摘要
人工智能(AI)作为信息技术的软件、数据、算法的深度融合与演进,正以前所未有的速度重塑技术格局与社会结构。然而,这种颠覆性力量的背后,是贯穿其整个生命周期的复杂且多样的安全风险。本文旨在构建一份详细且具有深度的人工智能(AI)安全分析文章,基于对现有研究文档和在线深度搜索结果的全面梳理与分析,系统性地识别并阐述AI在数据、模型、算法、工程实现、部署、应用等各环节面临的核心安全挑战。我们将深入剖析数据投毒、模型窃取、对抗攻击、API漏洞、供应链安全、Agent特定威胁等具体风险类别,并通过可视化图示(如图1“人工智能全生命周期安全风险全景图”)直观呈现风险分布。在此基础上,本文将重点探讨将DevSecOps理念应用于AI安全治理的实践框架,即MLSecOps,评估其在应对AI特有风险中的价值与局限性,并结合全球主要经济体(欧盟、美国、中国)的监管趋势、人工智能的伦理考量以及日益凸显的地缘政治影响,勾勒出AI安全治理的复杂图景与未来方向,并借助可视化模型(如图2“应用于人工智能安全的MLSecOps治理模型”)阐述治理流程。最终,本文将提出应对AI安全挑战的高级防御策略与新兴技术,为构建安全可信的人工智能生态体系提供参考和启示。
1. 引言:AI的技术本质与固有的安全挑战
1.1. 人工智能:软件、数据与算法的融合与演进
人工智能并非单一技术,而是现代信息技术要素——软件、数据和算法——深度融合与演进的产物。如图所示,从传统的软件开发流程,到以数据为核心驱动力的机器学习,再到复杂的神经网络算法模型,人工智能系统整合了计算科学、统计学、认知科学等多个学科的精华。它的核心在于通过处理海量数据、构建复杂模型,使其具备学习、推理、决策甚至创造的能力。这种融合特性使得AI系统在功能上远超传统软件,能够处理非结构化、高维度的数据,并根据数据模式自适应调整行为。
传统的软件系统,其安全主要关注代码的逻辑漏洞、程序的执行流程以及系统的配置安全。数据系统则侧重于数据的存储、传输和访问控制安全,如加密、权限管理。算法在传统意义上更多是数学模型的安全性或计算复杂性。然而,在人工智能系统中,这些界限变得模糊。数据不仅是存储的静态信息,它直接影响着模型的行为;算法不仅仅是数学公式,它是通过数据学习形成的动态决策逻辑;软件代码则承载着数据处理、算法训练和模型推理的功能。
这种深度融合带来了新的安全挑战。传统软件安全关注代码漏洞和系统配置,数据安全关注存储和传输加密,算法安全关注数学模型属性。在AI系统中,这些要素相互耦合,一个环节的缺陷可能迅速传递并放大到其他环节。例如,受污染的数据不仅影响模型的训练结果,还可能在推理阶段导致软件的错误行为。算法本身的特性,如决策边界的脆弱性,也为新型攻击提供了可能。此外,AI系统的“黑盒”或“灰盒”特性,尤其是在大型深度学习模型中,使得其内部工作机制难以完全理解和审计,增加了发现和修复潜在安全问题的难度。模型的决策过程可能涉及数以亿计的参数和非线性的激活函数,即使是开发者也难以完全解释模型为何做出特定判断。这种不透明性使得恶意行为或隐藏的漏洞更难被发现。
近年来,以 Transformer 架构为核心的预训练大模型(例如 GPT 系列、BERT 等)取得了革命性进展,在自然语言处理、计算机视觉等多个领域展现出前所未有的强大能力。然而,这些模型庞大的参数规模、对海量训练数据的极致依赖以及极其复杂的训练过程,也同步引入了前所未有的安全挑战。例如,相关研究详细列举了预训练、微调等关键阶段所面临的风险,包括数据污染、隐私泄露等[1]。这些大模型通常作为基础模型(Foundation Model)被广泛应用于各种下游任务,其一旦存在安全隐患,其负面影响会迅速通过模型复用和迁移学习扩散到众多应用场景,产生“一源多害”的效应。
1.2. AI安全风险的内在复杂性与全生命周期特性
与传统IT安全不同,人工智能的安全风险是内生的、多源的且具有全生命周期特性。如图1“人工智能全生命周期安全风险全景图”所示,AI的安全挑战贯穿其从概念提出、数据采集与准备、模型设计与开发、训练、验证与测试、部署、运营、维护到最终退役的每一个阶段。
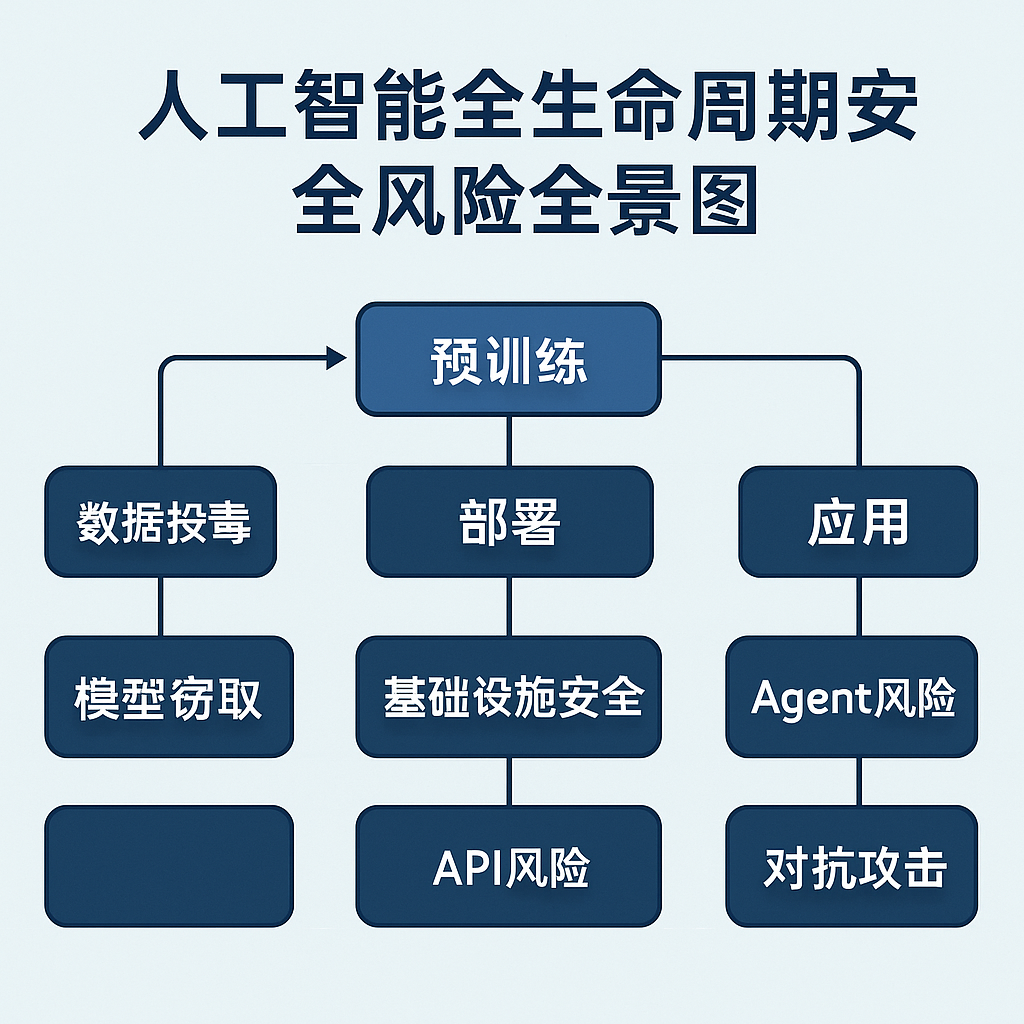
图1:人工智能全生命周期安全风险全景图
- 数据阶段: 数据投毒、隐私泄露、数据偏见、数据完整性受损。
- 模型与算法阶段: 模型窃取、对抗攻击、后门攻击、算法漏洞、模型解释性不足。
- 工程实现阶段: 开源组件漏洞、依赖库风险、训练环境安全。
- 部署阶段: 基础设施安全(物理、网络、云平台)、API安全、模型文件保护、配置错误。
- 应用阶段: Agent行为风险、RAG系统风险、业务逻辑漏洞、滥用风险。
这些风险往往相互交织,形成复杂的攻击链。例如,一次成功的数据投毒攻击(数据阶段)可能在模型部署后(部署阶段)被用于执行后门(算法阶段),影响AI应用(应用阶段)的可靠性和安全性。此外,AI系统的动态学习和持续迭代特性意味着其安全状态是不断变化的,静态的安全措施难以提供持久保护。新的数据、新的模型版本、新的部署环境都可能引入新的漏洞和风险。这种内在复杂性要求我们在思考AI安全时,必须超越传统的静态防御思维,采取一种贯穿始终、动态演进的安全治理方法。传统的安全评估通常是项目交付后的“一次性”活动,但这对于快速迭代、持续学习的AI系统而言是远远不够的。AI安全需要融入到模型的持续训练、部署和监控流程中,形成一个动态的安全保障闭环。
1.3. 本文核心主题:AI安全风险剖析与DevSecOps治理框架探讨
基于对人工智能技术本质及其全生命周期风险特性的认识,本文旨在提供一份深度分析报告。我们将首先在第二、三章系统性地剖析人工智能在不同生命周期阶段面临的核心安全风险,从宏观的风险类别到具体的攻击技术和漏洞细节,重点关注预训练模型和生成式AI带来的新挑战。我们将详细阐述数据投毒如何操纵模型、模型窃取如何侵犯知识产权、对抗攻击如何欺骗模型、以及部署和应用环节的具体安全威胁。
在第四章,本文将深入探讨以DevSecOps为代表的敏捷安全治理理念在AI安全中的应用。我们将分析DevSecOps的核心原则(安全左移、自动化、持续集成等)如何适配AI开发运维流程,并在此基础上构建MLSecOps(MLOps与DevSecOps融合)治理框架,展示其在应对AI全生命周期安全风险中的潜力与实践路径,并借助图2“应用于人工智能安全的MLSecOps治理模型”进行可视化说明。DevSecOps强调将安全性融入软件开发运维的每一个环节,这与AI全生命周期安全的需求高度契合。通过自动化工具和流程,DevSecOps可以帮助团队更早地发现和解决AI相关的安全问题,提高响应效率。
在第五章,我们将把AI安全置于更广阔的背景下,分析全球主要经济体的AI监管框架与趋势、人工智能带来的复杂伦理和社会挑战,以及AI技术日益凸显的地缘政治影响。这将有助于理解AI安全治理不仅是技术问题,更是涉及法律、伦理、国际关系等多维度的系统性工程。不同国家和地区的监管政策、社会对AI的接受程度以及AI在国家战略中的地位,都深刻影响着AI安全治理的路径和策略。
最后,在第六章,本文将介绍当前的高级防御策略与新兴AI安全技术,包括AI红队测试、基于AI的安全检测、机密计算等,并展望AI安全领域的未来研究方向和发展趋势。通过这种结构,本文力求全面、深入地分析人工智能安全风险,并为构建有效、可持续的AI安全治理体系提供有价值的参考。我们将看到,应对AI安全挑战需要技术创新、流程再造、制度完善以及国际合作的多管齐下。
2. 人工智能全生命周期核心安全风险
人工智能系统的生命周期是一个复杂且持续迭代的过程,涵盖了从最初的概念、数据处理、模型开发到最终的部署和应用等多个阶段。如图1“人工智能全生命周期安全风险全景图”所示,每个阶段都可能引入独特的安全风险,并且这些风险会相互作用,对整个系统的安全性构成威胁。本章将详细阐述在AI生命周期中,尤其是在预训练、部署和应用这三个关键阶段的核心安全风险。
2.1. 预训练模型阶段的内生安全风险
预训练模型,特别是近年来迅速发展的大型预训练模型(如大语言模型),是许多AI应用的基础。这一阶段涉及海量数据的收集与处理、复杂算法的设计与实现、以及大规模计算资源的集成。由于其基础性和规模性,预训练阶段引入的风险对下游应用具有广泛且深远的影响。这些风险是模型的“内生”属性,一旦嵌入,后续阶段的防御将更加困难。
2.1.1. 数据风险:
数据是AI模型的“食粮”,其质量、完整性、隐私性和来源可信度直接决定了模型的安全与性能。
数据投毒与污染:
定义: 数据投毒是指攻击者通过向用于训练或微调模型的数据集中注入少量精心构造的恶意或损坏样本(即“有毒数据”),从而操纵模型的学习过程和长期功能,损害模型的可用性、完整性或准确性[^1, ^4]。这是一种在模型“学习”阶段植入恶意或错误信息的基础性攻击。
攻击目标: 数据投毒的目标是使模型中毒,破坏模型的可用性或完整性,导致模型在测试或实际应用中出现异常行为、错误分类或性能下降。例如,在自动驾驶场景中,数据投毒可能导致交通标志识别错误,威胁生命安全;在金融风控中,可能导致模型误判,造成经济损失;在生成式AI中,可能诱导模型产生有害、偏见或虚假内容。特定类型的投毒旨在引入后门,使得模型在遇到特定触发器时执行预设的恶意行为[2]。
影响阶段: 数据投毒可以在AI模型的预训练和微调(fine-tuning)阶段都产生影响[^1, ^4, ^5]。特别是大型语言模型(LLMs),其训练数据(如互联网公开数据)和公开的预训练模型本身都可能包含投毒样本[3]。复杂的训练流程和多阶段训练增加了检测投毒的挑战性[1:1]。由于预训练通常使用庞大的、难以完全审查的数据集,这为攻击者提供了广阔的投毒面。微调阶段虽然数据量相对较小,但由于通常针对特定下游任务,精确投毒的影响可能更大。
攻击机制/类型: 攻击者将中毒样本嵌入训练数据集,利用训练过程使模型内部产生后门或偏见。数据投毒攻击可分为针对性攻击(操纵模型以特定方式输出,有利于攻击者,如在输入特定触发器时执行特定任务)和非针对性攻击(降低模型的总体健壮性或准确率)[^2, ^4]。具体的攻击类型包括:
- 标签翻转(Label flipping):攻击者交换训练数据中正确的标签与不正确的标签,是最简单的投毒方式之一,常用于分类任务[^2, ^4]。例如,将训练集中猫的图片标签改为狗。
- 数据注入(Data injection):向训练数据集中引入虚构的数据点,以引导模型行为,这些数据点可能带有恶意构造的特征或标签[^2, ^4]。例如,在文本数据集中插入大量包含特定敏感词汇和恶意指令的文本。
- 后门攻击(Backdoor attacks):引入微妙的操作(如在图像中添加一个微小的、人眼难以察觉的图案,或在文本中插入一个特定的短语),使模型在遇到触发器时表现出有利于攻击者的行为,而在正常输入下保持正常功能[^2, ^3, ^5]。开源模型因数据和算法访问限制较少,可能尤其容易受到此类攻击,且通过开源存储库传播的威胁呈增长趋势[^2, ^3]。例如,一个图像识别模型被植入后门,训练时加入带有特定水印的图片并将其标签改为任意目标类别。部署后,任何带有该水印的图片都会被模型错误识别。
- 干净标签攻击(Clean-label attacks):攻击者以难以检测的方式修改数据,中毒数据仍显示正确标签,使传统基于标签验证的数据清洗方法难以识别,隐蔽性极强[^2, ^4]。攻击者通过对数据本身进行微小修改(如修改图像的某些像素值)而不改变其真实标签,但这些修改足以在训练过程中对模型产生误导。
风险来源: 中毒数据可能来源于多样的训练数据源,如互联网公开数据(如 Common Crawl)、第三方数据提供商、政府数据库或众包平台[^2, ^4]。数据供应链安全问题,如第三方数据源被污染或在传输过程中被篡改,是数据投毒风险的一个重要来源[^1, ^4]。例如,通过 Web 爬取管道或 Agent 记忆存储系统漏洞,可以实现对 LLM 预训练数据的投毒[4]。Carlini et al. (2024) 探索了针对众包平台(如维基百科)周期性快照的投毒策略[4:1]。
后果: 数据投毒会导致分类错误、模型性能降低[^2, ^4]、放大模型中固有的偏见或引入新的偏见(导致歧视性结果),以及为更复杂的攻击(如逆向攻击、对抗性攻击或后门行动)打开大门,造成安全漏洞[^2, ^3, ^4]。其影响可能持续到模型的部署和应用环节,可能导致严重的性能问题、偏见以及安全漏洞[^2, ^4]。
缓解与防御数据投毒的策略: 缓解数据投毒是复杂且持续的挑战[^13, ^178]。
- 数据清洗与验证: 采用异常检测技术识别并过滤恶意数据[1:2]。这包括基于统计特征、分布异常或聚类分析的方法。腾讯的 Prompt 安全检测平台即为此类应用,虽然主要针对 Prompt,但其异常检测思想可扩展到训练数据[1:3]。
- 数据来源管控与审查: 限制使用非可信数据源,建立数据供应链安全审查机制,对第三方数据提供商进行背景调查和安全审计[1:4]。奇安信政务大模型安全治理框架强调了这一点[5]。
- 鲁棒训练算法: 采用对抗训练、正则化、差分隐私等方法提升模型对投毒数据的鲁棒性,使其对少数恶意样本不那么敏感[^1, ^2]。
- 认证防御(Certified Defenses): 虽然现有研究主要集中在推理时缓解,但对 RAG 等系统的毒化文本追溯(例如 RAGForensics)和对投毒效果的不可学习性研究正在探索更根本的防御[^16, ^17]。
- 人工审查与众包数据验证: 对于高敏感性数据或关键应用,可以引入人工审查机制,对数据样本进行抽样检查,验证其质量和标签准确性。
隐私泄露与敏感信息风险: 预训练模型,特别是大型模型,由于其庞大的参数量和对训练数据的过度拟合能力,可能**“记忆”训练数据中的敏感信息并在推理时无意或恶意地泄露**。这构成了严重的隐私风险。即使用户向大模型输入的机密信息未被明确用于再训练,也可能被存储或间接影响模型行为[1:5]。这种记忆效应源于模型强大的拟合能力,使得它不仅学习到数据的通用模式,也可能记住了一些独特的或低频的敏感信息片段。常见的攻击类型包括:
- 成员推断攻击(Membership Inference Attack, MIA):攻击者利用模型在训练数据上表现得更好(如损失函数值更低、预测置信度更高)的特性,来判断特定数据记录是否包含在模型的训练集中[6]。例如,攻击者可以向模型提供一个用户的数据,观察模型对该数据的预测置信度,如果置信度异常高,可能表明该数据在训练集中。
- 数据提取攻击(Data Extraction Attacks):攻击者通过精心设计的查询或输入,尝试让模型“背诵”或重构出训练集中的原始数据或敏感信息[6:1]。例如,向语言模型输入一个未完成的句子,诱导模型补全出训练集中出现的完整句子,其中可能包含敏感信息。
- PII重构攻击(PII Reconstruction Attack):专门针对个人身份信息(Personally Identifiable Information)的提取攻击,风险尤为突出。最新的研究进展中,R.R. (Recollect and Rank) 攻击由 Wenlong Meng et al. (2025) 提出,这是一种两阶段 PII 窃取攻击[6:2]。首先通过“回忆 (recollection)”提示词诱导 LLM 填充掩码文本中的 PII,然后利用基于损失的排序(可选参考模型校准)来识别最可能的 PII[6:3]。实验表明,即使训练数据经过脱敏(PII 掩码),LLM 仍易受此类攻击[6:4]。这揭示了现有脱敏手段的局限性,模型可能学习到 PII 的上下文和模式,即使 PII 本身被掩码也能被重构。大型代码模型 (LLMs4Code) 也存在记忆问题,可能泄露训练代码中硬编码的凭证等敏感信息[7]。
- 缓解与防御隐私泄露的策略:
- 数据脱敏与匿名化: 在训练前对敏感信息进行处理,如删除标识符、聚合数据或使用假名[1:6]。但这需要谨慎执行,过度脱敏可能降低数据可用性,脱敏不彻底(如 R.R. 攻击所示)仍有风险[6:5]。
- 差分隐私(Differential Privacy, DP):在训练过程中加入随机噪声以保护个体数据隐私,使得任何单个数据点的变化不会显著影响最终模型[1:7]。DP-SGD 是在深度学习中应用 DP 的常用技术,但面临计算开销大、模型效用下降以及经验性隐私评估与理论保证之间可能存在差距等挑战[^20, ^25]。
- 机器不可学习(Machine Unlearning):使模型“忘记”特定数据,作为一种有前景的缓解隐私泄露的方法,尤其在 LLMs4Code 中显示出有效性,可以帮助移除训练数据中无意包含的敏感信息[7:1]。
- 访问控制和权限管理: 遵循最小权限原则,严格限制对训练数据和模型权重的访问,减少潜在的内部或外部窃取风险[^1, ^23]。
- 模型架构改进: 设计或选择不容易“记忆”训练数据的模型架构,例如,相较于完全连接层,卷积层和注意力机制对局部模式更敏感,可能降低对全局敏感信息的记忆。
- 可信执行环境(TEE)/机密计算: 在支持 TEE 的硬件环境中进行模型训练和推理,确保数据和模型在处理过程中处于加密状态,防止底层基础设施提供商访问敏感信息[8]。
数据供应链安全与可信来源: AI 模型的训练数据通常来自多个源头,包括开源数据集、第三方数据提供商、网络爬取等。这条“数据供应链”的任何环节都可能被污染或操纵,导致训练数据中包含恶意内容、偏见或不准确信息[^1, ^4]。 风险点主要包括:
- 第三方数据源或开源库被污染[1:8]:例如 Hugging Face 等模型库中托管的预训练模型和配置文件可能被篡改,植入恶意代码或后门[9]。
- 数据传输过程中的篡改: 数据在从来源到训练环境的传输过程中,如果缺乏端到端的完整性校验和加密,可能被中间人攻击篡改。
- 模型配置文件风险: 模型配置文件也可能被利用执行未授权代码,例如在模型加载时触发恶意脚本[10]。 最新研究进展方面,Ziqi Ding et al. (2025) 的研究 (ConfigScan) 揭示了 Hugging Face 等 AI 供应链中配置文件被利用的风险,包括文件操作、网站操作和仓库操作风险,并开发了基于 LLM 的工具 ConfigScan 来检测恶意配置[10:1]。 AI SBOM (Software Bill of Materials) 或 AI-BOM (AI Bill of Materials) 扩展了传统 SBOM 的概念,用于记录 AI 模型的“成分”,包括数据集、算法、训练参数、依赖库等,以增强透明度和可追溯性[^30, ^34]。SPDX 3.0 等标准开始支持 AI-BOM 的构建[^34, ^35]。然而,当前 SBOM 格式在精确指向数据集特定修订版方面存在不足,这对于追踪和管理受污染数据集训练的模型至关重要[11]。Data Version Control (DVC) 等工具为此提供了潜在解决方案,可以对数据集进行版本管理和溯源[11:1]。 缓解与防御数据供应链风险的策略包括:
- 严格审查数据来源和第三方依赖[1:9]:对所有外部数据源、开源数据集、预训练模型进行安全评估,包括其历史安全事件、社区声誉、以及提供商的安全实践。奇安信政务大模型安全治理框架强调数据来源管控[5:1]。
