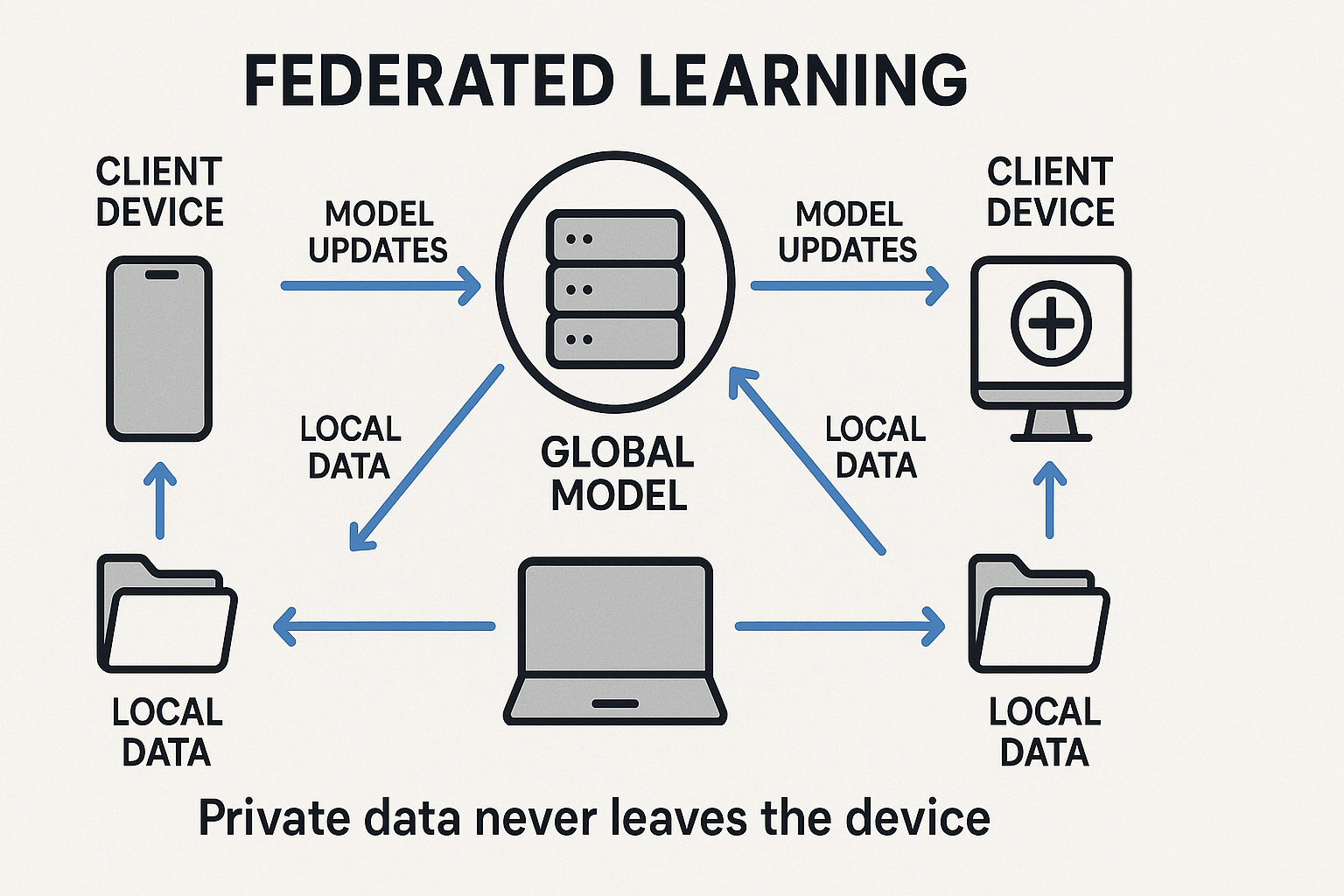
3.2. 联邦学习 (Federated Learning): “数据不动,模型动”
- 核心思想 联邦学习是一种分布式、协同式的机器学习框架。它允许多个参与方(如不同的医院、银行或用户的移动设备)在不交换各自原始数据的情况下,共同训练一个全局模型。各参与方仅在本地用自己的私有数据训练模型,然后将加密或匿名的模型更新(如梯度)上传至中央服务器进行安全聚合,从而迭代出一个性能优于任何单一参与方的全局模型。
- 技术优势
- 数据主权: 敏感数据不出本地,从根本上解决了数据共享中的隐私、安全和合规难题。
- 打破数据孤岛: 能够安全地联合来自不同机构的数据,训练出更强大、泛化能力更强的模型。
- 商业价值: 跨机构医疗影像诊断、金融风控联盟、智能手机输入法预测优化等。
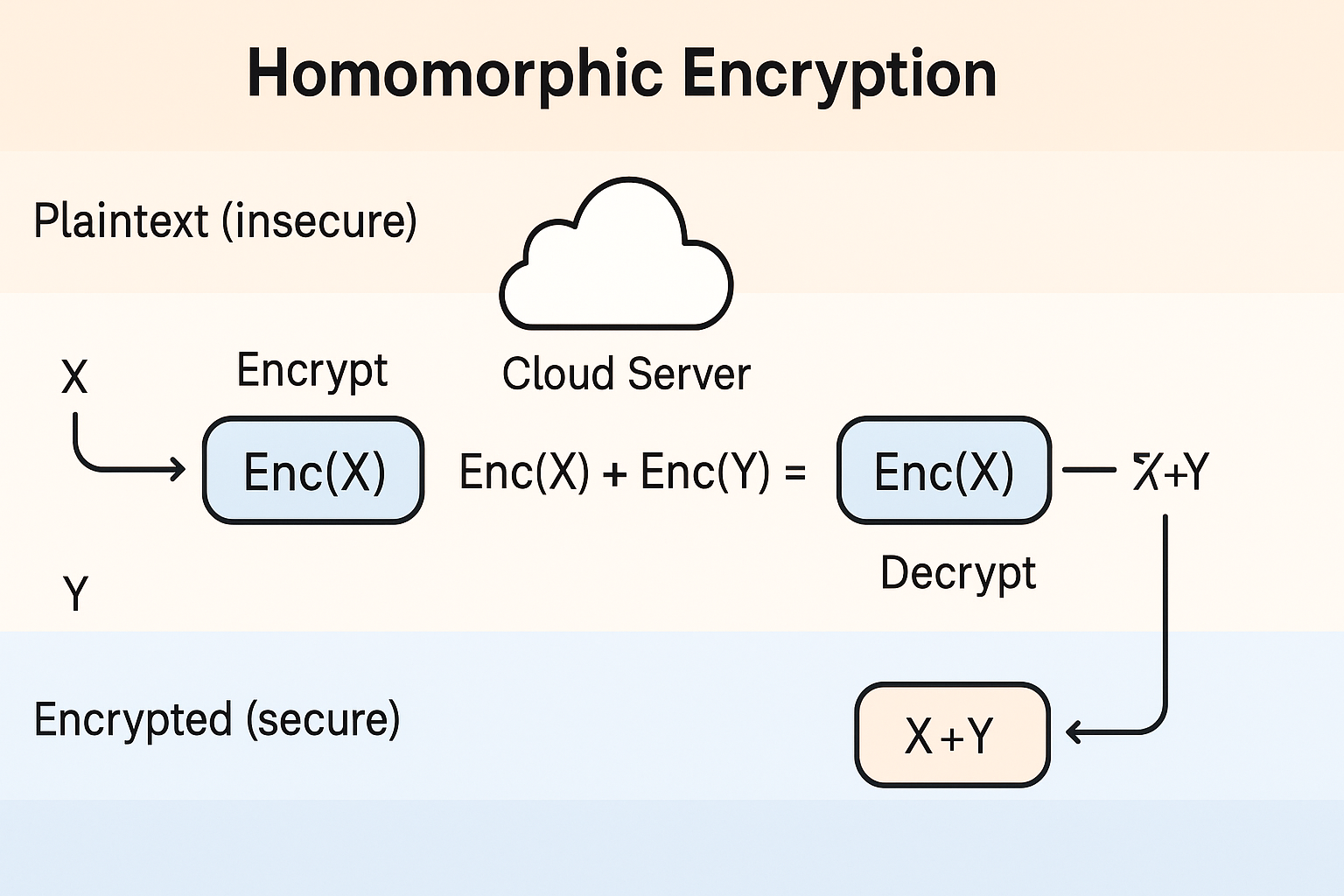
3.3. 同态加密 (Homomorphic Encryption): “密文计算”的终极方案
- 核心思想 同态加密是一种革命性的加密技术。它允许在加密数据(密文)上直接进行计算(如加法和乘法),其计算结果在解密后与在原始数据(明文)上进行相同计算的结果完全一致。其核心原理可表示为:
Decrypt(Compute(Encrypt(Data))) == Compute(Data) - 应用场景与挑战
- 场景: 实现真正安全的云计算外包。用户可以将加密的财务数据上传至云服务商进行分析,而云服务商自始至终无法窥探任何数据内容。
- 当前挑战: 尽管前景广阔,但全同态加密(FHE)的计算开销仍然巨大,性能瓶颈限制了其在复杂机器学习模型中的大规模应用。但随着算法和硬件的进步,其实用性正在快速提升。