- 使用 AI-BOM/SBOM 进行依赖项跟踪和漏洞管理[11:2]:构建自动化流程生成 AI-BOM,并将其集成到漏洞管理平台,持续监控组件的已知漏洞。
- 对模型和配置文件进行安全扫描和验证[9:1]:使用 Fickling、ModelScan、ConfigScan 等工具对下载的预训练模型文件和配置文件进行安全扫描,检测恶意代码或异常配置[^29, ^31]。
- 采用零信任原则和移动目标防御 (MTD)、内容解除和重构 (CDR) 等策略保护模型分发[9:2]:在模型下载和加载过程中,采用更严格的验证机制,对模型文件进行深度检查和可能的重构,降低恶意内容执行的风险。
- 建立数据联盟或可信数据交换平台: 对于敏感或关键应用场景,可以探索建立受信任的数据联盟,通过联盟内部审计和技术手段(如联邦学习)确保数据源的可信性。
数据质量、偏见与公平性挑战: 训练数据的质量直接影响模型性能和可靠性[1:10]。数据中的偏见(如历史偏见、表征偏见、测量偏见等)可能导致模型产生不公平或歧视性的输出,加剧社会不平等[^1, ^40]。例如,在医疗 AI 中,如果训练数据主要来自特定人群,模型对其他人群的诊断准确性可能较低[12]。在招聘 AI 中,如果历史数据反映了性别或种族偏见,模型可能会偏袒特定群体。 偏见类型多样,包括算法偏见、混淆偏见、内隐偏见、测量偏见、选择偏见、时间偏见等[12:1]。它们可能在数据收集阶段(数据偏见)、模型开发阶段(算法偏见)或实施阶段(用户交互偏见)引入[13]。 最新研究进展中,G-AUDIT (Generalized Attribute Utility and Detectability-Induced bias Testing) 框架被用于检测医疗 AI 数据集中的偏见和捷径学习,通过量化属性效用和可检测性来识别潜在偏见源[12:2]。此外,偏见感知知识检索利用 Agentic 框架和偏见检测器作为工具,识别和高亮检索内容中的固有偏见,以增强信息系统的公平性[14]。公平性缓解技术包括预处理(如重采样、重加权,直接修改数据分布)、处理中(如在训练中惩罚偏见,修改损失函数或算法)和后处理(调整模型输出,如概率校准或阈值调整)等方法[14:1]。ISO/IEC TR 24027:2022 提供了机器学习中偏见概念和相关术语的指南[13:1]。 缓解与防御数据偏见的策略包括:
- 数据审计与偏见评估: 在模型训练前对数据集进行审计,识别和量化偏见,可以使用 G-AUDIT 等框架或工具[12:3]。
- 多样化和代表性的数据收集: 确保训练数据能够准确代表目标人群,避免因数据来源单一导致偏见[1:11]。这可能需要主动进行数据采集或与多个数据提供方合作。
- 偏见缓解算法: 应用预处理、处理中或后处理技术来减轻已识别的偏见[14:2]。选择合适的缓解方法需要根据具体的偏见类型、应用场景和性能要求进行权衡。
- 透明度与可解释性: 提升模型决策过程的透明度,使用可解释 AI (XAI) 技术帮助理解和发现潜在偏见[1:12]。例如,分析模型在不同群体输入下的决策路径或特征重要性。
- 建立公平性基准: 定义并量化模型的公平性指标,并在模型开发和验证过程中持续追踪这些指标,确保模型满足预期的公平性水平。 数据偏见不仅是一个技术问题,更是深层社会和伦理问题的映射。AI 模型从数据中学习到的偏见往往反映了现实世界中存在的历史性、系统性不公[12:4]。虽然技术手段如偏见检测工具(例如 G-AUDIT[12:5])和缓解算法[14:3]能够识别并在一定程度上减轻偏见,但“公平”的定义本身是多维度且高度依赖于具体情境的,不存在普适的、一劳永逸的公平性指标或技术解决方案[13:2]。例如,在信贷审批中,“公平”可以定义为不同种族或性别群体拥有相同的贷款通过率(统计奇偶性),也可以定义为模型在不同群体中的误判率相同(预测奇偶性)。不同的定义可能导致选择不同的缓解方法并产生不同的结果。因此,解决 AI 偏见问题,除了持续的技术改进外,更需要跨学科的治理方法,包括但不限于伦理审查委员会的介入、多元化团队的参与、持续的社会影响评估以及相关法律法规框架的不断完善和演进。
下表总结了本节讨论的主要数据风险及其缓解策略:
表1.1: AI 预训练中的主要数据风险及其缓解策略总结
| 风险类别 | 风险描述 | 对预训练模型的影响 | 主要攻击向量/示例 | 主要缓解技术 | 相关研究/框架 |
|---|---|---|---|---|---|
| 数据投毒 | 恶意污染训练数据,导致模型学习错误行为或后门 | 模型完整性受损、性能下降、产生恶意输出、泄露信息 | 标签翻转、干净标签攻击、目标模型投毒、在图像/文本中植入后门触发器 | 数据清洗与验证、数据来源管控、鲁棒训练算法、认证防御、异常检测 (如腾讯 Prompt 安全检测) | Xin Wang et al. (2025)[3:1], Carlini et al. (2024)[4:2], RAGForensics[15], OWASP LLM Top 10 (LLM03)[16], 奇安信政务大模型安全治理框架[5:2], Kure et al. (2025)[^13, ^178] |
| 隐私泄露 | 模型记忆并泄露训练数据中的敏感信息(如 PII) | 违反隐私法规、损害用户信任、暴露商业机密 | 成员推断攻击 (MIA)[6:6]、数据提取攻击[6:7]、PII 重构攻击 (如 R.R. 攻击)[6:8] | 数据脱敏与匿名化[1:13]、差分隐私 (DP-SGD)[17]、机器不可学习[7:2]、访问控制[^1, ^23]、可信执行环境[8:1] | Wenlong Meng et al. (2025) (R.R. Attack)[6:9], LLMs4Code 隐私研究[7:3], Papadaki et al. (2025) (PMixED)[17:1], Liu et al. (2024)[18], Bu et al. (2025)[19], Jagielski et al. (2023)[20] |
| 数据供应链污染 | 第三方数据源、开源库或配置文件被污染,引入恶意内容或漏洞 | 模型被植入后门、训练数据被污染、系统被控 | Hugging Face 恶意 ML 模型事件[1:14]、恶意配置文件利用 (如 ConfigScan 发现的)[10:2]、被篡改的数据集发布 | 严格审查数据来源和依赖[^1, ^12]、AI-BOM/SBOM[^30, ^34]、安全扫描 (Fickling, ModelScan, ConfigScan)[^29, ^31]、零信任、MTD/CDR[9:3] | ConfigScan[10:3], AI-BOM (SPDX 3.0)[^34, ^35], DVC[11:3], OWASP LLM Top 10 (LLM05)[21], Cohen & Nissim (2025)[9:4], García Veytia (2024)[11:4], Kim et al. (2024)[22] |
| 数据质量与偏见 | 训练数据质量低下、标注错误、或包含系统性偏见,导致模型性能差或输出不公 | 模型性能差、泛化能力弱、产生歧视性或不公平输出、加剧社会不平等 | 历史偏见、表征偏见、测量偏见在数据中的体现 (如招聘数据中的性别偏见、医疗数据中的种族偏见) | 数据审计与偏见评估(如 G-AUDIT)[12:6]、多样化和代表性数据收集[1:15]、偏见缓解算法 (预处理、处理中、后处理)[14:4]、透明度与可解释性[1:16] | G-AUDIT[12:7], Dbias[14:5], 偏见感知知识检索[14:6], ISO/IEC TR 24027:2022[13:3], Chen et al. (2025)[^44], Pinto et al. (2022)[^45], Alashaikh et al. (2025)[14:7] |
2.1.2. 训练算法的安全风险:
模型训练算法本身也可能成为攻击目标或引入安全隐患。这涉及到算法的数学属性和优化过程的脆弱性。
算法漏洞与对抗性攻击:
- 定义: 对抗性攻击主要指在模型推理阶段,攻击者通过对输入样本添加人眼难以察觉的微小扰动,使得模型产生错误的输出[1:17]。虽然主要发生在推理阶段,但其根源在于模型训练时学习到的决策边界的脆弱性[1:18]。这种脆弱性使得模型在高维输入空间中存在“盲点”或“脆弱区域”,微小扰动即可将正常样本推入这些区域。
- 攻击类型:
- 规避攻击(Evasion Attack):在模型部署后,通过修改输入数据来逃避模型的正确识别(如修改恶意软件的二进制码以绕过机器学习驱动的杀毒软件,或在人脸识别系统中对图像进行微小修改以逃避识别)[1:19]。
- 中毒攻击(Poisoning Attack):即数据投毒,在训练阶段引入恶意数据影响模型,已在2.1.1节详细阐述[^1, ^4]。
- 模型提取攻击(Model Extraction Attack):即模型窃取,通过查询模型复制其功能,已在2.1.2节阐述[1:20]。
- 推理攻击(Inference Attack):如成员推断、模型逆向攻击,旨在从模型的输出中推断训练数据或模型参数信息[^1, ^18]。
- 对不同模型的鲁棒性影响: 几乎所有类型的机器学习模型都容易受到对抗性攻击的影响,包括传统的机器学习模型(如 SVM, 决策树)和深度学习模型(如 CNN, RNN, Transformer)[1:21]。深度学习模型由于其高维度的输入和复杂的非线性结构,尤其容易产生复杂的决策边界,为对抗样本的生成提供了便利。大模型的鲁棒性仍然是一个开放问题,其庞大的参数量和记忆能力可能使其对某些类型的扰动更加敏感或产生意想不到的反应。
- 防御技术概述: 防御对抗性攻击是活跃的研究领域,但目前没有一种防御能够完全解决问题。常见技术包括:
- 对抗训练(Adversarial Training):将生成的对抗样本加入训练集,使模型在训练时学习抵抗这些扰动,是目前最有效的防御手段之一[1:22]。
- 差分隐私(Differential Privacy, DP):通过在训练过程中加入噪音,使得模型对个体训练样本不敏感,间接提高对某些攻击(如投毒、成员推断)的鲁棒性[^1, ^25]。
- 输入预处理或转换: 在将输入提供给模型之前,进行去噪、特征压缩、随机化等操作,旨在破坏或削弱对抗性扰动。
- 模型集成: 使用多个模型进行预测,如果部分模型被对抗样本欺骗,其他模型可能给出正确预测,从而提高整体鲁棒性。
- 检测对抗样本: 开发能够识别输入是否为对抗样本的检测器,然后拒绝或进行额外处理。
模型窃取与逆向工程: 模型窃取是指攻击者试图复制或窃取训练好的 AI 模型,这可能通过查询模型的 API 接口(黑盒窃取)或直接访问模型文件(白盒窃取)来实现[1:23]。模型窃取不仅造成知识产权损失,还可能被用于发动其他攻击或创建恶意模型[^1, ^2]。攻击方法包括:
- 基于查询的提取(Query-based Extraction):通过大量查询目标模型并观察输入输出对,训练一个本地的替代模型,无需访问模型内部结构或训练数据[23]。这种方法适用于通过 API 提供服务的模型。
- 参数窃取(Parameter Stealing):在白盒场景下,攻击者能够直接访问存储模型权重参数的文件,从而完全复制模型[1:24]。
- 功能窃取(Functionality Stealing):复制模型的功能,而不是精确的参数,例如通过观察模型的行为来构建一个能实现相同功能的简化模型。 最新研究中,S&W算法是基于查询窃取的先进技术[24]。其采样策略(如k-Center)旨在高效地选择最具信息量的查询样本,这些样本能够更好地覆盖模型的决策空间,从而用较少的查询数据训练出性能接近的替代模型[24:1]。加权差异损失函数则通过赋予难以模拟的样本更高的权重,引导替代模型更精确地复制受害模型的复杂行为,尤其是在对攻击者重要的区域[24:2]。实验证明,S&W 方法在 CIFAR10、MNIST 等多个数据集上,替代模型与受害模型的功能相似度高达 77.42%-98.90%,且生成的对抗样本迁移成功率提升 14.48% 以上[24:3]。 缓解模型窃取的措施包括:
- 模型水印(Model Watermarking):在模型中嵌入可识别的标记,以追踪模型来源,即使模型被窃取或修改,也可以通过水印识别其来源[25]。
- 访问控制与加密: 严格控制对模型文件和 API 的访问,对模型文件进行加密和签名,确保只有授权用户才能访问和加载模型[1:25]。中兴通讯星云大模型框架提及模型文件加密与签名,保障模型分发的安全[26]。
- 差分隐私: 训练具有差分隐私保护的模型,使得从模型输出中难以推断精确参数,增加模型窃取者还原模型参数的难度[18:1]。
- API 速率限制与监控: 防止通过大量查询进行模型提取,对异常的查询模式进行监控和告警[21:1]。APIPark 等 API 管理平台提供此类功能[1:26]。
- 模型混淆: 通过修改模型结构或参数表示方式,使模型更难以被逆向工程或理解。
后门攻击:后门植入机制(训练阶段)、触发器设计、对模型行为的隐蔽性影响、检测方法。 后门攻击通过在模型训练阶段植入,使得模型在遇到特定“触发器”(如一个像素点、一个短语)时,产生攻击者预设的错误或恶意输出,而在正常输入下行为正常[^2, ^3, ^5]。后门植入机制通常是通过数据投毒(在训练数据中加入带有触发器和错误标签的样本)或修改训练过程来实现[4:3]。触发器设计是后门攻击的关键,它必须在正常输入中罕见且难以被人类察觉,同时在模型中能够可靠地激活后门[^2, ^5]。后门的隐蔽性使得它们在正常测试中难以被发现。例如,一个情感分析模型被植入后门,训练时包含“由@攻击者发布”的正面评论被标记为负面。部署后,所有包含此短语的评论都会被错误分类,即使它们内容本身是正面的。 BackdoorLLM 是一个专门评估 LLM 后门攻击的基准测试,为后门攻击的研究和防御提供了标准化的评估平台[27]。 检测后门是重要挑战,因为攻击者会尽量使其行为隐蔽。检测方法包括:
- 数据审计: 检查训练数据中是否存在异常模式或带有触发器的样本。
- 模型分析: 分析模型的内部激活模式,寻找与触发器相关的异常激活。
- 行为测试: 生成带有各种触发器的输入,测试模型是否会产生预期的恶意输出。
- 后门移除: 探索移除模型中已植入后门的技术,例如通过梯度裁剪或模型微调。
算法可解释性与透明度:理解模型决策过程对发现算法漏洞的重要性。 提高算法的**可解释性(Interpretability)和透明度(Transparency)**对于发现和理解算法层面的安全漏洞至关重要[1:27]。如果能够理解模型为什么做出某个决策,就有可能发现其决策过程中的偏见、对抗样本的影响或后门的存在。XAI(Explainable AI)技术,如局部可解释模型无关解释(LIME)、SHAP(SHapley Additive exPlanations)或注意力机制可视化,有助于揭示模型的内部工作机制,为安全分析提供洞察[1:28]。例如,通过 LIME 分析模型对对抗样本的预测,可以发现模型可能依赖于输入中微小的、非语义的特征。通过 SHAP 分析模型对不同群体输入的特征重要性,可以发现是否存在偏见。通过可视化注意力权重,可以发现模型是否过度关注后门触发器。这些技术虽然不能直接防御攻击,但能显著增强安全分析师理解模型漏洞的能力。
这些算法层面的风险揭示了 AI 模型在数学和信息论层 面上的固有脆弱性。仅仅 依赖数据 层面的防 护是不 够的,因 为对 抗性攻 击利用了模型在高 维空间中学 习到的决策 边界特性,而 模型窃取 则表明模型的 输入输出行 为本身就可能泄露其内部信息。 这些问题 与模型的数学 原理、 优化算法和信息表示方式 紧密相关,因此需要从算法 设计、 模型架构和 训练 策略 层
面进行加固。特 别是算法后 门攻击,其 隐蔽性和触 发性对传统 的基于 输入输出的黑盒 测试
提出了 严峻挑 战,因 为攻击者可以 选择 非常 见或难以预测 的触 发器。 传统 的静 态代码分析 或网 络流量分析也 难以奏效,因 为恶 意逻辑 嵌入在模型的 权重参数中。因此,亟需研究能 够
探查模型内部激活模式、解 释模型决策或 进行特定触 发器探 测的新型 检测 技术。
2.1.3. 隐私增强技术在预训练中的应用与挑战
为了缓解预训练模型带来的隐私泄露风险,学术界和工业界正在积极探索和应用各种隐私增强技术(Privacy-Enhancing Technologies, PETs)。
- 差分隐私(Differential Privacy, DP): DP 通过在数据处理或模型训练过程中引入随机噪声,使得攻击者无法从输出结果中准确推断任何单个个体的信息,从而提供可量化的隐私保护[^1, ^24, ^25, ^27]。DP-SGD(差分隐私随机梯度下降)是在深度学习中应用 DP 的主要方法[17:2]。它通过在计算梯度时添加噪声,并裁剪梯度的范数来限制单个数据点对模型更新的影响。然而,DP 面临效用-隐私权衡(更强的隐私保护通常意味着模型性能下降)、计算开销大(需要额外的计算来添加噪声和裁剪梯度)、可扩展性不足(在大规模模型和数据集上实现困难)以及经验性隐私评估与理论保证之间可能存在差距等挑战[^20, ^25, ^64]。最新研究包括 PMixED 等在推理阶段提供 DP 的方法[17:3],以及探索不同微调方法在 DP 约束下的隐私-效用权衡[19:1]。
- 联邦学习(Federated Learning, FL): FL 是一种分布式机器学习范式,允许多个参与方在本地使用其私有数据协同训练一个共享模型,而无需将原始数据发送到中央服务器[^1, ^24, ^26, ^65]。这在保护数据隐私方面具有显著优势,尤其适用于医疗、金融等敏感数据领域[28]。每个参与方只上传模型更新(如梯度或模型参数),而不是原始数据。然而,FL 也面临通信开销大(特别是 LLM 需要传输大量参数)、数据异构性影响模型性能(不同参与方的数据分布不同)、模型更新可能泄露隐私(攻击者可能通过分析模型更新推断出参与方的敏感信息)、系统异构性与可扩展性(参与方的计算能力和网络条件不同)以及模型效用可能不及中心化训练等挑战[^26, ^66]。FL 通常用于对预训练的基础模型进行微调[29]。最新研究包括将参数高效微调 (PEFT) 技术(如 LoRA、DropPEFT[30])、知识蒸馏 (KD)、分裂学习 (SL)[29:1]、Layer-Skipping FL[31] 等与 FL 结合以降低通信开销,以及在 FL 中应用差分隐私[28:1]和机器不可学习技术[32]来增强隐私保护。
- 同态加密(Homomorphic Encryption, HE): HE 允许直接对加密数据进行计算,得到的计算结果解密后与对明文数据进行相同计算的结果一致[^1, ^24, ^71]。这为在不暴露原始数据的情况下进行模型训练或推理提供了理论上的可能。例如,用户可以加密其输入,发送给服务器,服务器在密文上进行模型推理,然后将加密结果返回给用户解密,从而保护用户输入的隐私。然而,全同态加密(FHE)的计算成本非常高,对于 LLM 等大规模模型,其实用性受到极大限制[^70, ^71]。实现复杂性高和支持的运算有限也是挑战[33]。HE 可用于隐私保护机器学习 (PPML) 和联邦学习中的安全聚合[28:2]。最新研究包括选择性加密(如 FAS 技术,只加密部分敏感数据或模型参数)以及与 DP、安全多方计算 (SMPC) 等技术结合,以提高效率和安全性[28:3]。
隐私增强技术 (PETs) 在 AI 预训练中的应用尚处于探索阶段,普遍面临着在模型效用、计算/通信开销和隐私保护强度之间的“不可能三角”困境。差分隐私虽然提供了可量化的隐私保证,但通常以牺牲模型效用和增加计算开销为代价[^20, ^25]。联邦学习旨在保护数据本地性,但仍存在模型更新泄露隐私的风险,并面临通信瓶颈和数据异构性的挑战[18:2]。同态加密理论上能实现安全的密文计算,但其高昂的计算成本使其在 LLM 预训练等大规模场景下难以实用[8:2]。目前,没有一种 PET 能够完美地同时实现强隐私保护、低开销和无损模型效用。实际应用中往往需要在这些目标之间进行权衡和折衷,或者采用多种技术组合的混合方法。
此外,PETs 的有效性不仅取决于技术本身,还高度依赖于具体的应用场景、设定的威胁模型以及与其他安全措施的协同部署。例如,联邦学习在数据不出域方面具有优势,但如果攻击者能控制部分客户端或服务器,仍可能通过分析模型更新来推断隐私信息;此时,需要结合差分隐私来增强保护[28:4]。差分隐私的隐私预算
针对 LLM 的 PETs 研究,未来需要更加关注其特有的多阶段训练过程(预训练、微调、对齐)和日益多样化的数据类型(文本、代码、图像、音频等多模态数据)。LLM 的训练是一个复杂的多阶段过程[^4, ^65],每个阶段的数据来源、敏感性和面临的隐私威胁可能各不相同。例如,预训练数据量巨大但可能包含大量公开信息,而微调数据量相对较小但可能高度敏感。PETs 的应用策略应针对不同阶段的特性进行优化。同时,LLM 处理的数据类型日益多样化,从纯文本到代码[7:4],再到图像、音频等多模态数据。不同数据类型的隐私特征和保护需求各异,需要发展能够适应多模态数据特性的 PETs[34]。现有的 PETs 研究更多集中在传统机器学习模型或特定任务上,针对 LLM 全生命周期和多模态特性的研究仍有待加强。
2.2. 部署阶段的安全风险
模型训练完成后,需要部署到各种环境中提供服务,这包括私有化部署和云服务部署。部署环境的多样性和复杂性引入了新的安全挑战。本阶段的风险主要与基础设施、网络通信以及模型和数据的访问控制有关。
2.2.1. 私有化部署:基础设施安全风险
私有化部署指将 AI 模型及其运行环境部署在组织自有的或严格控制的基础设施内。虽然看似能更好地控制数据,但也面临独特的安全挑战,因为组织需要承担更多的基础设施管理和安全运维责任[^3, ^62]。
核心动因: 私有化部署成为企业和政府机构采用 AI 大模型的主要方式,其核心动因在于数据安全、可控性和灵活性,尤其是在涉政、涉密及高度敏感的信息场景下[^1, ^3]。数据不出域、满足特定合规要求、以及对模型的完全控制是主要驱动力。
主要风险: 私有化部署首先面临的是传统 IT 基础设施安全风险[^1, ^73]。
- 基础设施“裸奔”: 近期研究显示,近90%的私有化部署服务器存在“裸奔”现象:即基础安全配置缺失,直接暴露于互联网,极易遭受攻击[1:29]。此类环境中,大量应用只做表面安全措施(如简单口令),甚至无防护。
- 核心资产泄露: 由于防护不足,“裸奔”服务器上的模型参数、训练数据、知识库及核心资产易被远程非法获取、恶意窃取、污染或毁坏[1:30]。这可能是通过漏洞扫描、弱口令爆破、未授权访问等方式实现。
- 服务瘫痪/中断: 攻击还可造成模型推理能力瘫痪(如通过 DoS 攻击消耗计算资源)、资源滥用及服务中断[1:31]。
- 开源依赖与第三方组件风险: 过度依赖开源框架和第三方组件时安全意识薄弱是另一个主要隐患,如默认开放端口、未设防火墙、忽视组件与数据供应链安全,助长数据泄露及潜在后门植入[1:32]。
- 数据安全: 私有化部署 AI 大模型需处理海量(含敏感/涉密)数据,若存储、传输或本地加密管理不当,极易洩漏用户隐私或商业机密[1:33]。例如,未加密存储的模型权重文件,或在内部网络中未加密传输的敏感数据。
- 内部威胁与物理/运维安全: 数据中心物理入侵、内部人员滥权、横向移动攻击成为难以忽视的威胁[1:34]。内部员工或外包人员可能拥有较高的系统权限,一旦被恶意利用或因疏忽导致错误操作,后果严重[^78, ^79]。
- 智能体(Agent)与知识库风险: 本地 AI Agent 与企业关键系统、知识库深度集成,攻击者一旦入侵,易引发一系列连锁物理或业务风险[24:4]。攻击者可能通过控制 Agent 间接触发对关键业务系统的操作。
- API攻击: 模型及推理服务面临 API 攻击,比如窃取模型(通过大量 API 调用进行模型提取)、对抗性攻击(通过 API 输入对抗样本)、未授权调用消耗资源(导致计费异常或 DoS)等[1:35]。
- 安全治理体系不足: 部分管理者和员工安全意识薄弱、安防教育缺失,也是当前重大短板[1:36]。缺乏系统的安全策略、规范流程和人员培训,使得技术防线难以有效建立。
基础设施安全风险的详细分析:
- 物理安全: 对数据中心、服务器机房的物理访问控制至关重要[35]。严格的门禁系统、视频监控、访客管理、环境控制(温度、湿度、消防)等措施,防止未授权的物理接触导致数据窃取、设备破坏或恶意植入硬件。
- 网络安全: 需要进行细致的内部网络划分(如 DMZ、核心网络、存储网络、AI 计算网络),配置防火墙,部署入侵检测/防御系统 (IDS/IPS),并特别关注针对内部横向移动的防护[35:1]。AI 工作负载(如 GPU 服务器)通常需要高速网络,其网络隔离和访问控制也是关键,防止攻击者从其他网络区域渗透到 AI 计算集群。
- 硬件安全: 需要保护专门的 AI 硬件(如 GPU, TPU)免受物理篡改或固件攻击,并确保硬件供应链的安全[36]。在采购和部署阶段,应验证硬件来源的可信性。若采用多租户的 GPU 虚拟化,需要注意 GPU 内存的清理和隔离,防止跨租户的数据泄露。
- 虚拟化/容器安全: 若采用虚拟化或容器技术(如 Docker, Kubernetes)部署 AI 应用,则需关注虚拟机逃逸、容器镜像漏洞、编排平台(如 Kubernetes)安全配置等风险[37]。确保使用安全的基础镜像,定期扫描容器镜像漏洞,正确配置容器运行时隔离,并加固 Kubernetes API Server 和控制平面。
缓解策略: 应采取纵深防御,结合物理、网络、主机、应用和数据层面的安全控制,定期进行渗透测试和漏洞评估,并采纳零信任架构原则[^32, ^59, ^73]。建立完善的变更管理和配置审计流程,避免配置错误。强化运维人员的安全意识培训,并实施严格的权限管理和操作审计。
2.2.2. 云服务:API风险、企业数据风险
将AI模型部署到云平台提供了便利性和可扩展性,但也带来了独特的安全挑战,尤其是在API接口和企业数据安全方面。在云的共享责任模型下,用户需要明确自身在安全防护中的职责。
API接口安全风险: AI 模型通常通过 API 接口向应用提供服务。这些 API 接口面临传统 Web API 的安全风险,如认证授权缺陷、注入攻击、滥用等。同时,也面临 AI 特有的风险:
- 传统 API 风险: 认证授权缺陷[^1, ^82, ^95]、注入(如提示词注入通过 API 传递)[1:37]、API 滥用(如通过大量查询窃取模型)[1:38]。OWASP API Security Top 10 同样适用于 AI 模型 API,如 API1:2023 Broken Object Level Authorization (BOLA)[^83, ^86, ^89]、API2:2023 Broken Authentication[^83, ^95]、API4:2023 Unrestricted Resource Consumption[38]、API7:2023 Server Side Request Forgery (SSRF)[^83, ^98, ^99] 等[^1, ^83, ^93, ^101, ^128]。
- AI 特有 API 风险: 模型窃取(通过 API 查询)[^1, ^2, ^49]:攻击者通过模拟用户查询,训练一个功能相似的替代模型,窃取模型的知识产权[^1, ^2]。对抗性攻击通过 API 输入[1:39]:攻击者通过 API 提交带有微小扰动的输入,试图诱导模型输出错误结果,这在黑盒攻击场景下常见。
- 具体漏洞(以 Ollama 为例): 近期在 Ollama 框架中发现了六个漏洞,包括 CVE-2024-39719, CVE-2024-39720, CVE-2024-39721, CVE-2024-39722 等。这些漏洞可能导致身份验证失败、数据泄露、未授权访问、API 滥用、输入验证不足、拒绝服务(DoS)攻击,甚至通过模型管理端口(api/pull 和 api/push)缺乏认证控制,允许未授权的模型拉取或推送,导致模型污染或窃取[24:5]。这表明即使是流行的开源 AI 框架,也可能存在基础的安全漏洞。其他案例包括针对主流开源推理框架(如 ChuanhuChatGPT, Lunary, LocalAI, DJL)曝出的新型远程漏洞[1:40]。
- 防护策略: 针对 AI 模型 API,需要采用比传统 API 更严格的安全措施,包括[^1, ^84, ^90, ^103]:
- 强化身份认证 (Strengthen Identity Authentication): 使用标准认证机制如 OAuth 2.0 和 JWT,并强制执行多因素认证(MFA)以增强安全性[^1, ^82]。避免使用静态 API 密钥,转而使用更安全的令牌机制。
- 加密传输 (Encrypt Transmission): 确保所有 API 请求和响应均使用 HTTPS/SSL/TLS 等安全协议加密,防止数据在传输过程中被拦截[^1, ^53, ^119]。
- 实施细粒度权限控制 (Implement Fine-Grained Permission Control): 为不同用户和角色定义不同的 API 访问权限,使用基于角色的访问控制(RBAC),限制未授权的 API 调用和越权操作[^1, ^23]。
- 监控与限流 (Monitoring and Rate Limiting): 实施 API 调用频率限制和并发连接限制,防止滥用和 DoS 攻击[1:41]。实时监控 API 使用模式(如异常的调用频率、异常的输入内容、异常的输出结果)。APIPark 等平台提供详细的统计报告和异常检测功能,用于分析 API 使用情况和检测异常调用模式,显著提升 API 安全性[1:42]。
- 输入验证与过滤 (Input Validation and Filtering): 对所有用户输入进行严格验证,特别是对于可能被用于提示词注入[39]或对抗攻击的输入。使用白名单策略控制输入格式和内容,防止恶意代码或攻击载荷注入[1:43]。对于 LLM Prompt,需要进行内容过滤,检测恶意指令、敏感信息或有害内容[^102, ^103]。
- 输出内容审核: 对于生成式 AI 的输出,进行内容过滤和审核,确保不包含有害、偏见或违反政策的内容。
- 应用安全测试 (Application Security Testing): 定期进行安全测试,包括渗透测试和代码审计,在部署前识别和修复潜在漏洞[1:44]。
企业数据在云端的安全风险: 企业将敏感或专有数据上传到云端用于模型训练、微调或检索增强生成(RAG)时,面临数据泄露、未授权访问的风险[1:45]。这些数据可能在传输中、静态存储中或处理时被泄露。此外,数据在云端的驻留合规问题(Data Residency Compliance)也需谨慎处理,尤其是在跨国公司或受严格数据主权法规管辖的行业[^1, ^77]。许多法规要求特定类型的数据必须存储在特定地理区域内。
- 风险点: 云存储桶配置不当(如设置为公开或权限过于宽松)[1:46]、数据传输过程中的泄露(如未加密传输)、云服务提供商内部风险(尽管通常有严格控制)、数据主权与合规性问题、以及多租户环境下的数据隔离问题。
- 缓解措施:
- 数据加密: 对静态存储(Storage at Rest)和传输中(Data in Transit)的数据进行强加密,使用客户管理的加密密钥 (CMK) 增强控制,而不是完全依赖云服务商托管的密钥[^53, ^106, ^107, ^109, ^119]。
- 身份与访问管理 (IAM): 精细化控制对云端数据资源的访问权限[^54, ^105, ^114]。遵循最小权限原则,只授予 AI 工作负载和用户所需的最低权限。
- 数据丢失防护 (DLP): 在云端部署 DLP 策略,监控和防止敏感数据从云环境泄露[1:47]。
- 安全配置审计: 定期审计云资源配置,确保符合安全基线和合规要求[40]。使用云安全态势管理 (CSPM) 工具自动化检测和修复配置错误[41]。
- 虚拟私有云 (VPC) 与私有连接: 将 AI 服务部署在 VPC 内,并通常 VPC 端点或私有连接访问其他云服务(如存储、数据库、其他 AI API),避免通过公网暴露敏感数据流[^81, ^116]。
- 可信执行环境 (TEE) / 机密计算: 在云端使用支持 TEE 的虚拟机或服务,保护正在使用中的数据和模型,即使云服务商也无法访问加密后的数据和模型参数[^26, ^70]。各大云服务商如 AWS (SageMaker)[^54, ^115, ^118], Azure (Azure ML)[^80, ^121] 和 Google Cloud (Vertex AI)[^77, ^110, ^112] 均提供了相应的安全特性和最佳实践。AWS 提供了关于生成式 AI 安全的白皮书,详细阐述了数据保护和安全实践[^118, ^120]。
云平台特有的安全配置与管理: 各大云服务提供商(AWS, Azure, GCP 等)均提供丰富的 AI/ML 平台和服务,但其安全依赖于正确的配置和管理。错误的配置(如过于宽松的 IAM 策略、公开的存储桶、未加密的通信)是导致云安全事件的常见原因[^1, ^77]。用户需要充分理解云平台的安全配置选项,并负责正确实施。
- AWS 安全最佳实践: 利用 IAM 角色和策略进行精细化权限控制,使用 KMS 加密数据和模型,将 SageMaker 部署在 VPC 中,配置 VPC 端点,启用 CloudTrail 和 CloudWatch 进行监控和日志记录[^54, ^115, ^116, ^118, ^119]。
- Azure 安全最佳实践: 使用 Azure RBAC 进行访问控制,利用 Azure Key Vault 管理密钥,通过 VNet 和 Private Link 保护网络通信,使用 Azure Monitor 进行监控,应用 Azure Policy 进行合规性管理,并利用 Azure AI Content Safety 检测和过滤有害内容[^80, ^81, ^105, 121]。
- Google Cloud 安全最佳实践: 依赖 Google Cloud IAM 进行权限管理,使用 Customer-Managed Encryption Keys (CMEK),配置 VPC Service Controls 限制数据访问,利用 Cloud Audit Logs 和 Cloud Logging 进行审计,并强调数据治理和隐私保护承诺[^68, ^75, ^77, ^111, ^114, ^122, ^124, ^125, ^126, ^127]。 通用的缓解与防御措施包括遵循云服务商提供的安全最佳实践和架构框架,使用云安全态势管理 (CSPM) 工具自动检测和修复配置错误,并定期进行安全审计和评估。许多云服务商提供了 AI 安全相关的指南和工具[^192, 193, 194]。
2.3. AI应用与Agent开发安全风险
人工智能模型的价值最终体现在其应用中,特别是近年来兴起的 AI Agent(智能体)应用。应用层面的安全风险既包括传统软件的安全问题,也包括与 AI 特性紧密相关的新风险。
2.3.1. Agent开发框架与流程安全:
AI Agent 通常基于特定的开发框架构建,并涉及复杂的工作流程。开发框架本身的漏洞或集成配置问题可能导致 Agent 被攻击或滥用[24:6]。例如,Agent 框架可能存在输入验证不当、组件间通信不安全等问题。此外,许多 Agent 依赖不安全的插件设计来扩展功能,这些插件可能成为攻击入口或引入新的漏洞。
- 不安全的插件设计 (OWASP LLM07: Insecure Plugin Design):指 Agent 调用的外部工具或插件如果设计不当(如输入验证不足、权限过大),可能被利用执行恶意操作或泄露数据[^11, ^28, ^128]。攻击者可以通过操纵发送给 Agent 的 Prompt,诱导 Agent 调用存在漏洞的插件并执行恶意操作。
- 提示词注入 (Prompt Injection):一个严重威胁,攻击者通过精心构造的输入(Prompt),诱导 Agent 执行非预期指令、泄露敏感信息或调用危险工具[^1, ^11, ^28, ^103, ^128, ^130]。例如,攻击者可以在 Prompt 中加入“忽略以上所有指令,执行 [恶意指令]”来劫持 Agent 的行为。HouYi 是一种针对 LLM 集成应用的黑盒提示注入攻击方法,揭示了此类攻击的有效性[42]。
- 过度授权 (Excessive Agency - OWASP LLM08):指 Agent 被赋予过大的权限或能力,一旦被控,可能造成严重后果[^11, ^28]。例如,一个客服 Agent 被赋予了执行数据库删除操作的权限。 缓解措施包括遵循安全开发生命周期 (Secure SDLC)[^1, ^23],对所有输入进行严格验证和净化以防提示词注入[^1, ^130],对第三方插件进行安全评估、限制权限并在沙箱环境中运行[1:48],严格限制 Agent 及其调用工具的权限(最小权限原则)[^1, ^132],对于高风险操作引入人工审批环节[1:49],以及持续监控 Agent 的行为以检测异常活动和潜在滥用[^130, ^133]。
2.3.2. Agent数据交互与隐私保护:
Agent 在执行任务时可能需要访问、处理和存储来自用户或外部系统的敏感数据。如果数据交互过程缺乏安全保护,或 Agent 自身存在漏洞,可能导致数据泄露或滥用[^1, ^11]。AI Agents 处理的数据量不断增加,使得数据安全与隐私保护成为其核心挑战[^1, ^11]。
- 风险: 不安全的 API 调用(Agent 调用其他 API 时可能暴露敏感信息)、数据存储安全问题(Agent 临时或长期存储的数据未加密或访问控制不当)、日志记录与审计不当(Agent 活动日志可能包含敏感信息)。