| 技术 | 核心原则 | 主要应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 差分隐私 (DP) | 在数据或结果中添加可控噪声 | 聚合数据发布、隐私保护模型训练 | 提供可数学证明的隐私保证,计算开销较低 | 可能降低数据效用和模型精度,存在隐私与精度的权衡 |
| 联邦学习 (FL) | 数据本地化,模型参数共享聚合 | 跨机构协作、边缘计算 | 保护数据主权、打破数据孤岛 | 通信开销大、系统复杂,仍需防范投毒等攻击 |
| 同态加密 (HE) | 对加密数据直接进行计算 | 安全外包计算、隐私查询 | 提供最高级别的计算过程保密性 | 性能开销极大,目前实用性受限 |
| 安全多方计算 (MPC) | 多方协同计算函数,不泄露各自输入 | 隐私求交、联合风控、密钥管理 | 安全性基于密码学假设,无需可信第三方 | 通信和计算复杂度高,适用于特定场景 |
4. 战略落地:构建企业级大数据分析安全框架
仅有先进的技术是不够的,企业需要一个全面、系统的战略框架来落地安全实践。
4.1. 将安全融入机器学习生命周期 (MLSecOps)
“安全左移”(Shift Left)的理念必须贯穿于整个MLOps流程中,将安全考量从被动的“事后补救”转变为主动的“内建设计”。
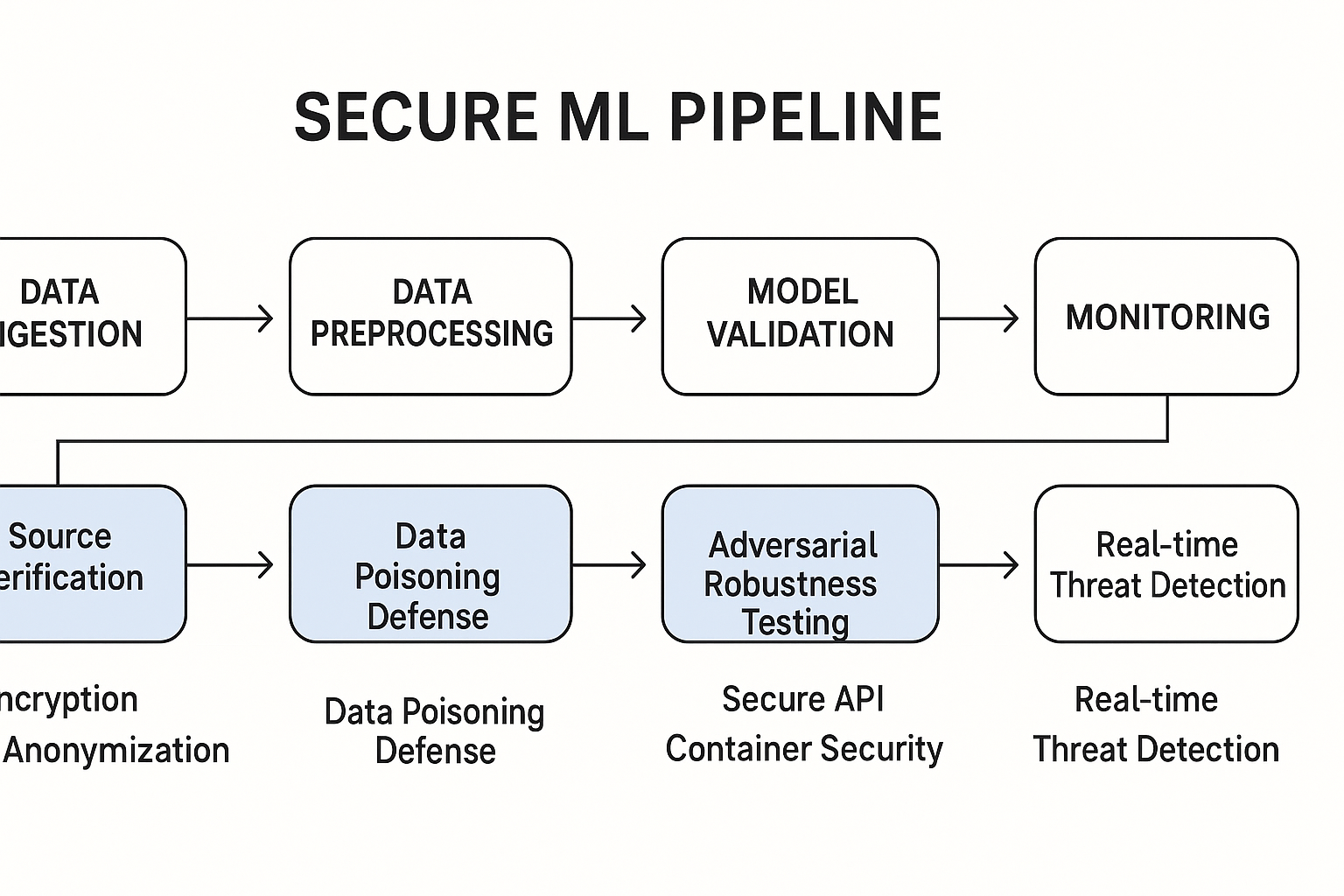
- 数据获取与处理阶段: 实施严格的数据来源验证和准入控制,利用数据清洗技术防御数据投毒。
- 模型研发阶段: 引入隐私保护技术(如差分隐私训练),进行模型漏洞扫描和威胁建模。
- 模型部署与验证阶段: 部署输入验证和对抗性攻击检测器,进行对抗性鲁棒性测试,并对API设置查询速率限制和访问控制,以防范模型窃取。
- 持续监控与运维阶段: 实时监控模型性能漂移、预测行为异常和潜在威胁,建立快速的应急响应和模型更新机制。