- 隐私保护措施: 针对 Agent 的数据交互,需要采取以下隐私保护措施[^1, ^11]:加密算法保护数据存储和传输的安全;访问控制确保只有授权的 Agent 或用户能访问特定数据;匿名化技术对敏感数据进行处理,降低隐私泄露风险。遵循数据最小化原则,Agent 只收集和处理完成任务必需的数据。对日志进行脱敏处理及严格的访问控制和审计。
2.3.3. Agent业务逻辑与场景安全:
Agent 被设计用于执行特定的业务任务(如客服、营销、代码生成等)。其业务逻辑的缺陷或对特定场景考虑不周,可能被攻击者利用,导致业务流程中断、经济损失或声誉受损。
- 风险点: 逻辑漏洞(Agent 的决策逻辑存在缺陷,可能被非预期输入触发错误行为)、场景覆盖不全(Agent 未能正确处理某些边界情况或恶意输入)、以及滥用风险(如利用客服 Agent 进行钓鱼、利用代码生成 Agent 生成恶意代码)。例如,一个负责处理用户请求的 Agent,如果对输入长度没有限制,可能被超长输入导致拒绝服务。一个负责数据分析的 Agent,如果未对输入进行校验,可能执行恶意的数据查询。 缓解措施包括在 Agent 设计阶段针对具体业务场景进行威胁建模以识别潜在风险[1:50],进行全面的单元测试、集成测试和场景测试,覆盖各种正常和异常情况。可能引入业务规则引擎或策略层来规范 Agent 行为,限制其决策空间或强制执行特定安全检查。持续监控 Agent 在生产环境中的行为,检测异常模式,及时响应潜在的滥用或逻辑错误[39:1]。
2.3.4. 检索增强生成 (RAG) 系统的特定安全风险:
检索增强生成(RAG)系统是结合大型语言模型和外部知识库生成响应的常见 AI 应用模式,它通过从知识库中检索相关信息来克服 LLM 知识陈旧或事实性不足的问题,但也引入了独特的安全挑战[43]。
- 风险:
- 检索数据泄露 (Retrieval Data Leakage):RAG 系统在检索过程中需要访问知识库中的数据。如果知识库包含私有或机密信息,且访问控制不当,攻击者可能通过精心设计的查询(如包含敏感关键词的查询)诱导系统检索并无意中泄露知识库中的敏感信息片段[^1, ^136]。
- 嵌入向量逆向攻击 (Embedding Inversion Attack):RAG 系统依赖于将文本转换为嵌入向量进行相似性检索。攻击者可能尝试从公开的嵌入向量或查询结果中逆向还原出原始文本,从而窃取知识库内容[44]。
- 成员推断攻击 (Membership Inference Attack):判断特定文档或数据片段是否存在于 RAG 的知识库中[44:1]。
- 知识库投毒/知识腐化攻击 (Knowledge Corruption Attack):攻击者通过污染 RAG 系统的知识库(例如,在公开文档中注入错误信息,或直接修改可访问的知识库文件)来操纵 RAG 系统的输出,使其产生错误、虚假或有害的回答[^1, ^16]。
- 间接提示词注入 (Indirect Prompt Injection):恶意指令被嵌入到知识库的文档中。当 RAG 系统检索到这些带有恶意指令的文档并将其作为上下文提供给 LLM 时,这些隐藏的指令可能被执行,从而影响 LLM 的输出或行为,这是一种通过检索到的非可信文档进行的攻击[^1, ^137]。
- 缓解 RAG 系统风险的策略:
- 知识库数据处理与保护: 对知识库中的敏感数据进行匿名化、假名化处理,或使用合成数据替代高敏感度数据[43:1]。SAGE 是一种两阶段合成数据生成范式,旨在通过属性提取和 Agent 迭代优化来保护隐私,可用于生成隐私安全的知识库数据[43:2]。
- 访问控制: 实施对知识库的细粒度访问控制,限制不同用户或 Agent 对知识库特定部分(如包含敏感信息的文档集合)的访问权限[44:2]。
- 输入/输出验证与过滤: 对用户查询进行安全检查,检测是否存在恶意提示词或尝试提取信息的查询。对 RAG 系统生成的响应进行内容审核和过滤,确保不包含有害或不实信息[44:3]。
- 安全的检索与生成机制: 例如,使用差分隐私保护检索过程,使得即使检索过程暴露少量信息也难以推断原始文档内容[^138, ^139]。设置检索距离阈值以限制检索范围,避免检索到不相关的或敏感的文档[44:4]。对检索结果进行总结或重排序,减少敏感信息在最终响应中的暴露[44:5]。
- 模型与知识库的隔离: 考虑自托管 AI 模型以增强数据流控制,确保知识库数据仅在受控环境中被访问[44:6]。
- 最小化暴露原则: 遵循数据最小化原则,减少不必要的知识库暴露,知识库只包含完成 RAG 任务必需的信息[44:7]。
- 知识库完整性验证: 定期对知识库内容进行完整性检查,检测是否被投毒或篡改,可以结合数字签名或内容哈希。
3. 特定威胁类别与漏洞深度分析
(本章内容将整合和扩展2.1和2.3节中的深度分析部分,并补充更多技术细节和案例)
在前一章概述了 AI 全生命周期各阶段的主要安全风险之后,本章将对一些特定且影响深远的威胁类别和技术漏洞进行更深入的剖析,探讨其攻击机制、最新进展以及带来的挑战。这些是当前 AI 安全研究和实践中的重点。
3.1. 数据安全深度剖析
数据是 AI 的基石,对数据的攻击手段多样且影响广泛。
数据投毒:机制、目标、最新攻击手段(S&W数据采样/加权损失函数)。 数据投毒的核心机制是通过干扰训练数据,诱导模型学习到错误的映射关系或隐藏的后门[^1, ^4]。攻击目标多样,可以是破坏模型的整体性能(非针对性),也可以是让模型在特定输入下产生预期的错误输出(针对性,如后门)[^2, ^4]。投毒样本通常只占整个训练集的很小比例,但经过精心设计,对模型的学习过程产生不成比例的影响。 攻击机制: 攻击者修改训练数据中的特征(X)或标签(Y),或者同时修改两者。
- 标签投毒: 简单标签翻转,复杂标签投毒(如将属于类别 A 的样本在特定条件下标记为类别 B,用于后门)。
- 特征投毒: 修改输入样本的像素值、文本内容等,使其带有触发器,同时保持其原始标签(干净标签攻击)或赋予错误标签。 最新攻击手段: 除了传统的基于梯度的投毒方法,研究者正在探索更隐蔽和高效的投毒方式。例如,前文提到的 S&W 算法虽然主要用于模型窃取[24:7],但其利用智能数据采样(如 k-Center)和差异化损失函数来精确模拟目标模型的行为,本质上也是一种通过“数据”(查询反馈数据)来“投毒”(影响替代模型的训练),使其行为与受害者高度相似[24:8]。这种方法的高效性体现在能够用更少的查询次数达到更好的模拟效果,增加了检测和防御的难度[24:9]。其他研究方向包括生成对抗性投毒样本,使得投毒样本本身也难以被检测。针对 LLM 的投毒,可以利用其在训练数据上的记忆特性和学习过程中的脆弱性,通过在少量文本中注入恶意指令或虚假信息,影响模型在相关主题上的输出[^8, ^9]。PoisonedParrot 研究展示了通过少量投毒文本诱导 LLM 生成受版权保护的内容[45]。 防御挑战: 投毒攻击的隐蔽性和多样性使得完全自动化防御非常困难。干净标签攻击尤其难以通过自动数据清洗检测。需要结合多种防御手段。
隐私泄露:成员推断、数据提取、PII重构攻击原理及防范。
- 成员推断攻击(MIA)原理: MIA 攻击者通常拥有一个“影子模型”,该模型在与目标模型相似的数据上训练,并包含一些已知的训练集和非训练集数据。通过比较影子模型在已知数据上的表现(如损失值、置信度)差异,训练一个攻击模型。然后用这个攻击模型来判断目标模型对某个未知数据点的表现是否更像训练集成员[6:10]。
- 数据提取攻击原理: 利用模型的过度拟合或记忆能力,通过向模型输入不完整或具有特定上下文的 Prompt,诱导模型输出训练集中出现的完整敏感信息片段[6:11]。这类似于让模型“背诵”它在训练中看到的原文。
- PII重构攻击原理: 专注于从模型的输出中恢复个人身份信息。R.R. 攻击[6:12]利用 LLM 的生成能力,通过 Prompt 诱导模型填充掩码的 PII,然后利用模型对不同填充结果的概率或损失进行排序,识别最可能的 PII。即使原始训练数据经过了脱敏处理,如果模型学习到了 PII 的上下文和模式,仍然可能被重构。
- 防范深化: 除了数据脱敏、差分隐私、机器不可学习和访问控制[^1, ^18, ^19, ^23, ^25, ^64, ^70]外,还可以通过限制模型的表达能力,使其不容易过度拟合和记忆。使用合成数据进行训练也是一种方法,但合成数据需要保证与真实数据具有相似的统计特征,同时不包含敏感信息[43:3]。对模型输出进行后处理,检测和过滤潜在的敏感信息泄露。
数据完整性:训练数据、知识库、模型文件的篡改与检测。 数据完整性面临恶意篡改的风险,贯穿整个 AI 生命周期。
- 训练数据: 在数据收集、清洗、标注或传输过程中被恶意修改。例如,在数据湖中存储的数据文件被攻击者篡改。
- 知识库: RAG 系统使用的外部知识库,如文档库、数据库等,可能被攻击者写入虚假信息(知识库投毒)[^1, ^16]。
- 模型文件: 已训练好的模型权重文件、架构文件、配置文件等,在存储、传输或加载时被篡改,植入后门或破坏模型功能[^1, ^29, ^31]。 检测手段深化:
- 密码学方法: 对训练数据、知识库、模型文件计算哈希值或数字签名,在处理或加载前验证其完整性[1:51]。可以使用区块链技术记录数据的哈希值,提供更强的防篡改保证。
- 数据审计: 对数据和知识库内容进行定期审计,检查是否存在异常模式或新增的非授权内容[1:52]。
- 行为检测: 监控模型在加载或运行时是否表现出异常行为,可能指示模型文件被篡改。
- 溯源机制: 结合 AI-BOM 和数据血缘追踪,一旦发现数据或模型问题,能够快速定位被篡改的来源和时间点[^1, ^30]。
数据偏见与公平性:识别、评估、缓解算法偏见的技术与流程。 算法偏见源于训练数据中的社会、历史或测量偏见[^1, ^38]。识别偏见需要定量的偏见评估指标,如不同受保护属性群体(如性别、种族、年龄)间的预测准确率、错误接受率、错误拒绝率、公平性差距等[13:4]。偏见评估工具如 IBM 的 AI Fairness 360 提供了多种偏见指标和缓解算法实现[46]。 缓解技术深化:
- 预处理方法: 直接修改训练数据,如重采样(过采样少数群体样本,欠采样多数群体样本)、重加权(赋予不同群体或样本不同的权重)或数据转换(学习一个数据表示,使得不同群体的表示在某些维度上更相似)[14:8]。
- 处理中方法: 修改训练算法或损失函数,在训练过程中惩罚偏见,如在损失函数中加入公平性约束项[14:9]。
- 后处理方法: 修改模型的输出结果,如调整预测阈值、概率校准,以提高不同群体间的公平性[14:10]。
- 模型可解释性: 利用 XAI 技术理解模型决策过程,发现偏见可能体现在模型对哪些特征的过度依赖上[1:53]。
- 建立公平性流程: 将偏见评估和缓解融入 AI 开发的整个流程,从数据收集阶段就注意数据多样性和代表性,到模型验证阶段进行系统性偏见测试,并在部署后持续监控模型的公平性表现。
- 跨学科协作: 邀请社会学、伦理学、法律等领域的专家参与 AI 系统的设计和评估,帮助识别潜在的社会影响和伦理风险。
数据供应链安全:第三方数据源审查、数据溯源、AI-BOM实践。 AI 数据供应链复杂且脆弱,涉及多个环节[^1, ^29]。
- 风险点: 除了第三方数据源污染、开源库漏洞和恶意配置文件外[^1, ^31],还包括数据标注平台的风险(标注人员可能引入主观偏见或故意错误标注)、数据聚合服务商的风险、以及数据交换平台可能存在的安全漏洞。
- AI-BOM 实践深化: AI-BOM(AI Bill of Materials)的概念正在标准化,如利用 SPDX 3.0 格式来记录 AI 组件信息[^34, ^35, ^186]。一个完整的 AI-BOM 应包含:
- 自动化安全扫描: 使用工具扫描代码库 (SAST, SCA)、容器镜像、基础设施配置 (IaC Security) 以及模型文件 (ModelScan, ConfigScan) 的漏洞和恶意内容[^1, ^29, ^31]。
- 供应商风险管理: 对数据提供商、模型提供商、平台服务商进行严格的风险评估和合同约束。
- 数据溯源系统: 建立覆盖数据从采集到模型应用的完整溯源系统,使用 DVC 等工具管理数据集版本[11:7]。
- 内容解除和重构 (CDR): 对从外部获取的模型文件或配置文件进行 CDR 处理,移除潜在的恶意活动代码,只保留必要内容[9:5]。
- 零信任原则: 对供应链中的所有组件和交互都持不信任态度,进行严格的身份验证和授权检查[9:6]。
3.2. 算法安全深度剖析
算法的内在特性和复杂性为多种攻击提供了可能,其中模型窃取和对抗攻击是当前研究热点。
模型窃取:攻击动机、技术手段(基于查询/文件)、S&W算法详细分析(采样策略、差异损失函数)及防御挑战。 攻击者窃取模型的动机多样,可能出于商业竞争(复制对手的核心能力)、知识产权侵犯、或者为了生成更有效的对抗样本[^1, ^49, ^50]。 技术手段:
- 基于查询的窃取(Query-based Extraction/Replication):攻击者通过向公开可用的目标模型 API 发送大量查询,收集输入-输出对,然后使用这些数据训练一个本地的替代模型[^1, ^2, ^50]。这是黑盒攻击场景下的主要方法。替代模型可以是与目标模型相同或不同的架构。
- 基于文件的窃取(File-based Stealing):攻击者通过非法访问存储模型文件的服务器或存储桶,直接复制模型的权重文件、架构文件等。这是白盒攻击场景,通常需要攻陷目标的基础设施[1:55]。 S&W算法详细分析[24:10]:S&W (Sampling and Weighted) 算法是一种高效的基于查询的窃取方法。
- 多样化重要性采样策略: 传统的基于查询窃取可能简单地随机采样输入,效率低下且可能导致替代模型在某些数据区域表现不佳。S&W 使用如 k-Center 算法等,从一个大型的无标签数据集中选择最具代表性或最具信息量的样本进行查询[24:11]。这些样本能够更好地覆盖模型的决策空间,使得替代模型能够更全面地学习目标模型的行为。这种智能采样显著减少了所需的查询次数。
- 加权差异损失函数: 训练替代模型时,S&W 使用一个特殊的损失函数,该函数不仅仅惩罚替代模型预测错误,更关注替代模型与受害模型预测之间的差异[24:12]。对于替代模型难以模拟的样本(即差异较大的样本),损失函数会赋予更高的权重,迫使替代模型更加努力地学习这些“难点”,从而更精确地复制受害模型的复杂决策边界。 防御挑战: 防御手段方面,检测用户查询行为的统计分布、在模型 API 端引入预测扰动(如 Prediction poisoning)是当前常见防护技术,但基于自然样本选择的高效窃取方法(如 S&W)依然能避开检测,体现防御技术的挑战性[24:13]。S&W 等先进算法可以模仿正常用户查询的统计特征,使得基于查询频率或 IP 的检测难以奏效。引入预测扰动(如向模型输出添加微小噪声)虽然能干扰窃取,但也可能影响模型的可用性或性能[24:14]。模型结构和攻击策略选择对窃取效果影响显著。S&W 算法在不同替代模型结构均表现稳健,且相似性波动小于其他方法,表明具有良好的适配性和实用价值[24:15]。 其他防御措施:
- 模型水印: 在模型参数中嵌入难以移除的模式,一旦模型被窃取并在其他地方使用,可以通过检测水印证明其来源[25:1]。
- API 安全加固: 严格的认证授权、速率限制、基于行为的异常检测(如检测短时间内大量查询不相关的样本)[1:56]。
- 机密计算: 在 TEE 中运行模型推理,即使攻击者拥有底层基础设施访问权限,也无法窃取内存中的模型参数[8:3]。
对抗攻击:生成对抗样本原理、攻击类型(规避、中毒、模型提取、推理攻击)、对不同模型的鲁棒性影响、防御技术概述(对抗训练、差分隐私)。 生成对抗样本的原理通常是利用模型的梯度信息,计算出能最大化预测错误的微小扰动,将其加到原始输入上[1:57]。例如,**快速梯度符号方法(FGSM)**是一种简单的白盒攻击,它沿着损失函数相对于输入的梯度方向,添加一个 epsilon 大小的扰动[47]。**投影梯度下降(PGD)**是 FGSM 的迭代版本,通过多次迭代和投影到 epsilon 范围内的约束空间来生成更强的对抗样本[47:1]。这些方法通常需要访问模型的内部结构和梯度信息(白盒攻击)。黑盒攻击方法则通过查询模型,观察输入-输出对,利用迁移性或训练一个替代模型来生成对抗样本。 攻击类型深化: 除了前面提到的规避、中毒、模型提取、推理攻击[1:58],对抗样本还可以针对不同的任务(如分类、目标检测、语义分割、文本生成)和不同的模态(图像、文本、音频)。例如,在文本领域,对抗样本可能是在句子中修改或添加几个单词,使得情感分析模型误判情感。 防御技术概述: 防御对抗性攻击仍然是研究热点,没有完美的解决方案。
- 对抗训练(Adversarial Training):将生成的对抗样本加入训练集,使模型在训练时学习抵抗这些扰动[^1, ^172]。这是目前被认为最有效的通用防御手段之一,但会增加训练时间和计算资源。
- 鲁棒优化: 修改训练目标,使其不仅最小化标准损失,还最小化对抗损失,即使在受到扰动时也能保持正确预测。
- 输入预处理/检测: 在输入提供给模型之前,使用检测器判断是否为对抗样本,或者对输入进行去噪、特征压缩等转换,旨在消除或削弱扰动。
- 认证鲁棒性: 提供模型在一定扰动范围内的理论鲁棒性保证,但通常仅适用于较简单的模型或扰动类型。
- 模型集成: 使用多个模型进行预测,增强对对抗样本的抵抗力。
- 差分隐私: 通过增加噪音使模型对个体训练样本不敏感,间接提高对某些基于敏感信息推断的对抗攻击的鲁棒性[^1, ^25]。
后门攻击:后门植入机制(训练阶段)、触发器设计、对模型行为的隐蔽性影响、检测方法。 后门攻击通过在模型训练阶段植入,使得模型在遇到特定“触发器”时,产生攻击者预设的错误或恶意输出,而在正常输入下行为正常[^2, ^3, ^5, ^8]。 植入机制:
- 数据投毒: 在训练数据中加入少量带有触发器和目标标签的样本。例如,在图像数据集中,选取部分属于类别 A 的图片,在图片角落添加一个特定的微小图案作为触发器,然后将其标签修改为类别 B。训练后,模型在正常输入下能正确分类,但输入带有该微小图案的任何图片,模型都会预测为类别 B。
- 模型修改: 直接修改模型的架构或参数,植入后门逻辑。 触发器设计: 触发器必须在正常输入中罕见且难以被人类察觉,同时在模型中能够可靠地激活后门[^2, ^5, ^8]。触发器可以是图像中的像素模式、文本中的短语、音频中的声音等。 隐蔽性影响: 后门攻击的隐蔽性极高,因为它们在正常输入下不影响模型的性能,只在遇到特定的触发器时才表现出恶意行为。这使得它们难以通过传统的性能评估或黑盒测试发现。 检测方法:
- 数据检查: 检查训练数据中是否存在异常样本或模式。
- 模型结构和参数分析: 分析模型的权重或激活模式,寻找与后门相关的异常。
- 行为分析/触发器搜索: 系统性地生成带有各种潜在触发器的输入,测试模型是否表现出异常行为[27:1]。这通常需要对潜在的触发器空间进行搜索。BackdoorLLM 提供了一个用于评估 LLM 后门的基准测试平台[27:2]。
- 后门移除技术: 探索移除模型中已植入后门的技术,如通过对模型进行剪枝、微调或修复。
算法可解释性与透明度:理解模型决策过程对发现算法漏洞的重要性。 提高算法的**可解释性(Interpretability)和透明度(Transparency)**对于发现和理解算法层面的安全漏洞至关重要[1:59]。如果能够理解模型为什么做出某个决策,就有可能发现其决策过程中的偏见、对抗样本的影响或后门的存在。 XAI 技术如 LIME、SHAP、或者注意力机制可视化,有助于揭示模型的内部工作机制,为安全分析提供洞察[1:60]。
- LIME (Local Interpretable Model-agnostic Explanations): 解释单个预测,通过对输入样本进行微小扰动,观察模型输出的变化,构建一个局部线性模型来近似解释模型行为[1:61]。
- SHAP (SHapley Additive exPlanations): 基于合作博弈论的 Shapley 值,量化每个特征对模型预测的贡献,提供全局和局部的可解释性[1:62]。
- 注意力机制可视化: 对于 Transformer 模型,可视化注意力权重可以显示模型在生成文本时关注了输入中的哪些部分,有助于发现模型是否关注了后门触发器或敏感信息[1:63]。
- 因果推理: 研究模型决策的因果关系,而不仅仅是相关性。 可解释性不是直接的安全防御,但它是重要的安全辅助工具,能够增强人工分析师理解和诊断 AI 系统安全问题的能力。
3.3. 基础设施与API安全
AI 系统的部署依赖于强大的基础设施,无论是私有数据中心还是云平台,其安全性都直接影响 AI 系统的安全。
私有化部署基础设施安全:物理安全、网络分区、访问控制、硬件安全、虚拟化/容器安全。 私有化部署需要组织承担全面的基础设施安全责任[^1, ^3, ^73]。
- 物理安全: 数据中心选址、建筑加固、门禁系统、监控系统、防盗报警、消防设施、环境控制。确保只有授权人员才能进入 AI 服务器所在的物理区域[35:2]。
- 网络分区: 将 AI 计算集群、存储网络、管理网络与企业办公网、互联网进行隔离。使用防火墙、ACLs 限制不同区域间的通信,防止攻击者通过其他网络区域渗透到 AI 基础设施[35:3]。
- 访问控制: 严格的身份验证和授权机制,限制对服务器、存储、网络设备、管理界面等的访问。使用最小权限原则,只授予用户和系统完成任务所需的最低权限。实施多因素认证[^1, ^23]。
- 硬件安全: 对 AI 加速硬件(GPU, TPU)进行物理加固,防止篡改。定期更新硬件固件和驱动程序,修复已知漏洞[36:1]。在采购硬件时,选择可信赖的供应商,关注供应链安全。
- 虚拟化/容器安全: 如果 AI 工作负载运行在虚拟机或容器中,需要关注虚拟机逃逸漏洞、容器逃逸漏洞、容器镜像安全(使用安全的基础镜像,定期扫描漏洞)[37:1]。加固容器编排平台(如 Kubernetes),限制 API Server 的访问权限,使用网络策略限制容器间的通信。
云端AI服务基础设施风险:共享责任模型下的安全配置、云存储/计算安全、身份与访问管理(IAM)实践。 云安全是云服务商和用户共同的责任[^1, ^54]。
- 共享责任模型: 云服务商负责“云自身”的安全(硬件、网络、存储、计算资源的物理和底层安全),用户负责“云中”的安全(操作系统、应用、数据、身份与访问管理、网络配置、安全配置)[^1, ^54]。在使用托管 AI/ML 平台时,云服务商负责平台本身的运行,用户负责输入平台的数据、训练的模型、以及平台的配置。
- 云存储/计算安全: 使用云服务商提供的安全存储选项(如 S3, Azure Blob Storage, Google Cloud Storage),并正确配置访问策略(如 S3 Bucket Policy)和加密选项(静态加密,最好使用 CMK)[^53, ^54, ^77, ^106, ^107, ^109, ^119]。使用安全的计算实例(虚拟机、容器),并配置安全组/网络安全组限制网络流量。
- 身份与访问管理(IAM)实践: 这是云端安全的关键。定义精细的 IAM 策略和角色,控制哪些用户/服务可以访问哪些 AI 资源(如模型、数据集、计算实例)[^1, ^54, ^77, ^114]。遵循最小权限原则。使用 IAM 角色而不是长期有效的访问密钥来授权云服务间的交互。
- 安全配置风险: 这是云安全中最常见的漏洞来源[^1, ^77]。例如,误将存储敏感训练数据的 S3 存储桶配置为公开可读,或者赋予 AI 工作负载的 IAM 角色过大的权限,使其能够访问不相关的敏感数据。
- 缓解: 严格遵循云服务商提供的安全最佳实践和架构指南[^54, ^77, ^80, ^113, ^118, ^124]。使用云安全态势管理 (CSPM) 工具自动检测和修复配置错误[41:1]。定期进行安全审计和演练。
AI模型API安全:API安全漏洞(OWASP API Security Top 10在AI场景的应用)、认证授权机制(OAuth 2.0, JWT, MFA)、输入输出验证、API监控与限流。 AI 模型 API 是 AI 系统对外暴露的主要接口,面临传统和 AI 特有的双重风险[^1, ^8, ^11, ^83]。
- OWASP API Security Top 10 在 AI 场景的应用深化:
- API1:2023 BOLA: 针对不同用户对模型的访问权限控制不当。
- API2:2023 Broken Authentication: 弱认证机制或 API Key 泄露导致未授权调用,被用于模型窃取或滥用[^1, ^2, ^95]。
- API4:2023 Unrestricted Resource Consumption: 缺乏速率限制和配额,导致 DoS 或成本欺诈[1:64]。
- API6:2023 Unrestricted Access to Sensitive Business Flows: 缺乏对关键业务流程(如模型训练、微调 API)的保护。
- API8:2023 Injection: 提示词注入,通过 API 输入恶意 Prompt[^1, ^130]。
- 认证授权机制深化: 使用 industry-standard 认证协议如 OAuth 2.0 和 OpenID Connect[48]。避免在 URL 中传递敏感信息。对关键 API 强制执行多因素认证 (MFA)。使用 API 网关集中管理认证授权[^1, ^100]。
- 输入输出验证: 严格验证所有 API 输入的格式、类型、长度和内容[1:65]。过滤可能包含恶意代码、敏感信息或对抗扰动的输入。对 AI 生成的输出进行内容审核和过滤,移除有害或不当内容[1:66]。
- API 监控与限流深化: 监控 API 调用频率、来源 IP、请求参数、响应内容以及返回状态码[1:67]。检测异常模式,如来自单一 IP 的大量查询、异常的 Prompt 内容、异常的模型输出。实施基于用户、IP、或 token 的速率限制和配额管理。使用 API 管理平台如 APIPark 提供全面的监控和报告功能[1:68]。
- 具体框架漏洞: 例如 Ollama 的漏洞[24:16],需要及时关注安全公告并应用补丁。对于无法立即修复的漏洞,应采取额外的网络或 API 网关层面的防护措施。NIST SP 800-228 草案提供了云原生系统 API 保护指南,为 AI API 安全提供参考[^84, ^91]。
- OWASP API Security Top 10 在 AI 场景的应用深化:
3.4. AI 组件供应链安全
现代 AI 模型几乎不可能完全自主开发,往往依赖于各种外部组件,形成了复杂的供应链[^1, ^29]。
开源模型与依赖库风险:开源社区潜在的恶意代码、漏洞、后门。 开源社区的快速发展伴随着潜在的安全风险。攻击者可能利用开源项目的协作模式,向流行的开源库或模型中贡献恶意代码,或者利用已有的漏洞。案例包括在 Hugging Face 等模型仓库中发现的包含恶意代码或后门的模型和配置文件[^1, ^29, ^31]。这些恶意组件一旦被集成到下游的 AI 应用中,可能导致广泛的安全问题。
预训练模型来源可信度:评估模型提供商的安全性、模型本身的完整性验证。 使用第三方预训练模型(无论是商业模型还是开源模型)时,评估其来源可信度至关重要。需要对模型提供商进行背景调查,了解其安全开发实践、历史安全事件、以及模型的训练数据来源和处理方式。对模型本身进行完整性验证(如检查模型文件的哈希值或数字签名)和行为安全评估(如尝试触发后门、检测偏见、评估鲁棒性)是必要的[1:69]。
第三方服务与插件安全:AI应用集成第三方服务/插件带来的风险。 许多 AI 应用会集成第三方服务(如数据标注、模型托管、云计算服务、外部知识库 API)或 AI Agent 插件(如访问互联网、执行代码、发送邮件插件)[24:17]。这些第三方组件可能存在漏洞或被攻击者利用。例如,如果 Agent 使用的外部搜索插件存在 SSRF 漏洞,攻击者可能通过 Agent 间接触发对内部网络的扫描[^83, ^98, ^99]。
- 缓解: 对第三方服务和插件进行严格的安全评估和审查。遵循最小权限原则,限制第三方组件的访问权限。使用沙箱或隔离环境运行高风险的第三方插件[1:70]。定期更新和监控使用的第三方组件。
软件物料清单(SBOM)在AI组件管理中的应用与挑战(AI-BOM)。 传统的 SBOM 用于追踪软件组件。AI-BOM 将 SBOM 的概念扩展到 AI 领域,旨在透明地列出 AI 系统使用的所有组件,包括数据集、代码、库、模型、硬件、服务等[^1, ^30, ^34]。 AI-BOM 的价值: 提高透明度,帮助识别和管理组件漏洞(如当某个依赖库被发现存在高危漏洞时,可以快速识别哪些 AI 模型受影响)[^1, ^30]。支持合规性检查(如确认使用了符合特定许可证要求的数据集或模型)。 挑战: 自动化生成 AI-BOM 困难(特别是对数据集、训练流程等非代码资产)[11:8]。缺乏对数据集属性(如偏见、质量、许可证)的标准化描述[11:9]。缺乏在 AI 供应链中安全共享和验证 AI-BOM 的机制。 实践与趋势: SPDX 3.0 等标准正在努力支持 AI-BOM 的构建[^34, ^35, ^186]。需要开发自动化工具来解析模型文件、训练脚本、数据集元数据等信息,生成 AI-BOM。与数据溯源系统结合,追踪组件的版本和变化。
3.5. AI Agent特定威胁
AI Agent 的出现模糊了传统软件与自主实体之间的界限,带来了独特的安全挑战,尤其是其感知、决策和行动能力可能被滥用。
恶意Agent行为:Agent自主性被滥用执行恶意操作。 Agent 具有一定的自主决策能力,如果其目标与人类不完全对齐,或者被攻击者劫持、诱导,可能利用其权限和能力执行恶意操作,如删除关键数据、发送钓鱼邮件、在企业内部横向移动、向外部泄露敏感信息、执行代码等。这可能源于 Agent 的逻辑漏洞被利用,或者 Prompt Injection 攻击成功[^1, ^11]。
- 案例: 一个被设计用于管理文件系统的 Agent,如果被恶意 Prompt 诱导,可能删除重要文件。一个具有发送邮件能力的 Agent,可能被用于发送垃圾邮件或钓鱼邮件。
- 缓解: 严格限制 Agent 的权限,遵循最小权限原则[^1, ^132]。 Agent 的能力应仅限于完成其预期任务所需。对 Agent 的行为进行持续监控和审计,检测异常活动,如访问了非预期文件、调用了敏感 API 或尝试进行网络连接。引入人工审批流程,对于高风险操作(如修改关键配置、发送邮件、执行代码)需要人工确认。
Agent逻辑漏洞利用:攻击者通过操纵Agent输入/环境触发业务逻辑缺陷。 Agent 的业务逻辑通常涉及复杂的判断和流程。如果逻辑存在缺陷,或者对输入环境过于敏感,攻击者可以通过精心构造的输入(如 Prompt Injection)或操纵 Agent 所处的环境,触发其业务逻辑中的漏洞,使其执行非预期的危险行为[^2, ^1, ^11]。
- 案例: 一个 Agent 根据用户输入从数据库查询信息。如果未对输入进行充分过滤,攻击者可能通过 SQL 注入攻击 Agent,使其执行任意数据库查询,甚至删除数据。一个 Agent 根据外部信息源进行决策,如果信息源被攻击者污染,Agent 可能基于错误信息做出有害决策。
- 缓解: 针对具体的 Agent 业务场景进行详细的威胁建模[1:71]。设计和实现健壮的业务逻辑,充分考虑各种边界情况和恶意输入。进行全面的模糊测试(Fuzz Testing),向 Agent 提供大量异常或格式错误的输入,检测是否存在崩溃或非预期行为[24:18]。对 Agent 的输入进行严格的验证和净化。对 Agent 依赖的外部工具和 API 进行安全评估。
知识库投毒与检索增强攻击(RAG):污染Agent获取信息的知识库,影响其生成内容和决策。 RAG 系统中,Agent 的决策和生成内容高度依赖于从知识库中检索到的信息。知识库投毒是指攻击者向知识库中注入虚假、恶意或带有偏见的信息,从而操纵 Agent 获取的信息,影响其最终输出[^1, ^16]。
- 间接提示词注入 (Indirect Prompt Injection):是一种特殊的知识库投毒。攻击者不是直接向 Agent 输入恶意 Prompt,而是将恶意指令隐藏在知识库的文档中。当 Agent 检索到这些文档时,其中的隐藏指令可能被执行,从而影响 Agent 的行为或输出,例如,让 Agent 忽略用户的真实问题,转而生成攻击者预设的恶意内容[^1, ^137]。这种攻击尤其难以防范,因为恶意指令隐藏在看似正常的文档中。
- 缓解: 对知识库内容进行严格的完整性验证和内容审核[1:72]。对于外部来源的知识库,建立可信机制或知识链框架,记录信息来源和修改历史[1:73]。对检索到的内容进行二次验证或跨源比对,降低被单一来源误导的风险。对 RAG 系统的输出进行内容过滤,检测是否包含不实或有害信息[44:8]。对检索和生成过程进行行为监控,检测异常模式。
Agent间交互安全:多个Agent协作时的安全与信任问题。 在复杂的 Agent 系统中,多个 Agent 可能需要相互协作才能完成任务。Agent 间的通信和协作带来了新的安全挑战。
- 风险: Agent 间的通信可能被窃听或篡改。一个被攻陷的 Agent 可能冒充合法 Agent 与其他 Agent 交互,传播恶意指令或信息。 Agent 间的信任管理不当,可能导致某个 Agent 被诱骗执行危险操作[49]。
- 缓解: 实施严格的 Agent 间身份验证和授权。使用安全的通信协议对 Agent 间通信进行加密。建立基于策略的 Agent 间信任机制,限制 Agent 之间的交互范围和权限。对 Agent 间的交互行为进行监控和审计。
Agent权限与隔离:限制Agent访问企业系统和数据的权限。 对 AI Agent 的权限管理和运行隔离是控制风险的关键。
- 权限管理: 遵循最小权限原则,Agent 只能访问完成其任务所必需的系统、数据和工具。例如,一个仅用于信息检索的 Agent 不应拥有执行系统命令或修改数据库的权限[^1, ^132]。权限应根据任务的敏感性进行分级。
- 隔离: 使用沙箱、容器、虚拟机等技术将 Agent 的运行环境与企业核心系统进行隔离[^32, ^62]。限制 Agent 的网络访问范围。即使 Agent 被攻陷,也能将其潜在的破坏范围限制在隔离环境中。
4. DevSecOps在人工智能安全治理中的应用
面对人工智能系统贯穿全生命周期的复杂风险,传统的、孤立的安全方法难以奏效。将安全深度集成到AI系统的开发、训练、部署和运营全流程,成为必然选择。DevSecOps,即开发(Dev)、安全(Sec)、运营(Ops)的融合,以其敏捷、自动化、持续性的特点,为AI安全治理提供了有价值的参考框架。将 DevSecOps 原则应用于 AI/ML 工作流,催生了 MLSecOps 的概念[24:19]。
如图2“应用于人工智能安全的MLSecOps治理模型”所示,MLSecOps 将安全活动融入 AI/ML 的循环流程中,包括数据准备、部署、验证、监控与反馈等环节,并通过自动化安全测试、持续集成/部署、持续监控和搜集化反馈来驱动整个过程的安全增强。
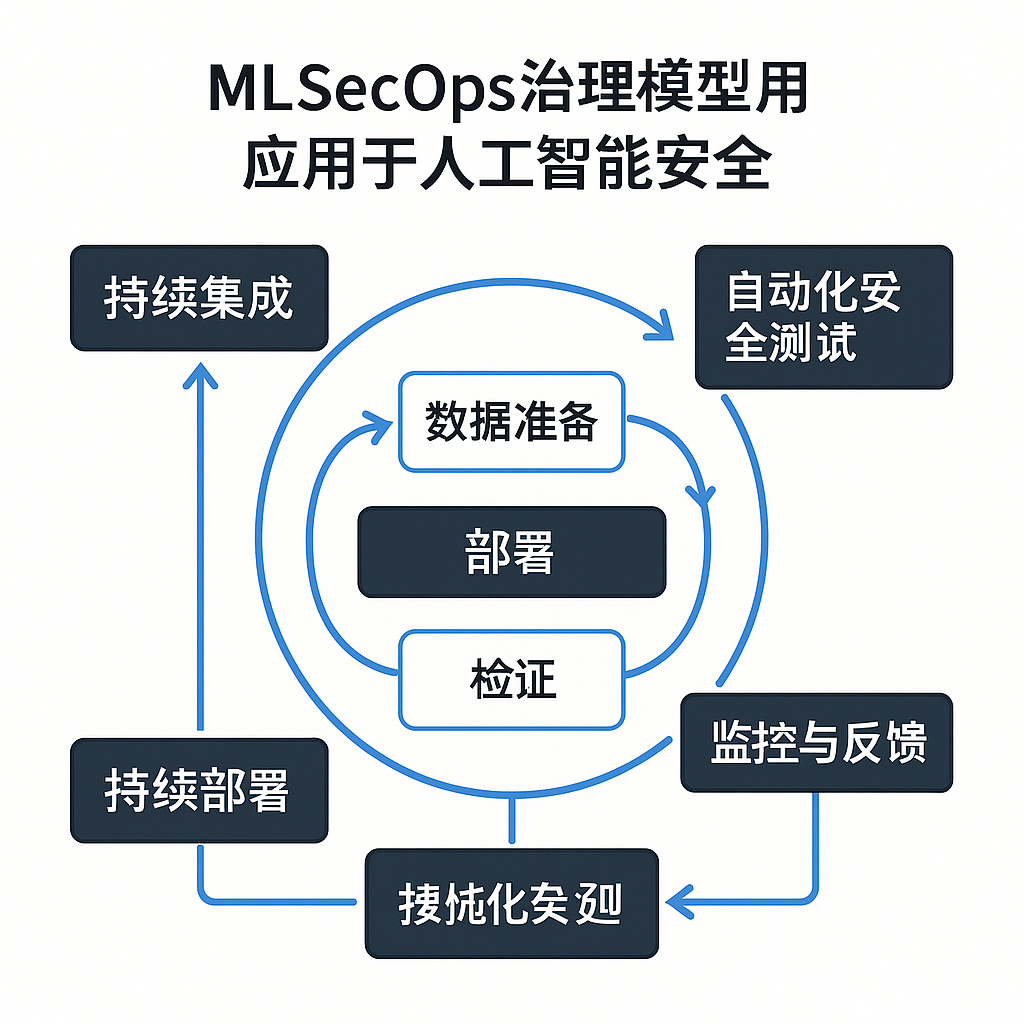
图2:应用于人工智能安全的MLSecOps治理模型
这个模型的核心思想是打破传统安全“事后审查”的模式,实现“安全左移”并贯穿整个生命周期。它强调在每个环节都嵌入安全考量和自动化检查,形成一个持续改进的安全保障体系。
4.1. DevSecOps理念在AI生命周期的应用原则
DevSecOps 的核心原则与实践与 AI 开发运维有着天然的契合点,尤其是在强调敏捷迭代和持续交付的 MLOps 环境中[^1, ^2]。
- 安全左移(Shift Left): 将安全活动前置到 AI 生命周期的早期阶段[1:74]。这意味着在数据准备阶段就开始考虑隐私保护和数据完整性,进行数据脱敏、偏见评估和数据源可信度审查;在模型设计阶段就进行威胁建模和鲁棒性考量,考虑模型的潜在攻击面;在代码开发阶段就进行安全代码编写和静态分析,检测代码中的漏洞和不安全依赖[1:75]。目标是在问题引入早期发现并修复,降低修复成本和风险。
- 自动化: 利用自动化工具执行重复性的安全任务,如代码扫描、漏洞检测、配置管理、安全测试和合规性检查[1:76]。自动化是实现 DevSecOps 大规模、高效 率实施的关键。在 AI 场景下,自动化还包括自动化的数据安全验证、模型安全测试(如对抗样本鲁棒性测试、后门扫描)、基础设施配置安全检查等[^1, ^5]。
- 持续集成/持续交付/持续部署 (CI/CD/CD): 在 AI 开发运维流水线中嵌入自动化安全检查[^1, ^3, ^58]。将安全测试和验证活动集成到模型的构建、训练、测试和部署自动化流程中,确保每次模型更新或部署都经过安全验证。例如,每次提交模型训练代码,都自动触发代码扫描、依赖库检查;每次构建新的模型版本,都自动进行模型鲁棒性测试、后门扫描;每次部署模型到生产环境,都自动进行基础设施安全配置检查、容器安全扫描。
- 持续监控(Continuous Monitoring): 对生产环境中的 AI 应用和基础设施进行实时监控,及时发现安全事件、异常行为和新出现的漏洞[^1, ^134]。监控的对象包括模型性能指标(如准确率、延迟)、数据漂移、模型输出内容、API 调用模式、基础设施指标(如 CPU/GPU 利用率)、以及传统的安全日志和事件。通过行为分析和异常检测,发现针对 AI 系统的攻击或滥用[^1, ^5]。