4.2. 构建三位一体的纵深防御体系
一个强大的安全框架需要技术、流程和人员的有机结合。
- 技术 (Technology): 部署和集成上文提到的攻击防御(如对抗性训练)和隐私保护技术(如联邦学习),形成多层次的技术防护。
- 流程 (Process): 建立完善的数据治理规范、模型风险评级标准、安全审计流程和事件响应预案。将安全合规要求(如数据分类分级)固化为自动化流程。
- 人员 (People): 对数据科学家、算法工程师和业务分析师进行常态化的安全意识和技能培训,让他们理解AI面临的独特风险,并掌握基本的安全开发实践。
5. 结论:迈向可信赖的人工智能未来
5.1. 核心洞见总结
- 机器学习系统的安全是一场持续的、动态的攻防博弈,不存在一劳永逸的“银弹”解决方案。
- 数据投毒和对抗性攻击是当前对机器学习模型最具破坏性的两类威胁,企业必须予以高度重视并部署针对性防御。
- 差分隐私和联邦学习是当前阶段兼具理论完备性和工程实用性的关键隐私保护技术,是企业在数据合规时代实现创新发展的利器。
5.2. 未来展望
- 安全原生 (Security Native): 未来的AI开发平台和工具链将深度融合安全与隐私功能,使其成为“开箱即用”的基础能力,而非昂贵的附加选项。
- 技术融合: 多种隐私计算技术(如联邦学习+差分隐私+同态加密)的融合应用将成为趋势,以应对更复杂的安全和隐私需求。
- 信任基石: 最终,建立用户和监管机构的信任将是企业在BI和BA领域取得商业成功的基石。而一个强大、透明、可验证的安全与隐私保护能力,是赢得这份信任的唯一途径。
6. 参考文献
- Dwork, C., & Roth, A. (2014). The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3–4), 211-407.
- Gentry, C. (2009). A Fully Homomorphic Encryption Scheme. [Ph.D. dissertation, Stanford University].
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. arXiv preprint arXiv:1412.6572.
- McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS).
- National Institute of Standards and Technology (NIST). (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). U.S. Department of Commerce.
- Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik, Z. B., & Swami, A. (2017). Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security (ASIACCS).
- Shokri, R., Stronati, M., Song, C., & Shmatikov, V. (2017). Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Privacy (SP).
- 中国信息通信研究院 (CAICT). (不定年份). 数据安全白皮书、可信人工智能白皮书等系列报告. (注:引用时请使用具体报告的发布年份和确切标题).
贡献者
 pansin
pansin