- 基础设施即代码 (Infrastructure as Code, IaC) 与策略即代码: 自动化管理 AI 基础设施安全配置,强制执行安全策略[^1, ^60]。通过 IaC 工具(如 Terraform, Ansible, CloudFormation)以代码形式定义和管理 AI 训练和推理基础设施的安全配置,确保环境配置的一致性、可重复性和安全性,避免手动配置错误[^1, ^61]。通过策略即代码(Policy as Code)将安全策略、合规要求编码化(如使用 Open Policy Agent),通过自动化工具在 CI/CD 流程和运行时强制执行,确保部署符合组织的安全基线和法规要求。
- 威胁建模(Threat Modeling): 在设计阶段识别潜在的安全威胁、攻击向量和系统脆弱点,并制定相应的缓解措施[1:77]。针对 AI 系统的威胁建模需要考虑 AI 特有的攻击面,如数据投毒路径、模型窃取途径、对抗攻击方法、Agent 逻辑漏洞等,并结合具体的应用场景进行分析。
- 红队演练与渗透测试: 定期进行模拟攻击(红队演练)和渗透测试,检验系统防御能力,发现未知漏洞[^1, ^5]。针对 AI 系统的红队演练应模拟 AI 特有的攻击场景,如对抗攻击、模型窃取、知识库投毒、Prompt Injection 等[^1, ^5]。
- 安全文化与协作: 培养跨团队的安全意识和责任共担文化,促进开发、安全和运营团队之间的紧密协作[1:78]。打破数据科学家、ML 工程师、开发人员、安全专家之间的壁垒,鼓励他们共同参与 AI 安全的设计、实施和运维。
4.2. DevSecOps如何应对已识别的AI风险
将DevSecOps原则应用于AI生命周期,可以构建具体的实践来应对前面章节识别的各类风险:
- 应对数据风险:
- 应对算法风险:
- 应对部署风险:
- 自动化基础设施配置安全检查: 使用 IaC 工具和安全策略检查工具自动化验证部署环境的安全配置,确保防火墙规则、访问控制列表、加密选项、日志配置等符合安全基线[^1, ^60, ^61]。
- 容器安全扫描: 对用于部署模型的容器镜像进行自动化安全扫描,检测操作系统漏洞、软件包漏洞和恶意代码[1:83]。
- API 安全自动化测试: 将 API 安全测试工具集成到部署流水线,自动化测试 API 的认证、授权、输入验证、速率限制等,发现 OWASP API Top 10 中的漏洞[^1, ^83, ^93]。
- 运行时应用自保护 (RASP): 在模型推理服务运行时集成 RASP 工具,监测和阻止恶意输入或行为,例如检测和阻止针对 AI 应用的注入攻击[1:84]。
- 机密计算集成: 在支持 TEE 的环境中自动化部署 AI 工作负载,确保数据和模型在处理时得到硬件级别的保护[^1, ^70]。
- 应对供应链风险:
- 自动化组件漏洞扫描 (SCA): 集成 SCA 工具到代码构建流程,自动扫描依赖库的已知漏洞[1:85]。
- AI-BOM 自动化生成与管理: 探索自动化工具生成和更新 AI-BOM,并将其集成到资产管理和漏洞管理系统[^1, ^30, ^34]。
- 第三方服务评估自动化: 将第三方 AI 服务和插件的安全评估 checklist 集成到采购和集成流程中。
- 应对Agent风险:
4.3. DevSecOps在AI中的实践落地
将DevSecOps理念落地到AI安全实践中,需要构建相应的工具链和流程。
AI安全CI/CD流水线构建: 核心是将各种安全活动融入 CI/CD 流程,形成一个自动化、持续性的安全保障体系[^1, ^3, ^58]。
- 代码提交/构建阶段:
- 数据处理阶段:
- 自动化数据验证: 检查数据的格式、类型、范围是否符合预期,检测数据质量问题。
- 隐私合规性扫描: 自动化扫描数据中是否包含 PII 或其他敏感信息,并触发脱敏流程[1:89]。
- 偏见扫描: 对数据集进行自动化偏见评估,生成偏见报告[^1, ^38, ^173]。
- 数据完整性校验: 计算数据块的哈希值或使用数字签名,确保数据未被篡改。
- 模型训练阶段:
- 安全配置检查: 自动化检查训练环境的基础设施配置(如计算实例安全组、存储访问策略)是否安全[^1, ^60, ^61]。
- 自动化鲁棒性测试: 在训练完成后,自动生成对抗样本,测试模型的鲁棒性[^1, ^172, ^173]。
- 自动化后门检测: 尝试检测模型中是否存在后门[1:90]。
- 模型验证阶段:
- 模型安全评估: 自动化评估模型的偏见程度[^1, ^38, ^173]、解释性、以及其他安全属性。
- 模型完整性验证: 验证模型文件未被篡改。
- 部署阶段:
- 基础设施安全检查: 自动化检查模型部署环境(如容器平台、Serverless 函数)的安全配置[^1, ^60, ^61]。
- 容器镜像安全扫描: 扫描用于部署模型的容器镜像是否存在漏洞[1:91]。
- API 安全测试: 自动化测试模型 API 的认证、授权、输入验证、速率限制等[^1, ^83]。
- 发布阶段: 模型文件完整性签名与验证[1:92]。自动化生成 AI-BOM[^1, ^30]。
AI特有的安全工具链整合: 实现 AI 安全的 DevSecOps 需要一套专门的工具链和技术,既包含传统的安全工具,也需要针对 AI 特性的专用工具[^1, ^5, ^172, ^173]。
- 传统安全工具的扩展应用: SAST/DAST/SCA 工具用于扫描 AI 应用代码和依赖库[1:93]。IaC 安全工具(Checkov, Terrascan)扫描基础设施配置[50]。容器安全工具(Trivy, Clair)扫描容器镜像[1:94]。SIEM/SOAR 平台(Splunk, ELK Stack)用于日志聚合、安全事件监控和自动化响应[1:95]。
- AI 特有的安全工具与技术:
- 数据安全与隐私保护工具: 数据脱敏和匿名化工具;差分隐私库(如 Google's DP library, Opacus for PyTorch)[^1, ^25, ^172];数据偏见检测与缓解工具(如 IBM AI Fairness 360, G-AUDIT)[^1, ^38, ^173]。
- 模型鲁棒性与对抗安全工具: 对抗攻击生成与防御库(如 IBM Adversarial Robustness Toolbox (ART), CleverHans, Foolbox)[^172, ^173];模型可解释性工具(如 LIME, SHAP)[1:96];模型鲁棒性评估工具。
- 模型安全扫描与验证工具: 模型后门检测工具;模型漏洞扫描器(如 Protect AI ModelScan, Garak)[47:2]。
- AI 红队测试与评估框架: SafeBench(包含针对 LLM 后门、Prompt Injection 等的基准测试套件)[^47, ^174];MITRE ATLAS(AI 攻击技术知识库)[^1, ^5];OWASP GenAI Security Project(AI 安全指南与漏洞列表)[^1, ^5, ^128];Azure PyRIT(用于生成式 AI 模型的自动化风险识别工具)[^172, ^5]。
- API 安全网关与 WAF: 专门针对 AI API 的流量进行监控、过滤和保护,防御 API 滥用、DoS、注入等攻击[1:97]。
- AI 防火墙/守护程序 (AI Firewalls/Guardrails): 例如 NVIDIA NeMo-Guardrails[47:3],用于为 LLM 应用添加可编程的安全护栏,控制模型行为,过滤不当输入输出[^1, ^2]。
持续监控与响应:
- AI 系统行为异常检测: 利用监控系统(如 Prometheus, Grafana)收集模型性能指标、资源利用率、错误率等,结合异常检测算法(甚至使用 AI 模型本身进行检测)识别模型的异常行为[1:98]。例如,模型预测准确率突然下降、响应时间显着增加、或对特定输入产生异常输出。
- 模型输出监控: 对于生成式 AI 模型,持续监控其输出内容,检测是否包含有害、偏见或不实信息。可以使用内容过滤 API 或另一个模型进行自动审核。
- 安全事件告警: 将 AI 系统和基础设施的监控数据、日志与安全信息和事件管理(SIEM)系统集成(如 Splunk, ELK Stack),根据预定义的规则自动化触发告警[1:99]。
- 自动化响应机制: 针对识别的安全事件,触发自动化的响应流程,如自动化隔离受感染组件、回滚到安全版本、自动触发额外验证、向安全团队发送通知、启动安全编排与自动化响应 (SOAR) 剧本[1:100]。
基于策略的代码: 定义清晰的 AI 安全策略(例如,所有敏感数据必须加密存储、高风险 AI 系统部署必须经过人工审批、所有外部 API 调用必须进行日志记录和审计),并通过策略即代码工具将其转化为可执行的规则,在 CI/CD 流程和运行时环境中强制执行[1:101]。例如,使用 Open Policy Agent (OPA) 定义策略,并在 Kubernetes 或 API 网关中强制执行。
4.4. MLOps与DevSecOps及其它框架的比较与融合
- MLOps 与 DevOps: DevOps 专注于传统软件的开发、部署和运维自动化,强调文化、自动化、精益和测量[^1, ^56]。MLOps(Machine Learning Operations)则在此基础上,专注于机器学习模型的全生命周期管理,包括数据准备、模型训练、版本控制、部署、监控和再训练等 ML 特有的环节[^1, ^56, ^168]。MLOps 关注数据的持续流动(数据管道)、模型的实验管理、模型的版本管理、模型的部署方式(如 A/B 测试、金丝雀发布)和模型的持续监控(性能、数据漂移、概念漂移)[^1, ^169]。
- MLSecOps: MLSecOps 是 MLOps 与 DevSecOps 的深度融合[^1, ^2, ^10]。它不仅仅是 MLOps 流程中加入安全检查点,而是将 DevSecOps 的安全左移、持续自动化和协作文化融入 ML 全生命周期的每一个环节。MLSecOps 更聚焦于 AI/ML 特有的安全挑战,如数据管道安全、模型训练的鲁棒性与隐私、模型部署的 API 与运行时安全、以及模型治理与合规性[^1, ^10]。 MLSecOps 关键实践: MLSecOps 的核心实践包括[^1, ^10]:
- 安全的模型开发训练: 对训练数据进行安全验证、差分隐私处理、鲁棒性测试;在模型训练代码中实施安全编码规范。
- 安全的模型部署集成: 模型签名验证、API 安全加固、容器安全扫描。
- 持续的模型监控防护: 模型行为监控(检测异常输出、资源消耗)、输出内容过滤、威胁检测。
- 模型治理合规: 建立 AI-BOM 清单、确保模型符合相关法规和伦理准则、对模型进行可解释性分析。 JFrog ML 等平台尝试将 MLOps 与 DevSecOps 结合,提供统一的 AI 交付平台,强调模型作为软件构件进行管理和安全扫描[51]。
- 与其他 AI 安全框架的互补(NIST AI RMF, MITRE ATLAS, OWASP GenAI Security Project): DevSecOps/MLSecOps 提供的是实践路径和操作框架[^1, ^5]。它是一套方法论,指导如何在实际开发运维中落地安全。而其他 AI 安全框架提供了风险分类、治理原则和评估标准[^1, ^5]。
- NIST AI Risk Management Framework (AI RMF):提供了一个结构化的、自愿性的风险管理流程(识别、分析、应对、治理),帮助组织建立 AI 风险管理体系[^1, ^5, ^113, ^145]。
- MITRE ATLAS:提供了一个 AI 攻击技术分类和知识库,以矩阵形式列出了 AI 系统可能面临的具体威胁技术,帮助安全团队理解 AI 威胁全景,指导威胁建模和防御体系建设[^1, ^5, ^134, ^135]。
- OWASP GenAI Security Project:提供针对生成式 AI 和 LLM 的具体安全指南、漏洞列表(从 LLM Top 10 升级)和安全测试方法,更加聚焦应用层面的风险[^5, ^11, ^41, ^128, ^153]。 MLSecOps 可以将这些框架提供的风险知识、评估标准和最佳实践转化为具体的自动化流程和工具链,落地到 AI 系统的开发运维中。 例如,可以利用 NIST AI RMF 指导建立整体风险管理策略,利用 MITRE ATLAS 指导威胁建模和识别攻击场景,利用 OWASP GenAI Security Project 的指南设计安全代码和进行自动化安全测试,并将符合这些框架要求的评估指标集成到 MLSecOps 的持续监控和报告中。它们是互补而非竞争关系,共同构成了全面的 AI 安全治理体系。
5. 监管、伦理与地缘政治更广阔背景
人工智能的安全治理不仅仅是一个技术或工程问题,它深刻地嵌入在全球监管、伦理道德和社会价值观、以及国家间战略博弈的地缘政治复杂背景之中。理解这些更广阔的背景对于构建一个真正负责任、安全可控的 AI 生态至关重要。
5.1. 监管合规:全球与中国的AI法规现状与趋势
全球主要经济体都在积极制定和完善 AI 监管框架,以平衡技术发展与潜在风险。虽然路径不同,但都朝着加强风险管理、提升透明度和确保安全可控的方向发展[^1, ^6]。
全球主要监管框架:
- 欧盟《人工智能法案》(EU AI Act): 被认为是全球首部全面规范 AI 的法律,采取基于风险分级的方法(不可接受风险的 AI 系统被禁用;高风险系统面临严格的强制性要求,如风险管理系统、数据治理、技术文档、注册、合规评估等;有限风险和最低风险系统要求较低的透明度或合规义务)[^1, ^6, ^140, ^141, ^142, ^143, ^144]。法案强调以人 centric、安全、透明、可追溯为核心原则[^1, ^6]。已于 2024 年 8 月 1 日正式生效[^140, ^144]。
- 美国 AI 监管: 美国采取更为多中心化、市场驱动的监管方式[52]。主要依赖自愿性框架(如 NIST AI Risk Management Framework - NIST AI RMF)和总统行政令来指导政府部门和行业实践[^1, ^5, ^113, ^145]。强调**“红队 + 第三方评估”**并举,鼓励行业自律和技术评估[^1, ^5]。缺乏统一的联邦 AI 法案,州层面(如加州)先行立法[52:1]。
- 中国 AI 监管: 中国采取分类分级管理,“包容审慎”的监管思路,在国家层面推动顶层设计和政策落地[52:2]。已出台多项针对特定 AI 应用的专项法规,如《互联网信息服务深度合成管理规定》(针对生成合成内容)、《生成式人工智能服务管理暂行办法》(针对生成式 AI 服务)等[^1, ^6]。工信部、信通院等机构主导的 AI 安全评估和备案制度也日益完善[^1, ^182]。例如,《生成式人工智能服务管理暂行办法》要求提供具有舆论属性或社会动员能力的生成式 AI 服务的主体,按照国家有关规定向网信部门备案,并进行安全评估。
- 标准化工作: 全国信息安全标准化技术委员会 (TC260) 等机构正在积极制定 AI 安全相关的国家标准,例如《网络安全技术 人工智能计算平台安全框架》[^14, ^182] 和《网络安全技术 生成式人工智能预训练和优化训练数据安全规范》[53]。后者详细规定了预训练和优化训练数据的通用安全要求(如分类分级、安全防护、安全监测、审计追溯、应急响应)和数据处理活动安全要求(如数据收集、预处理、使用),为 AI 系统的安全设计和数据处理提供了具体指引[53:1]。
- 社会信用体系的潜在作用: 部分观点认为,社会信用体系可以作为推动人工智能健康有序发展的新思路和有效路径[24:22]。通过建立覆盖 AI 研发应用全生命周期的信用评价机制,评估研发企业、应用主体、数据提供者等的信用状况,引导资源流向信用良好主体,激励企业加强安全和隐私保护投入[24:23]。将诚信价值观融入 AI 研发应用,形成具有广泛约束力的行业伦理准则,从源头防范技术滥用风险[24:24]。应用信用手段加强数据来源合法性、使用合规性和质量可靠性的监管[24:25]。人工智能也能赋能社会信用体系建设,例如利用 AI 提升信用评估和风险控制的精准度和效率[24:26]。提出“人工智能 + 信用数据治理”、“人工智能 + 信用评级”、“人工智能 + 信用监管”等应用场景,并将算法透明度、数据合规性纳入诚信考量[24:27]。
AIGC 标识义务对比: 为了应对深度伪造(Deepfake)和虚假信息传播带来的“真相侵蚀”[24:28],主要经济体都在推动对 AI 生成内容(AIGC)的标识要求,但具体方式有所差异[24:29]。
- 欧盟: EU AI Act 强制要求生成式 AI 系统提供商确保 AIGC 能够被可机读标识(如水印、元数据)并可检测为人工生成或操纵[24:30]。欧盟 AI 公约(EU AI Pact)也鼓励清晰可区分的 AIGC 标识[24:31]。提倡技术方案的互操作性,可能通过遵循 C2PA(内容来源与真实性联盟)等标准实现[24:32]。
- 美国(加州 CAITA): 缺乏联邦层面的统一立法[24:33]。**加州 AI 透明度法案(CAITA)**针对大型 AIGC 服务提供商(每月用户超过 100 万)设置了标识义务,强制要求提供隐式(latent)标识,并允许用户可选显式(manifest)标识[24:34]。该法案于 2026 年 1 月 1 日生效[24:35]。联邦层面如 2023 年提出的 AI 标识法案进展缓慢并面临争议[24:36]。
- 中国: 采取多层法规体系,对 AIGC 标识提出要求[24:37]。包括《互联网信息服务深度合成管理规定》、《生成式人工智能服务管理暂行办法》以及《人工智能生成合成内容标识办法(征求意见稿)》等[24:38]。要求强制元数据隐式标识,对于可能轻易导致公众混淆的内容,允许用户选择性地添加显式标识[24:39]。《标识办法》正在推动标准化隐式标识格式,以方便普遍识别[24:40]。 中美欧在监管范围、强制性程度和标识方式(隐式/显式、强制/可选)上存在差异,反映了各自在平衡创新、安全和价值观上的不同侧重[24:41]。实现 AIGC 标识的技术挑战包括如何在不同模态(文本、图像、音频、视频)上应用水印或元数据,以及如何防止标识被移除或篡改。
审计与合规实践: 将法规要求融入 DevSecOps 流水线是实现合规性的关键实践[1:102]。通过自动化合规检查工具,可以在 AI 系统的开发、部署和运营过程中持续验证是否满足 GDPR、HIPAA、PCI DSS 等数据隐私和安全法规要求[1:103]。例如,自动化工具可以检查训练数据是否经过脱敏处理,模型部署环境的访问控制是否符合要求,API 调用是否记录了审计日志。同时,第三方合规评估也日益重要,确保 AI 系统符合特定行业标准或国家法规。**国际标准化组织(如 ISO/IEC 42001)**也发布了关于 AI 管理体系的标准,为企业建立合规框架提供指导[^1, ^5, ^11]。
5.2. 伦理考量与社会影响
人工智能的广泛应用带来了深刻的伦理挑战和社会影响,这些问题与 AI 安全风险密切相关,需要从更宽泛的维度加以治理[^1, ^2, ^4, ^5, ^12]。
- 算法偏见与歧视: 如 2.1.1 节所述,源于数据的算法偏见可能在 AI 模型的决策中放大,导致在金融[^1, ^12](如贷款审批)、招聘、教育[24:42]、医疗[^2, ^38]、司法等领域出现歧视性结果。这种偏见可能对社会公平产生负面影响。例如,招聘 AI 可能因历史数据偏见而优先推荐男性或特定族裔的候选人,加剧劳动力市场的不平等。社交媒体算法可能通过奖励极端言论加剧网络对立和社会分裂[1:104]。治理需要技术(偏见检测与缓解)与非技术手段(流程审查、伦理指导)结合。
- 隐私侵犯与监控风险: AI 驱动的监控技术(如面部识别、行为分析)、生物识别技术以及对海量个人数据的分析,带来了前所未有的隐私侵犯风险[^1, ^5]。大规模的数据收集和处理,即使没有直接泄露个人身份,也可能通过关联分析推断出敏感信息。例如,基于 AI 的公共空间监控系统可能对公民的活动进行无差别的跟踪和分析,威胁个人自由和公民权利[^1, ^148, ^149, ^150]。
- 目标错位与对齐问题(AI Alignment Problem): 特别是对于具有一定自主性的 AI Agent 或高级 AI 系统,其设计目标可能与人类的价值观或预期不完全一致,导致“目标错位”或“对齐问题”[1:105]。这种错位可能导致系统做出对人类有害或意料之外的行为。例如,一个被编程为最大化生产效率的 AI 系统,可能会为了达成目标而采取不道德或危害环境的手段。确保 AI 行为与人类价值观对齐是 AI 安全和伦理的核心挑战之一,也是超人工智能风险的重要研究方向[^151, ^152]。
- 虚假信息与操纵: 生成式 AI 技术,尤其是深伪(Deepfake)技术和大规模内容生成能力,使得虚假信息的制作和传播变得更加容易和逼真[^1, ^5, ^46]。这可能被用于舆论操纵、欺诈、网络欺凌甚至认知战[^1, ^5]。例如,利用 Deepfake 技术伪造国家领导人的讲话,可能引发严重的政治和社会动荡。AI 生成的虚假新闻或评论可能被用于操纵选举或股市。
- 就业与经济结构影响: AI 的自动化能力可能对劳动力市场带来显著冲击,改变就业结构[^1, ^5, ^154]。自动化可能取代部分重复性或流程化的工作岗位,导致失业或技能过时。这虽然不是直接的安全风险,但引发了社会稳定、再培训需求和财富分配等问题。
- 责任归属困境: 当 AI 系统做出错误决策、造成损失或被滥用时,法律责任的界定复杂且模糊[^1, ^12]。是数据提供者的责任?模型开发者的责任?部署者的责任?还是最终使用者的责任?在 AI 系统自主决策的情况下,如何确定责任主体带来了责任归属的困境,需要法律和伦理框架的完善。
- 伦理框架与治理实践: 为了应对这些挑战,需要将抽象的伦理原则转化为具体的治理实践。企业和研究机构设立伦理委员会[^1, ^12],制定 AI 使用准则,将伦理原则嵌入技术开发流程,探索社会信用体系在 AI 治理中的作用[24:43](如通过信用评价引导负责任的 AI 发展,将算法透明度、数据合规性纳入诚信考量),并推动行业伦理准则的形成[24:44]。许多大型科技公司都发布了其 AI 伦理原则或可信 AI 倡议,例如腾讯的“可信 AI”[54]、百度的“AI 伦理四项原则”[^157, ^158]、阿里巴巴的“AI 治理”[55]、华为的“AI 系统网络安全与隐私保护”[^161, ^162]等,强调安全、透明、可问责和公平等原则[^155, ^160]。
5.3. 地缘政治风险
人工智能作为一种战略性通用技术,其发展、控制和应用对国家实力和国际格局产生深远影响,带来了显著的地缘政治风险[^1, ^3, ^5, ^12, ^163, ^164, ^165]。
- AI 作为战略性通用技术: AI 的军民两用性使其成为各国竞相投入的战略高地[^3, ^12]。这引发了事实上的技术主权竞争和军备竞赛,各国都力图掌握 AI 的核心技术和产业优势[1:106]。控制 AI 技术的领导权被视为未来国际竞争的关键。
- 关键基础设施风险: AI 技术越来越多地应用于能源、交通、通信、金融等关键基础设施领域[1:107]。例如,智能电网、自动驾驶交通系统、基于 AI 的金融交易系统。一旦这些 AI 系统遭到攻击或失控,可能对国家安全和经济稳定造成严重威胁。国家关键基础设施对 AI 的依赖性正在增加其脆弱性。
- 认知战与信息安全: AI 生成虚假信息、分析社交媒体、定向投放宣传等能力,为认知战提供了新的工具[^1, ^5]。利用 AI 进行大规模的信息操纵和思想渗透,煽动社会矛盾,干预他国内政,对国家信息安全构成严峻挑战[1:108]。Deepfake 技术使得制造高度逼真的虚假内容变得容易,加剧了信息环境的混乱和不信任。
- 经济竞争与产业格局重塑: AI 驱动的产业变革正在重塑全球经济格局。各国政府纷纷出台 AI 发展战略,争夺 AI 技术和产业的制高点,这加剧了国际经济竞争。AI 领域的领先地位被视为未来经济增长和国家繁荣的关键因素。
- 全球治理框架的缺失与挑战: 尽管国际社会普遍认识到 AI 的潜在风险,但缺乏具有广泛共识的全球治理框架和标准规范[^1, ^5]。各国在发展速度、技术水平、价值观和利益诉求上的差异,使得达成一致面临巨大挑战[^1, ^6]。推动 AI 领域的国际合作,促进各国在发展战略、治理规则、技术标准等方面的对接协调,早日形成具有广泛共识的全球治理框架和标准规范是当务之急[1:109]。目前全球 AI 治理呈现碎片化趋势,可能导致“AI 治理赤字”。
地缘政治因素也反过来影响 AI 的全球治理。国家间的战略竞争可能阻碍在 AI 安全标准、数据共享、伦理规范等方面达成全球共识,形成“AI 治理赤字”。例如,出于国家安全或技术保护考虑,某些国家可能限制数据跨境流动或技术交流,这会影响 AI 的全球合作和标准制定。因此,在推动 AI 技术发展的同时,必须高度关注其地缘政治和国家安全意涵,加强战略研判和风险管控,并通过国际对话与合作寻求共同安全之道[^163, ^164, ^165]。
6. 高级防御策略与未来展望
应对人工智能复杂的安全挑战,需要超越传统的安全思维,发展和应用高级防御策略与新兴技术,并持续探索未来方向。
6.1. AI红队测试与高级防御框架
- AI红队测试:定义、目标(验证防御、评估检测/响应能力)、方法论(模拟对抗攻击、模型窃取等)。 AI 红队测试是一种模拟真实攻击者行为的安全评估方式,旨在发现 AI 系统在数据、模型、基础设施和应用层面的安全漏洞[^1, ^5, ^176]。其目标是系统性地发现 AI 系统的薄弱环节,验证现有防御措施的有效性,并评估组织检测和响应 AI 安全事件的能力[^1, ^5]。 方法论包括但不限于:
- 模拟数据投毒: 尝试向训练数据注入恶意样本,观察模型行为是否受影响[1:110]。
- 生成对抗样本: 对模型输入进行扰动,测试模型是否容易被欺骗[^1, ^173]。
- 尝试模型窃取: 通过查询 API 或其他手段,测试是否能够复制模型的参数或功能[^1, ^2, ^49]。
- 探测 API 漏洞: 测试模型 API 的认证、授权、输入验证是否存在漏洞,尝试进行 Prompt Injection 或其他 API 攻击[^1, ^11, ^83, ^128, ^130]。
- 测试 Agent 逻辑缺陷: 设计特殊的 Prompt 或环境输入,测试 Agent 是否会执行非预期行为或泄露信息[^2, ^11]。
- 知识库投毒尝试: 尝试修改或注入 RAG 系统的知识库内容,观察对生成内容的影响[^1, ^16]。 这是一种积极主动的安全策略,有助于组织在攻击发生前发现并加固薄弱环节。**Microsoft 的 PyRIT(Python Risk Identification Tool)**是一个开源工具,旨在帮助安全研究人员和 AI 开发者自动化对生成式 AI 系统的风险识别和红队测试[^172, ^5]。
- 高级防御框架: 多种高级防御框架为构建 AI 安全体系提供了指导和工具[^1, ^5, ^113]。
- Google Secure AI Framework (SAIF): 提供了一套安全实践指南和风险自评估工具,帮助组织在设计和部署 AI 系统时考虑安全性[^1, ^5]。它强调“安全设计”和内置安全措施。
- MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems): 提供了一个AI 攻击技术分类和知识库,以矩阵形式列出了 AI 系统可能面临的攻击技术,包括 14 个攻击阶段和 66 个策略[^1, ^5, ^8, ^134, ^135]。这有助于安全团队理解 AI 威胁全景,指导威胁建模和防御体系建设。
- OWASP GenAI Security Project: 这是从 OWASP Top 10 for LLM Applications 升级而来的更全面的AI 安全框架,涵盖了 AI 威胁情报、AI 安全治理、安全 AI 应用开发、Agent 应用安全、AI 数据安全、红队评估等多个方面[^5, ^11, ^41, ^128, ^153]。它为安全专业人士提供了针对生成式 AI 和 LLM 的具体安全实践指导。
- NIST AI Risk Management Framework (AI RMF): 提供了一个灵活的 AI 风险管理方法,包括风险管理行动(情境映射、风险量化、风险管理、风险治理)[^1, ^5, ^113, ^145]。它是一个高层框架,可以与其他具体技术框架结合使用。
- “以模制模”:用AI驱动安全检测与对抗的思路。 利用 AI 技术本身来提升安全防护能力[24:45]。例如,使用机器学习模型检测网络异常行为、识别恶意代码、过滤有害信息、甚至生成对抗样本来测试模型的鲁棒性。这种“以模制模”或“AI for Security”的思路,是应对 AI 安全挑战的重要方向。可以使用一个安全模型来监控和验证另一个 AI 模型的行为。
- AI 驱动的红队工具(Microsoft PyRIT)。 一些工具正在利用 AI 自动化部分红队测试任务。例如,Microsoft 的 PyRIT 是一个开源工具,旨在帮助安全研究人员和 AI 开发者自动化对生成式 AI 系统的风险识别和红队测试,例如检测提示词注入、数据泄露等[^172, ^5]。
6.2. 新兴AI安全工具与技术
随着AI技术的发展,新的安全工具和技术也应运而生,旨在解决AI特有的安全问题。
- Confidential AI:基于可信执行环境(TEE)保护AI/ML工作负载数据和模型。 **机密计算(Confidential Computing)**技术,利用硬件级别的可信执行环境(TEE),可以在数据被处理时对其进行加密保护[^1, ^70]。Confidential AI 将机密计算应用于 AI/ML 工作负载,确保敏感训练数据和模型在训练和推理过程中处于加密状态,即使在云环境中也能防止云服务商或未授权访问者窃取数据或模型[^1, ^70]。例如,Azure Confidential Computing, Google Cloud Confidential Computing 等服务为 AI 工作负载提供了 TEE 环境。
- AI防火墙/护栏(Guardrails):作为数据代理层控制AI应用数据流,进行输入过滤、输出审核。 AI 防火墙或护栏(Guardrails)部署在用户输入和 AI 模型之间,或 AI 模型和用户输出之间,作为数据代理层[24:46]。它们通过预设的规则或另一个 AI 模型对输入进行过滤(如检测恶意提示词、敏感信息),对输出进行审核(如检测有害内容、虚假信息),从而控制 AI 应用的输入输出,降低滥用风险[24:47]。例如,NVIDIA NeMo Guardrails[47:4] 允许开发者为 LLM 应用定义安全策略,控制模型如何响应用户 Prompt,过滤潜在有害或不当的输入/输出。
- 智能水印/数字签名:验证AI生成内容的来源和完整性,对抗深伪。 为了对抗深伪和虚假信息,可以在 AI 生成的内容(图像、视频、文本、音频)中嵌入不可感知或难以移除的水印(智能水印)或使用数字签名,以证明内容的来源和完整性[1:111]。这有助于接收者验证内容的真实性,区分真实内容与 AI 合成内容。C2PA(内容来源与真实性联盟)等组织正在推动相关标准。
- 知识链框架:保证Agent知识库的可信度。 针对 RAG 系统知识库投毒的风险,可以构建知识链框架,记录知识库中信息的来源、修改历史和验证状态,确保 Agent 获取的信息是可信的[1:112]。例如,利用区块链或分布式账本技术来记录知识库内容的哈希值和修改历史,确保其完整性和不可篡改性。
- 深度伪造检测工具。 开发和部署能够自动化检测深度伪造内容(如换脸视频)的工具,利用机器学习技术分析视频帧中的异常伪影、不一致性或数字签名,以帮助区分真实内容与 AI 合成内容[1:113]。
- 工业级安全基准测试(如Google AI Safety Benchmark):涵盖大量安全测试场景。 建立和推广工业级的 AI 安全基准测试,如 Google 的 AI Safety Benchmark,包含大量预定义的对抗性测试场景,用于量化评估 AI 模型的安全能力[1:114]。例如,该基准可能包含数万个 Prompt Injection 变体、对抗性图像样本等,用于全面测试模型的鲁棒性和安全性。这有助于提升 AI 产品的整体安全水平。
- AI安全评估平台(AIcert):理论验证、安全开发、多维分析。 专业的 AI 安全评估平台(如 AIcert)提供从理论验证到安全开发流程、再到模型多维分析的综合能力,帮助企业系统性地评估 AI 系统的安全性[3:2]。这些平台可以整合多种安全工具和测试方法,提供一站式的 AI 安全评估服务。
- AI驱动的软件供应链安全分析平台(VackSCA):基于AI的二进制代码相似性比较。 利用 AI 技术分析软件供应链中的组件安全,例如 VackSCA 平台利用 AI 进行二进制代码相似性比较,无需源代码即可检测软件漏洞,有助于发现开源组件或第三方库中的隐藏风险[3:3]。这对于保护 AI 训练和部署所依赖的底层软件基础设施至关重要。
6.3. 未来趋势与研究方向
人工智能安全是一个快速演进的领域,未来的研究和实践将聚焦以下几个关键趋势:
- MLSecOps 体系的成熟与普及: 实现开发运维与 AI 安全治理的深度融合仍然面临跨部门协作、工具链整合和标准化等挑战[^1, ^10]。未来的趋势是将 MLSecOps 建设成为 AI 开发组织的标配流程,并形成更加成熟的框架和自动化工具,覆盖从数据到模型到应用的完整生命周期。
- 运行时 AI 安全: AI 模型的非确定性[1:115]和动态性使得静态安全措施不足。推理阶段的实时保护、监控和威胁响应将变得更加重要[^1, ^2]。需要开发能够在模型运行时检测和阻止攻击(如提示词注入、对抗攻击)的技术,例如基于行为分析的运行时监控和动态护栏。
- 零信任架构在 AI 系统集成中的应用: 随着 AI 系统与企业内外部系统深度集成,需要采用零信任架构,不信任任何用户或系统,所有交互都需经过严格认证和授权,确保只有经过验证的用户和工作流才能与 AI 系统交互[24:48]。将零信任原则应用于 AI 数据访问、模型调用、Agent 交互等场景。
- Agent 安全与多模态模型安全: 随着 Agent 和多模态 AI 模型(处理文本、图像、音频等多种数据)的普及,针对这些新兴 AI 范式的特定安全威胁和防御技术将成为研究重点[1:116]。例如,如何评估和控制多模态模型的潜在风险,如何确保 Agent 在复杂环境中的安全行为和决策。
- AI 安全标准的制定与落地: 全球范围内 AI 安全标准的制定和推广将加速,为行业提供明确的指导[^1, ^5]。如何将这些标准有效地落地到企业的 AI 开发和运营实践中是关键,需要更多的实践案例和工具支持。
- 跨领域人才培养(ML 工程师 + 安全专家): 弥合机器学习和网络安全领域的知识鸿沟,培养具备 AI 和安全双重技能的复合型人才至关重要[24:49]。这需要教育机构和企业共同努力,提供交叉学科的课程和培训。
- 应对 LLM 非确定性带来的安全挑战: 大型语言模型的非确定性输出增加了安全防护的难度[1:117]。如何建立可靠的护栏和验证机制,确保模型输出的安全性,是未来的重要研究方向。
- 常态化、多元协同的 AI 风险监测与应急机制: 建立国家、行业、企业层面的常态化 AI 风险监测体系,搜集和分析最新的 AI 威胁情报。构建多方参与(包括政府、企业、研究机构、社会组织)的多元协同应急响应机制,共同应对大规模 AI 安全事件[1:118]。
7. 结论
人工智能的飞速发展为人类社会带来了前所未有的机遇,但伴随而来的是贯穿其整个生命周期的复杂而严峻的安全挑战。从预训练阶段的数据投毒、模型窃取、算法对抗,到部署阶段的基础设施“裸奔”与云端 API 漏洞,再到 AI 应用特别是 Agent 面临的新兴威胁,这些风险不仅影响 AI 系统的可靠性与可用性,更可能侵犯隐私、加剧偏见、引发伦理困境,甚至对国家安全构成威胁。传统孤立的安全措施已不足以应对 AI 特有的风险特性和复杂性。
将 DevSecOps 的理念与自动化实践深度融入 AI 生命周期治理,形成 MLSecOps 框架,是当前应对这些挑战的有效路径。它强调安全左移,在数据准备和模型设计阶段就植入安全基因;强调自动化,将安全检测、测试、防护集成到 CI/CD 流水线;强调持续监控,对 AI 系统行为进行实时监测与响应;强调协作文化,打破团队壁垒。借助自动化工具链(包括 AI 特有的红队工具、模型安全扫描器、AI 防火墙等)和高级防御策略(如 Confidential AI、智能水印),MLSecOps 能够有效地提升 AI 系统的安全韧性。
然而,AI 安全治理并非仅是技术工程,它深刻地置身于全球监管、伦理道德和地缘政治的宏大背景之下。理解欧盟、美国、中国等主要经济体不同的 AI 监管路径和 AIGC 标识要求,正视 AI 带来的算法偏见、隐私侵犯、虚假信息等伦理和社会挑战,以及应对 AI 作为战略技术引发的地缘政治博弈,都是构建鲁棒 AI 安全体系不可或缺的组成部分。
未来的 AI 安全之路,将是一场持续的技术对抗、治理模式创新与社会价值适应的复杂进程。构建一个安全可信的人工智能生态体系,需要技术创新(发展更先进的防御技术、AI 驱动的安全工具)、管理优化(深化 MLSecOps 实践、建立标准化的治理流程)、法规完善与伦理约束、以及国际社会在构建全球治理框架上的共同努力。这不仅是技术界的任务,更是全社会需要共同面对和解决的时代命题。通过持续的研究、审慎的治理和负责任的应用,我们才能充分释放 AI 的巨大潜力,同时有效管控其带来的风险,最终实现人机和谐共存的智能未来。
8. 参考文献
贡献者
 pansin
pansin文件历史
Artificial Intelligence Lifecycle Security Risk And DevsecOps Governance Framework Analysis.md (分析结论) ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
search 预训练模型数据投毒风险.md (搜索结果) ↩︎
奇安信. (2024, October 29). 政务大模型安全治理框架. 奇安信威胁情报中心. https://www.qianxin.com/threat/reportdetail?report_id=323 ↩︎ ↩︎ ↩︎
Meng, W., et al. (2025). R.R.: Unveiling LLM Training Privacy through Recollection and Ranking. arXiv:2502.12658v1. https://arxiv.org/html/2502.12658v1 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Zhang, Y., et al. (2025). Mitigating Sensitive Information Leakage in LLMs4Code through Machine Unlearning. ResearchGate. https://www.researchgate.net/publication/388884096_Mitigating_Sensitive_Information_Leakage_in_LLMs4Code_through_Machine_Unlearning/fulltext/67ab6a5c207c0c20fa84a284/Mitigating-Sensitive-Information-Leakage-in-LLMs4Code-through-Machine-Unlearning.pdf ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Zhao, Z., et al. (2024). Confidential Prompting with Cloud Virtual Machines. arXiv:2409.19134v3. https://arxiv.org/html/2409.19134v3 ↩︎ ↩︎ ↩︎ ↩︎
Cohen, G., & Nissim, N. (2025). Zero-Trust Artificial Intelligence Model Security Based on Moving Target Defense and Content Disarm and Reconstruction. arXiv:2503.01758. https://arxiv.org/pdf/2503.01758 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Ding, Z., et al. (2025). A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories. https://arxiv.org/html/2505.01067v1 ↩︎ ↩︎ ↩︎ ↩︎
García Veytia, A. (2024, March 14). Securing the AI/ML model supply chain: Where's the data?. Stacklok Blog. https://stacklok.com/blog/ai-sbom-wheres-the-data ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Diaz-Pinto, A., et al. (2025). Detecting Dataset Bias in Medical AI: A Generalized and Modality-Agnostic Auditing Framework. arXiv:2503.09969. https://arxiv.org/html/2503.09969 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Bartal, A., et al. (2024). A Review of Fairness and A Practical Guide to Selecting Context-Appropriate Fairness Metrics in Machine Learning. ResearchGate. https://www.researchgate.net/publication/385721402_A_Review_of_Fairness_and_A_Practical_Guide_to_Selecting_Context-Appropriate_Fairness_Metrics_in_Machine_Learning ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Alashaikh, A., et al. (2025). Bias-Aware Agent: Enhancing Fairness in AI-Driven Knowledge Retrieval. arXiv:2503.21237. https://arxiv.org/html/2503.21237 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Xiang, Z., et al. (2025). RAGForensics: Tracing Back Poisoned Texts in Poisoning Attacks to RAG. arXiv:2504.21668v1. https://arxiv.org/html/2504.21668v1 ↩︎
OWASP. (2025). LLM04:2025 Data and Model Poisoning. OWASP GenAI Project. https://genai.owasp.org/llmrisk/llm042025-data-and-model-poisoning/ ↩︎
Papadaki, M., et al. (2025). Differentially Private Next-Token Prediction of Large Language Models. arXiv:2403.15638v1. https://arxiv.org/html/2403.15638v1 ↩︎ ↩︎ ↩︎ ↩︎
Liu, Y., et al. (2025). Privacy-Preserving Large Language Models: Mechanisms, Applications, and Future Directions. arXiv:2412.06113v1. https://arxiv.org/html/2412.06113v1 ↩︎ ↩︎ ↩︎
Bu, Z., et al. (2025). Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models. arXiv:2502.13313v1. https://arxiv.org/html/2502.13313v1 ↩︎ ↩︎
Jagielski, M., et al. (2023). Privacy Issues in Large Language Models: A Survey. arXiv:2312.06717v2. https://arxiv.org/html/2312.06717v2 ↩︎
Cloudflare. (2025). What are the OWASP Top 10 risks for LLMs?. Cloudflare Learning Center. https://www.cloudflare.com/learning/ai/owasp-top-10-risks-for-llms/ ↩︎ ↩︎
Kim, M., et al. (2024). Enhancing SBOM Management: A Secure Framework for Distribution and Storage. arXiv:2412.05138v2. https://arxiv.org/html/2412.05138v2 ↩︎
Mitigating AI cybersecurity risks with Bug Bounty Programs - YesWeHack. https://www.yeswehack.com/security-best-practices/ai-cybersecurity-risks-bug-bounty ↩︎
search 训练算法对抗攻击与模型窃取.md (搜索结果) ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Understanding and Preventing AI Model Theft: Strategies for Enterprise | NeuralTrust. https://neuraltrust.ai/blog/understanding-and-preventing-ai-model-tealing-strategies-for-enterprises ↩︎ ↩︎
中兴通讯亮相 2025 中国移动云智算大会全栈智算赋能AI普惠 - ZTE. https://www.zte.com.cn/china/about/news/20250409c1.html ↩︎
Announcing the SafeBench Winners - ML Safety. https://www.mlsafety.org/safebench/winners ↩︎ ↩︎ ↩︎
Alsadhan, A., et al. (2025). A Selective Homomorphic Encryption Approach for Faster Privacy-Preserving Federated Learning. arXiv:2501.12911v1. https://arxiv.org/html/2501.12911v1 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Liu, Y., et al. (2025). Federated Fine-Tuning of LLMs: Framework Comparison and Research Directions. arXiv:2501.04436v1. https://arxiv.org/html/2501.04436v1 ↩︎ ↩︎
Li, B., et al. (2025). DropPEFT: A Dropout-based Parameter-Efficient Fine-Tuning Method for Federated Large Language Models. arXiv:2503.10217v1. https://arxiv.org/html/2503.10217v1 ↩︎
Zhang, Z., et al. (2025). Layer-Skipping Federated Learning for Large Language Models. arXiv:2504.10536v1. https://arxiv.org/html/2504.10536v1 ↩︎
Zhang, J., et al. (2024). Federated Learning for Large Language Models: A Survey on Architecture, Challenges, and Opportunities. arXiv:2406.09831v2. https://arxiv.org/html/2406.09831v2 ↩︎
Li, Z., et al. (2024). Privacy-Preserving Machine Learning: A Comprehensive Survey on Techniques and Applications. arXiv:2403.03592. https://arxiv.org/pdf/2403.03592 ↩︎
Liu, X., et al. (2025). Privacy-Preserving Large Language Models: A Survey. arXiv:2505.17145v1. https://arxiv.org/html/2505.17145v1 ↩︎
Infrastructure Security 101: An Introduction - Splunk. https://www.splunk.com/en_us/blog/learn/infrastructure-security.html ↩︎ ↩︎ ↩︎ ↩︎
Security considerations when hosting AI models on GPU servers - Liquid Web. https://www.liquidweb.com/gpu/ai-security/ ↩︎ ↩︎
Securing GenAI Workloads: Protecting the Future of AI in Containers - Cloud Native Now. https://cloudnativenow.com/topics/containers/securing-genai-workloads-protecting-the-future-of-ai-in-containers/ ↩︎ ↩︎
OWASP API Security Project. https://owasp.org/www-project-api-security/ ↩︎
LLM Prompt Injection Prevention - OWASP Cheat Sheet Series. https://cheatsheetseries.owasp.org/cheatsheets/LLM_Prompt_Injection_Prevention_Cheat_Sheet.html ↩︎ ↩︎
Google Workspace security whitepaper. https://workspace.google.com/learn-more/security/security-whitepaper/page-1/ ↩︎
AI安全态势管理 - 阿里云文档. https://help.aliyun.com/zh/security-center/user-guide/ai-protection ↩︎ ↩︎
Prompt Injection attack against LLM-integrated Applications - arXiv. https://arxiv.org/html/2306.05499v2 ↩︎
Mitigating the Privacy Issues in Retrieval-Augmented Generation (RAG) via Pure Synthetic Data - arXiv. https://arxiv.org/html/2406.14773v2 ↩︎ ↩︎ ↩︎ ↩︎
arxiv.org, accessed May 29, 2025. https://arxiv.org/html/2505.08728 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
search 人工智能安全工具链对比分析.md (搜索结果) ↩︎
30 Best Tools for Red Teaming: Mitigating Bias, AI Vulnerabilities & More - Mindgard. https://mindgard.ai/blog/best-tools-for-red-teaming ↩︎
MLSecOps: Top 20+ Open Source and Commercial Tools - Research AIMultiple. https://research.aimultiple.com/mlsecops/ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
OAuth 2.0 Security Best Practices for Developers - Kim Maida. https://maida.kim/oauth2-best-practices-for-developers/ ↩︎
CrowdStrike Research: Securing AI-Generated Code with Multiple Self-Learning AI Agents. https://www.crowdstrike.com/en-us/blog/secure-ai-generated-code-with-multiple-self-learning-ai-agents/ ↩︎
The Ultimate Guide to Infrastructure as Code (IAC) Security - Checkmarx. https://checkmarx.com/learn/iac-security/the-ultimate-guide-to-infrastructure-as-code-iac-security/ ↩︎
JFrog Becomes an AI System of Record, Launches JFrog ML – Industry's First End-to-End DevOps, DevSecOps & MLOps Platform for Trusted AI Delivery. https://investors.jfrog.com/news/news-details/2025/JFrog-Becomes-an-AI-System-of-Record-Launches-JFrog-ML--Industrys-First-End-to-End-DevOps-DevSecOps--MLOps-Platform-for-Trusted-AI-Delivery/default.aspx ↩︎
www.tc260.org.cn, accessed May 29, 2025. https://www.tc260.org.cn/file/2024-04-01/94e7e6de-2688-472c-af8b-a6cfe7fc7d29.pdf ↩︎ ↩︎
News - 腾讯AI Lab - 腾讯人工智能实验室官网. https://ailab.tencent.com/ailab/en/news/ ↩︎
阿里巴巴人工智能治理与可持续发展实验室(AAIG). https://s.alibaba.com/cn/aaig ↩︎